
おそらく、過去にたくさんの記事が書かれているし「論理削除とは?」とかいうブログ記事も既にあるので、そちらの方を参考にしてもいいのですが、X/Twitter でたびたび炎上するのと、実際の開発現場でも議論が分かれるところなので、私なりの指針を示しておきます。
最初に断っておきますが、基本的に私は “削除フラグを作らない” 人です。古くから DB を設計してきた人にとって安易な is_deleted フラグの追加は結構な鬼門です。あと、90 年代からデータベースにさわっていると、データ量が多くなるという点で is_deleted フラグを使いません。削除できるデータは削除してしまってデータベースの容量を減らすほうに重