本記事は Siv3D – Qiita Advent Calendar 2025 – Qiita https://qiita.com/advent-calendar/2025/siv3d の 3日目の記事です。
ChatGPTが一般的に使われ始めて2年ほど経ち、今度は AI エージェントというのが今年の4月頃から流行りはじめました。ChatGPT を使って、プログラミングのコードを教えて教えて貰うのはいいのですが、いちいちコードをコピペしないとイケなかったり、そもそも大量のコードをを ChatGPT に貼り付けないと文脈をうまく読み取ってくれないという問題がありました。が、これを Visual Studio Code 上なので直接ファイルを弄ってくれるのが AI エージェントの役割です。ちょっと危険な気もする(まあ、実際のところ MCP あたりが暴走すると危険なんですが)けれども、うまく使いこなせればこその「道具」なので、その道具を使いこなしていきましょう、というのがこの記事の主旨です。
バイブコーディング(vibe coding)とは?
ChatGPT にちまちまと関数のコードを貼り付けていたのととは違って、生成 AI を使って一気にコードを作成してしまおうというのが「バイブコーディング」の主な特徴です。いわゆる、AI にコードを書かせてしまって、コードを書く楽しみが…とも言えるのですが、職業プログラマとしては、
- テストツールなどのたいくつなツールは AI に書かせた方が早い
- 使い捨てツール=治具などは、AI に書かせたほうが早い
- 最初のひな形は、AI にやってもらってたたき台にすることができる
という形で、使い捨てであったり最初のアイデアを実現するツールにバイブコーディングを使うのが一番効果的です。その後で、実際に仕事に使う場合にはコードの検証やら正確性やらが必要になってくるので、AI コードそのままを使うことはできませんが、それでも私自身の場合は、
- 複雑怪奇になってしまったコードの解析を AI に頼む
- 長々と出てくるエラーコードの解析を AI に頼む
- ちょっと古めのコードを AI に読んで貰って、修正点のアイデアを出して貰う
のようなことをやります。最近は AI 任せにするツールや手法が盛んではありますが、その一歩手前の「AIペアプロ」がお勧めです。まあ、慣れてきたら、設計書を書くなりして一晩ぐるぐる回すほうが効果的ではあるのですが、慣れないうちはちまちま設計用の Readme.md や Agents.md(ファイル名は実は何でも構いません)に書いておいて、AI にちょっと作って貰うというのを繰り返すのがよいでしょう。自分なりのコーディングスタイルを掴んでください。
C++ でバイブコーディングできるのか?
巷に公開されているものは React などの Node.js や TypeScript を使った Web 開発のものが多いでしょう。設計書ノウハウ(「仕様書駆動」や「sepc駆動」というやつです)も、そのあたりのものが多いです。Web 開発の場合、コードを修正した途端に UI が変更になるとか、npm を使うとかするパターンが多いので、果たして C++ のように間にコンパイルが挟む場合はどうなるのか? という不安はありますが、大丈夫です。C++ でも十分使えます。しかも、Siv3D のような独自なライブラリを使っている場合でも、最近の生成 AI はうまく扱ってくれます。おそらく、Siv3D のチュートリアルサイト https://siv3d.github.io/ja-jp/ があるのが大きいと思います。つまり、Web サイトにある情報をうまく学習しているのが、現在の AI エージェントのモデルになっているわけです。
また、AI エージェントによるプログラム言語のコンバートの能力も上がっています。ロジックに関しては、一般的なプログラム言語はかなり網羅されています。別件ではありますが、Python のコードを VB.NET のコードに変換することもできます。あるいは、Kotlin や Swift のコードに変換したりします。それぞれデータベースなどライブラリの使い方は異なるのですが、それもプログラム言語特有のもの、かつ、そのプログラム言語で使われているライブラリをうまく使って変換してくれます。
Siv3Dでバイブコーディングしてみる
まあ、ここまで長々と書いてようやく Siv3D のコーディングに辿り着くわけですが、あまりやることがないので、ちょっと長々と書いてしまっているだけです。
AI エージェントでは、Visual Studio Code + Claude Sonnet を使っています。GitHub Copilot ならば月10ドルで契約が可能です。学生ならば 0 円で利用ができます。他にも結構高めなものもありますが、夜中にぐるぐる回さない限りこれで十分です。Google の Gemini のほうは分からないのですが、どの AI エージェントを使ってもだいたい似た感じでいけます。好きなものを使ってください。
AI エージェントによっては、プロジェクトを自動作成するところからできるパターンも多いのですが、このように Visual Studio を使ってプロジェクトテンプレートを使ってひな形のプロジェクトだけ作っておくとよいです。ビルドも自動化できるのですが、結構面倒なので、AI ペアプロとしてビルドは人間のほうの担当にします。
仕事としてはファイルを分けたほうがいいのですが、今回は面倒なので Main.cpp に全てを突っ込みます。この初期状態でビルドができるところまで確認しておきます。
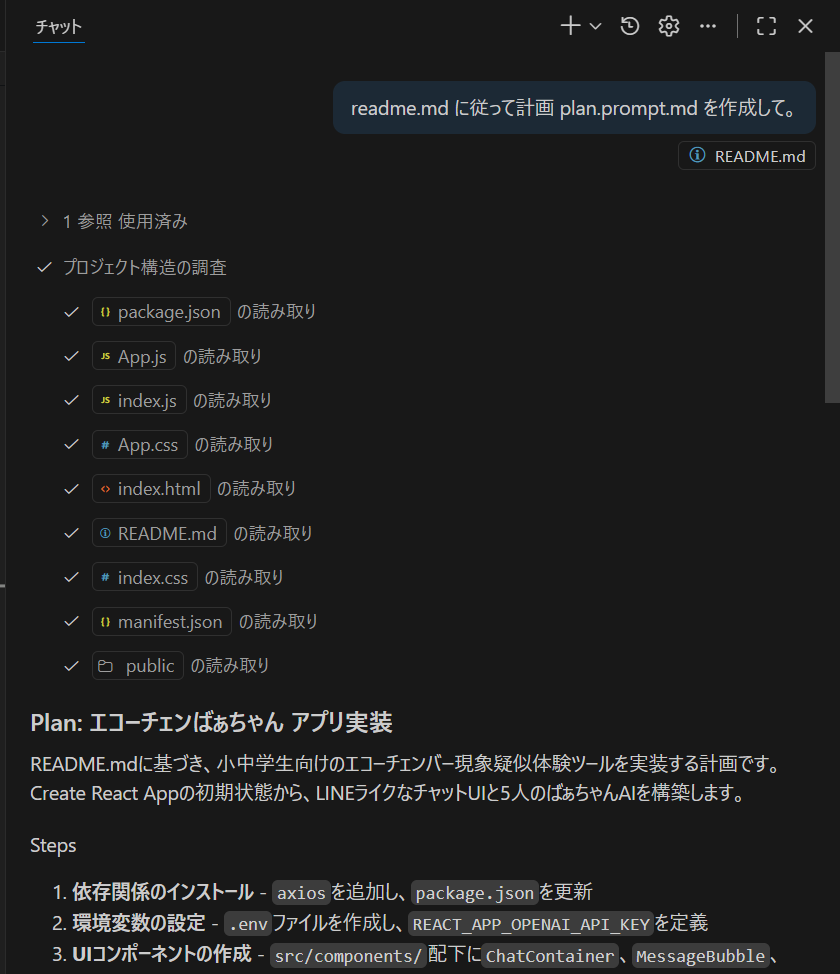
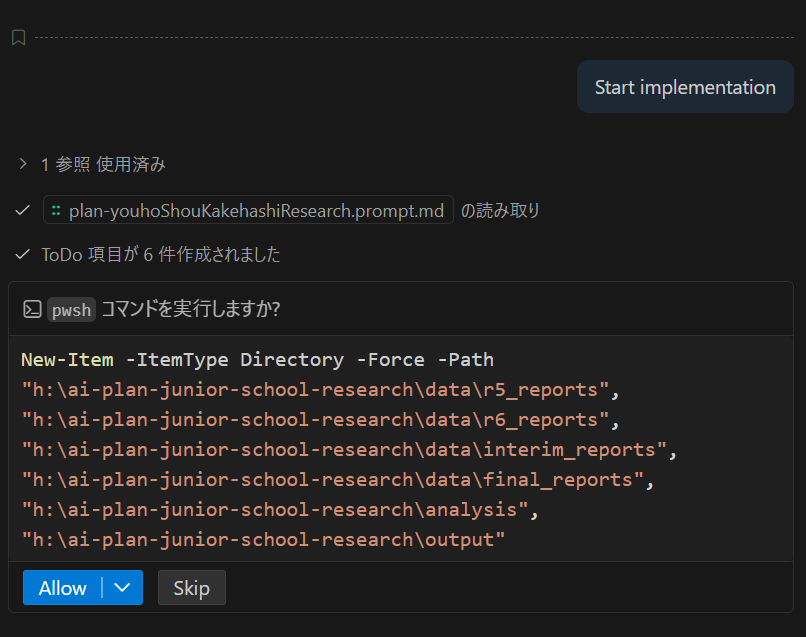
agents.md を作成する
実はファイル名は Agents.md でも Readme.md でも Claudes.md でもなんでも構いません。夜中に自動化しようとすると、ファイル名を決めたほうがうまく AI エージェントに伝わるのですが、AI ペアプロの場合には「agents.md に従ってコードを作成して」とプロンプトで伝えるだけで十分です。ファイル名を頼りにうまく探してくれます。
agents.md の中身は以下のようになっています。
# ウマ娘レース
## 概要
ウマ娘レースは、ウマ娘たちが競い合うレースイベントです。
プレイヤーは、ウマ娘のパラメータを調節してトップを目指します。
## ルール
- レースは、横一列に並んだ5人のウマ娘で行なわれる
- 各ウマ娘には、スピード、スタミナ、パワー、根性、賢さの5つのパラメータがある
- プレイヤーは、自分のウマ娘のパラメータを調整してレースに挑む
- レースは複数のターンで構成され、各ターンでウマ娘たちは前進する
- 最終的にゴールに最も早く到達したウマ娘が勝者となる
## パラメータの説明
- スピード: ウマ娘の基本的な速さを決定するパラメータ
- スタミナ: ウマ娘が長距離を走る際の持久力を決定するパラメータ
- パワー: ウマ娘の加速力や坂道での強さを決定するパラメータ
- 根性: ウマ娘が苦しい状況でも踏ん張る力を決定するパラメータ
- 賢さ: ウマ娘がレース中に適切な判断を下す能力を決定するパラメータ
パラメータは、合計 20 ポイントまで振り分けることができる。
## レースの進行
- 各ターンでウマ娘たちは、パラメータに基づいて前進距離が決定される
サイコロ 1から6までのサイコロを2個振る。
前進距離 =
スピード * サイコロA +
スタミナ * サイコロB +
パワー * (サイコロA + サイコロB) / 2 +
根性 * ランダム値(3から6) +
賢さ * ランダム値(1から3)
各ウマ娘は順番サイコロを振り、出た目の大きい順に前進距離を計算していく。
最初に 1000 メートルに到達したウマ娘が勝者となる。
## 画面構成
- レーストラック: ウマ娘たちが走るコースが表示される。横長の一列でよい。
- 自分のウマ娘のパラメータを入れる
- 他のウマ娘のパラメータはランダムに設定される
- スタートボタンを押すと、レースが開始される。1秒毎に順番サイコロを振る。
## 設計
// ウマ娘の構造体
struct UmaMusume {
name: String,
speed: u8,
stamina: u8,
power: u8,
guts: u8,
wisdom: u8,
position: u32,
};
// レースの構造体
struct Race {
uma_musumes: Vec<UmaMusume>,
track_length: u32
};
これも慣れるとここまで書けるのですが、慣れないうちはそんなに細かく書かなくてもいいです。はっきり言って、概要とルールだけ書いても、このウマ娘レースは作成されてしまいます。どうやら、この手のゲームロジック(ブロック崩しとかインベーダーゲームとか)は生成 AI の学習データにあるっぽくて、それらしい何処かで見たようなものをうまく出してくれます。まあ、端的に言えばパクりなのですが、ここでは目をつぶっておきましょう。私的範囲内の利用ということです。
AI にコーディングしてもらう。
プロンプトで「agents.md に従ってコーディングして」と頼むだけです。AI エージェントのほうもだんだん賢くなっているので、結構なスピードでコードを生成してくれます。
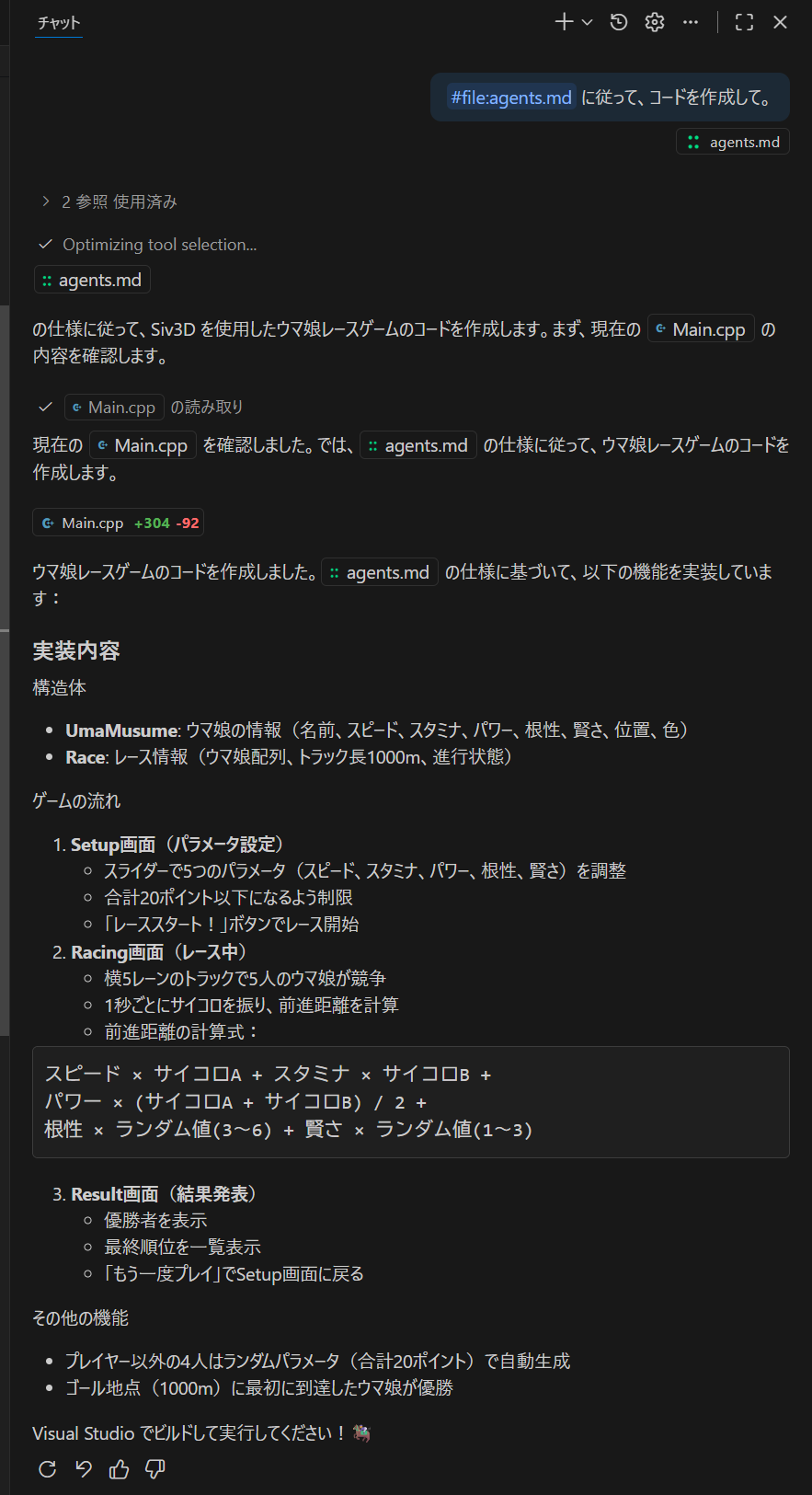
見てわかるのですが、
- パラメータを入れるためのセットアップ画面
- レース中の画面
- 結果を表示する画面
の3つに分かれています。この要素は agents.md に入れていないので、つまりはこれはどこからからパクって来たものです。こんな風に典型的な画面の作りの場合には AI エージェントが一番効率的に動きます。逆に、この3つの画面を、うまくひとつの画面に落とし込むのはなかなか苦労します。独自画面は苦手なんですよね。
そのような場合は、あらかじめコードのほうに、1画面の配置をコーディングしてしまうとうまくいきます。agents.md にあれこれと画面構成を記述する方法も可能なのですが、AI エージェント自身が既存のコードを解析しながら、そこに付け加えるように進めていくのでコード自身で伝えるほうが効果的です。
逆に、うまくコードで伝わらないときは、agents.md を作り直して一からバイブコーディングをしてしてみてください。バイブコーディングの良いところは、うまくいかなかった時はすべてを捨ててやり直しができるところです。これが人間がコーディングをすると、手間がかかっていたり再利用を考えたりするところなのですが、バイブコーディングの場合はコーディングの作成時間が短い&人間の労力が少ないので、最初からやり直してしまったほうが早いです。同じ agents.md であっても、確率的に別な構造になるので、何度かやってうまくいったものを利用する手があります。
もっとも、数行のプロンプトだけでうまくいくまで AI に書いて貰うという学校の課題方式ではだめです。ちょっとずつ agents.md を書き変えて、うまくパターンをみつけるのが人間の仕事になります。
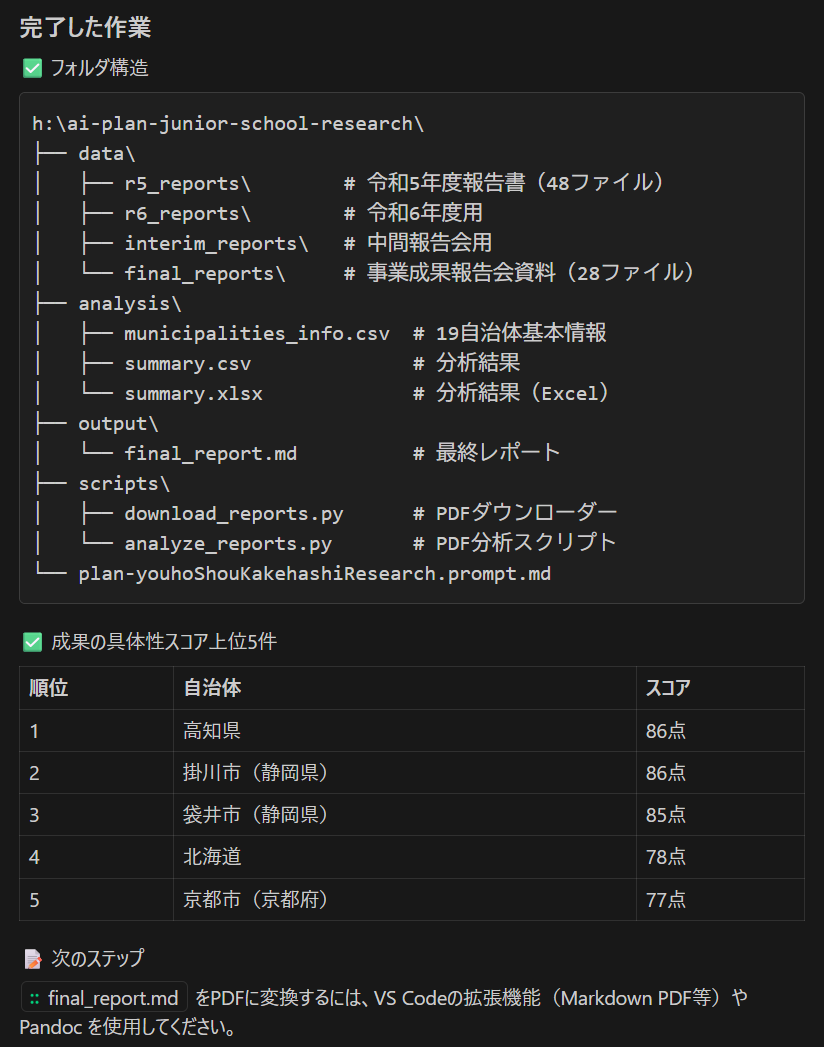
できあがった Main.cpp
しばらく待つと Main.cpp ができあがります。
# include <Siv3D.hpp> // Siv3D v0.6.16
// ウマ娘の構造体
struct UmaMusume
{
String name;
int32 speed;
int32 stamina;
int32 power;
int32 guts;
int32 wisdom;
int32 position;
Color color;
// パラメータの合計を計算
int32 totalParams() const
{
return speed + stamina + power + guts + wisdom;
}
// 前進距離を計算
int32 calculateAdvance() const
{
int32 diceA = Random(1, 6);
int32 diceB = Random(1, 6);
int32 gutsRandom = Random(3, 6);
int32 wisdomRandom = Random(1, 3);
int32 advance = speed * diceA
+ stamina * diceB
+ power * (diceA + diceB) / 2
+ guts * gutsRandom
+ wisdom * wisdomRandom;
return advance;
}
};
// レースの構造体
struct Race
{
Array<UmaMusume> umaMusumes;
int32 trackLength = 1000;
bool isRunning = false;
bool isFinished = false;
int32 winnerIndex = -1;
Stopwatch turnTimer;
// ランダムなパラメータを生成(合計20ポイント)
static UmaMusume createRandomUma(const String& name, const Color& color)
{
UmaMusume uma;
uma.name = name;
uma.color = color;
uma.position = 0;
// ランダムに20ポイントを振り分け
Array<int32> params = { 1, 1, 1, 1, 1 }; // 最低1ずつ
int32 remaining = 15; // 残り15ポイント
for (int32 i = 0; i < remaining; ++i)
{
int32 idx = Random(0, 4);
params[idx]++;
}
uma.speed = params[0];
uma.stamina = params[1];
uma.power = params[2];
uma.guts = params[3];
uma.wisdom = params[4];
return uma;
}
// レースを1ターン進める
void advanceTurn()
{
if (isFinished) return;
// 各ウマ娘の前進距離を計算
Array<std::pair<int32, int32>> advances; // (前進距離, インデックス)
for (size_t i = 0; i < umaMusumes.size(); ++i)
{
advances.push_back({ umaMusumes[i].calculateAdvance(), static_cast<int32>(i) });
}
// 前進距離の大きい順にソート
std::sort(advances.begin(), advances.end(), [](const auto& a, const auto& b) {
return a.first > b.first;
});
// 順番に前進
for (const auto& [advance, idx] : advances)
{
umaMusumes[idx].position += advance;
// ゴール判定
if (umaMusumes[idx].position >= trackLength && !isFinished)
{
isFinished = true;
winnerIndex = idx;
isRunning = false;
}
}
}
};
void Main()
{
// ウィンドウサイズを設定
Window::Resize(1200, 700);
Scene::SetBackground(ColorF{ 0.3, 0.6, 0.3 });
// フォントを作成
const Font font{ FontMethod::MSDF, 48, Typeface::Bold };
const Font smallFont{ FontMethod::MSDF, 32 };
// ウマ娘の絵文字
const Texture umaEmoji{ U"🏇"_emoji };
// ウマ娘の名前と色
const Array<String> umaNames = { U"プレイヤー", U"スペシャル", U"サイレンス", U"トウカイ", U"マチカネ" };
const Array<Color> umaColors = { Palette::Red, Palette::Blue, Palette::Green, Palette::Orange, Palette::Purple };
// レース
Race race;
// プレイヤーのパラメータ
double playerSpeed = 4;
double playerStamina = 4;
double playerPower = 4;
double playerGuts = 4;
double playerWisdom = 4;
// ゲーム状態
enum class GameState { Setup, Racing, Result };
GameState state = GameState::Setup;
while (System::Update())
{
// タイトル表示
font(U"🏇 ウマ娘レース 🏇").drawAt(48, Vec2{ 600, 40 }, Palette::White);
if (state == GameState::Setup)
{
// パラメータ設定画面
font(U"パラメータを設定してください").drawAt(32, Vec2{ 600, 100 }, Palette::Yellow);
const int32 sliderX = 400;
const int32 sliderWidth = 200;
int32 y = 150;
// パラメータスライダー
SimpleGUI::Slider(U"スピード: {:.0f}"_fmt(playerSpeed), playerSpeed, 1.0, 10.0, Vec2{ sliderX, y }, 180, sliderWidth);
y += 50;
SimpleGUI::Slider(U"スタミナ: {:.0f}"_fmt(playerStamina), playerStamina, 1.0, 10.0, Vec2{ sliderX, y }, 180, sliderWidth);
y += 50;
SimpleGUI::Slider(U"パワー: {:.0f}"_fmt(playerPower), playerPower, 1.0, 10.0, Vec2{ sliderX, y }, 180, sliderWidth);
y += 50;
SimpleGUI::Slider(U"根性: {:.0f}"_fmt(playerGuts), playerGuts, 1.0, 10.0, Vec2{ sliderX, y }, 180, sliderWidth);
y += 50;
SimpleGUI::Slider(U"賢さ: {:.0f}"_fmt(playerWisdom), playerWisdom, 1.0, 10.0, Vec2{ sliderX, y }, 180, sliderWidth);
// 合計ポイント表示
int32 total = static_cast<int32>(playerSpeed) + static_cast<int32>(playerStamina)
+ static_cast<int32>(playerPower) + static_cast<int32>(playerGuts) + static_cast<int32>(playerWisdom);
Color totalColor = (total <= 20) ? Palette::Lime : Palette::Red;
font(U"合計: {} / 20 ポイント"_fmt(total)).drawAt(28, Vec2{ 600, 430 }, totalColor);
if (total > 20)
{
smallFont(U"※ 合計20ポイント以下にしてください").drawAt(24, Vec2{ 600, 470 }, Palette::Red);
}
// スタートボタン
if (SimpleGUI::Button(U"レーススタート!", Vec2{ 500, 520 }, 200, (total <= 20)))
{
// レースを初期化(代入ではなくメンバごとに再初期化)
race.umaMusumes.clear();
race.trackLength = 1000;
race.isRunning = false;
race.isFinished = false;
race.winnerIndex = -1;
race.turnTimer.restart(); // タイマーをリセットして再スタート(既存インスタンスを再利用)
// プレイヤーのウマ娘を作成
UmaMusume player;
player.name = umaNames[0];
player.color = umaColors[0];
player.speed = static_cast<int32>(playerSpeed);
player.stamina = static_cast<int32>(playerStamina);
player.power = static_cast<int32>(playerPower);
player.guts = static_cast<int32>(playerGuts);
player.wisdom = static_cast<int32>(playerWisdom);
player.position = 0;
race.umaMusumes.push_back(player);
// 他のウマ娘をランダムに作成
for (size_t i = 1; i < umaNames.size(); ++i)
{
race.umaMusumes.push_back(Race::createRandomUma(umaNames[i], umaColors[i]));
}
race.isRunning = true;
race.turnTimer.restart();
state = GameState::Racing;
}
// パラメータ説明
y = 580;
smallFont(U"スピード: 基本的な速さ | スタミナ: 持久力 | パワー: 加速力").draw(18, Vec2{ 200, y }, Palette::White);
smallFont(U"根性: 踏ん張る力 | 賢さ: 判断力").draw(18, Vec2{ 200, y + 30 }, Palette::White);
}
else if (state == GameState::Racing)
{
// レース画面
const int32 trackY = 200;
const int32 trackHeight = 80;
const int32 trackStartX = 100;
const int32 trackWidth = 1000;
// トラック背景を描画
for (size_t i = 0; i < race.umaMusumes.size(); ++i)
{
int32 laneY = trackY + static_cast<int32>(i) * trackHeight;
// レーン背景
Rect{ trackStartX, laneY, trackWidth, trackHeight - 5 }
.draw(ColorF{ 0.8, 0.6, 0.4 })
.drawFrame(2, Palette::Brown);
// ゴールライン
Rect{ trackStartX + trackWidth - 10, laneY, 10, trackHeight - 5 }.draw(Palette::Red);
}
// 1秒ごとにターンを進める
if (race.isRunning && race.turnTimer.ms() >= 1000)
{
race.advanceTurn();
race.turnTimer.restart();
}
// ウマ娘を描画
for (size_t i = 0; i < race.umaMusumes.size(); ++i)
{
const auto& uma = race.umaMusumes[i];
int32 laneY = trackY + static_cast<int32>(i) * trackHeight;
// 位置を計算(トラック幅に合わせてスケーリング)
double progress = static_cast<double>(uma.position) / race.trackLength;
progress = Min(progress, 1.0);
int32 drawX = trackStartX + static_cast<int32>(progress * (trackWidth - 50));
// ウマ娘の絵文字を描画
umaEmoji.scaled(0.5).drawAt(drawX + 25, laneY + trackHeight / 2 - 2);
// 名前と位置を表示
smallFont(uma.name).draw(18, Vec2{ 10, laneY + 20 }, uma.color);
smallFont(U"{}m"_fmt(uma.position)).draw(16, Vec2{ 10, laneY + 45 }, Palette::White);
}
// レース情報
font(U"ゴール: {}m"_fmt(race.trackLength)).draw(24, Vec2{ 100, 620 }, Palette::White);
// レース終了判定
if (race.isFinished)
{
state = GameState::Result;
}
}
else if (state == GameState::Result)
{
// 結果画面
font(U"🎉 レース終了! 🎉").drawAt(48, Vec2{ 600, 150 }, Palette::Yellow);
if (race.winnerIndex >= 0)
{
const auto& winner = race.umaMusumes[race.winnerIndex];
font(U"優勝: {}"_fmt(winner.name)).drawAt(40, Vec2{ 600, 220 }, winner.color);
if (race.winnerIndex == 0)
{
font(U"おめでとうございます!").drawAt(32, Vec2{ 600, 280 }, Palette::Lime);
}
else
{
font(U"残念...次は勝てるかも!").drawAt(32, Vec2{ 600, 280 }, Palette::Orange);
}
}
// 順位表示
Array<std::pair<int32, size_t>> ranking;
for (size_t i = 0; i < race.umaMusumes.size(); ++i)
{
ranking.push_back({ race.umaMusumes[i].position, i });
}
std::sort(ranking.begin(), ranking.end(), [](const auto& a, const auto& b) {
return a.first > b.first;
});
int32 y = 340;
smallFont(U"【最終順位】").draw(24, Vec2{ 500, y }, Palette::White);
y += 40;
for (size_t rank = 0; rank < ranking.size(); ++rank)
{
const auto& uma = race.umaMusumes[ranking[rank].second];
smallFont(U"{}位: {} ({}m)"_fmt(rank + 1, uma.name, uma.position))
.draw(22, Vec2{ 480, y }, uma.color);
y += 35;
}
// リトライボタン
if (SimpleGUI::Button(U"もう一度プレイ", Vec2{ 500, 580 }, 200))
{
state = GameState::Setup;
}
}
}
}
実は、生成されるコードはビルドが通るとは限りません。今後の AI エージェントでは改善されると思いますが、文法的にちょっと間違っていたり、関数の整合性が合わないところがちょこちょこ出てきます。
このコードでは既に修正してありますが、スタートボタンを押したときの「// レースを初期化(代入ではなくメンバごとに再初期化)」の部分で、Race 構造体の初期化でコンパイルエラーがでていました。
race = Race{} ;
Race 構造体にデフォルトコンストラクタがないので、これでは駄目です。
race.umaMusumes.clear();
race.trackLength = 1000;
race.isRunning = false;
race.isFinished = false;
race.winnerIndex = -1;
race.turnTimer.restart(); // タイマーをリセットして再スタート(既存インスタンスを再利用)
まあ、他にも修正点はあるかもしれませんが、ひとまずビルドして動かしてみましょう。
動作確認
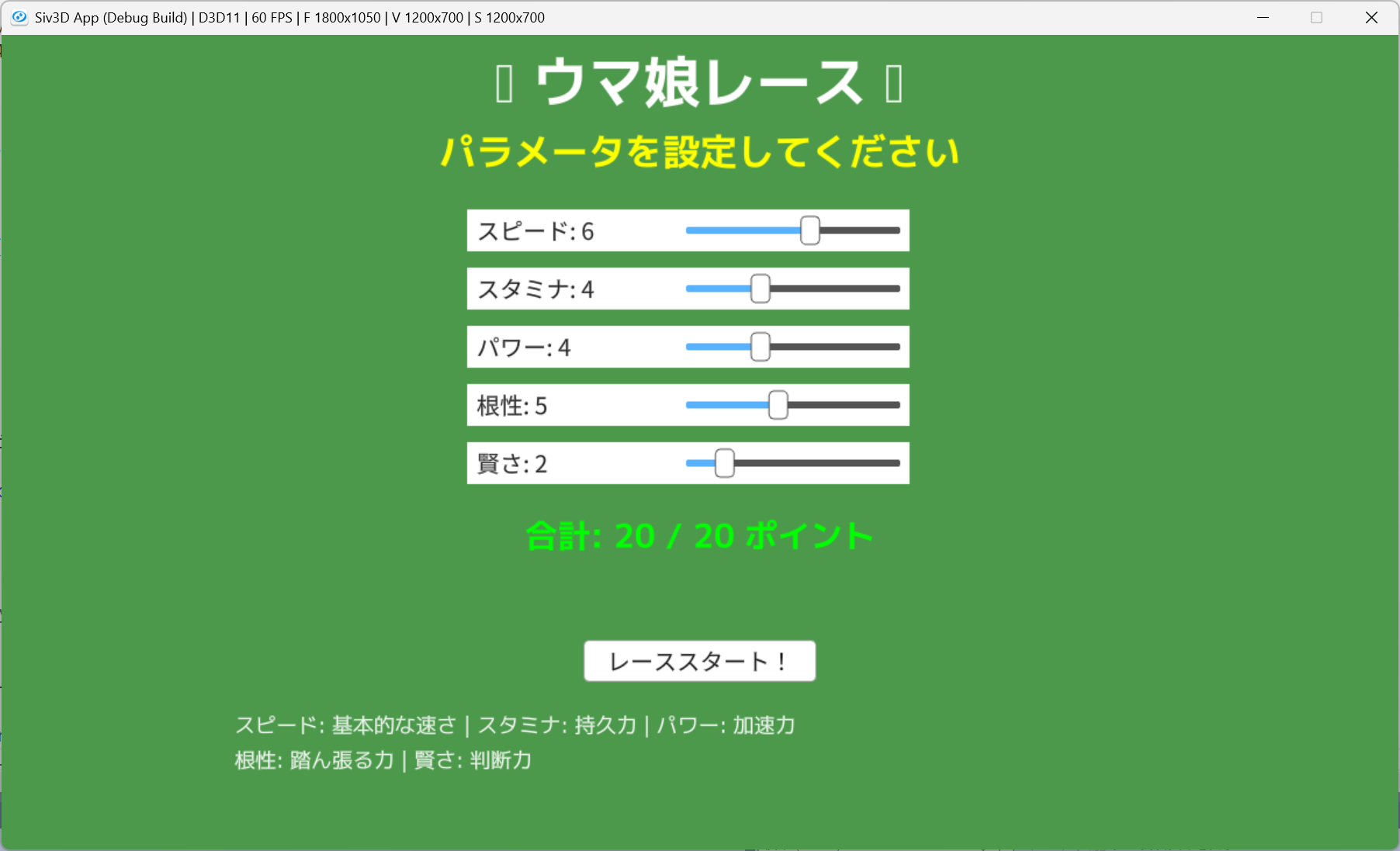
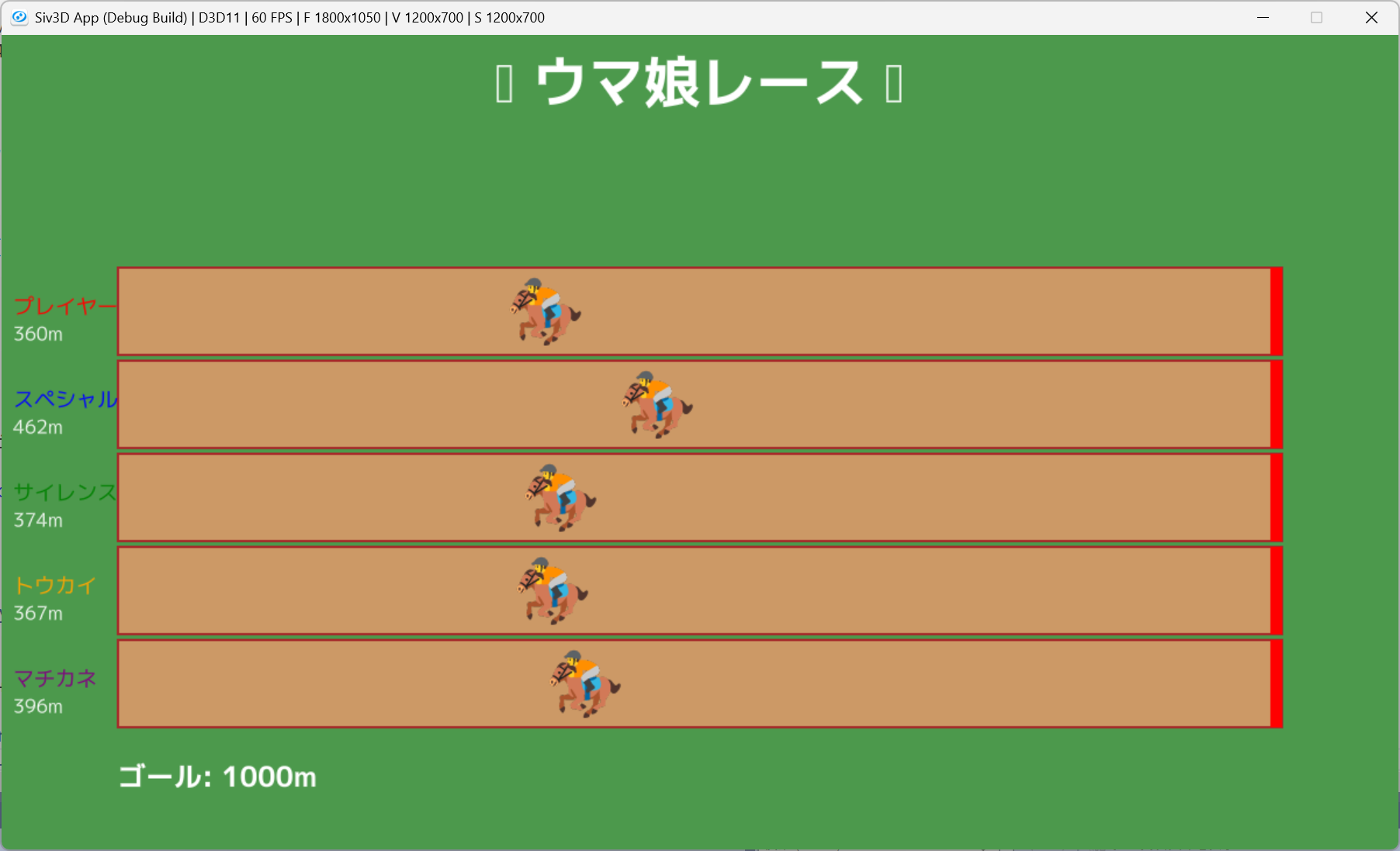
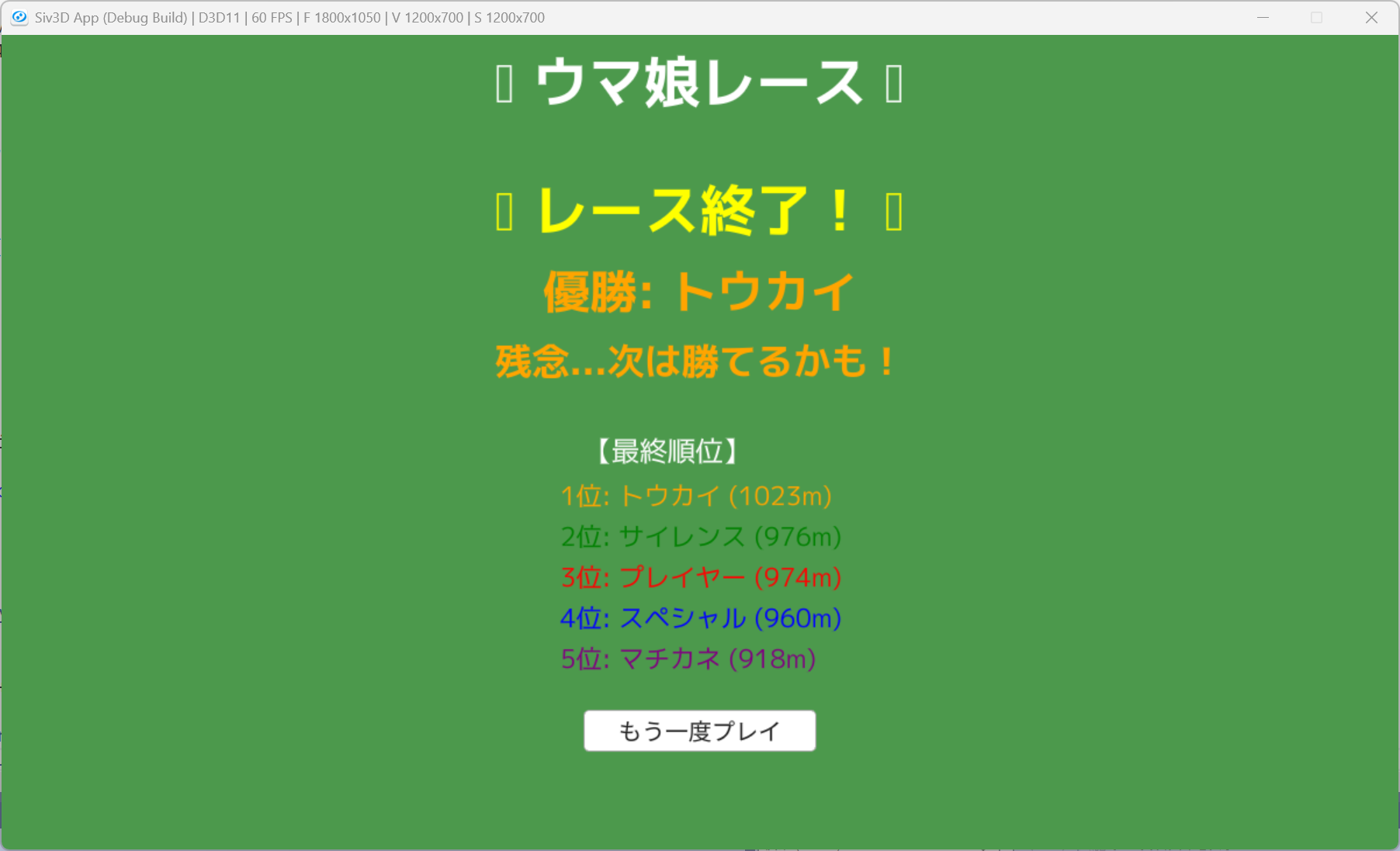
動かすと、馬が後ろ向きに走ってしまっているとか、パラメータを保存できないとか、ケース結果が蓄積されないとか、いろいろ改善点があります。
これは agents.md に書き込んで「この部分を修正して」とプロンプトに入れてもよいし、自分でコードを書き直してもよいです。コードのコメントに修正案を書いて、「この部分を実装して」でも AI がコードを作ってくれます。
では、AI ペアプロで、よい Siv3D プログラミングライフを!
サンプルコード
moonmile/siv3d_uma_race https://github.com/moonmile/siv3d_uma_race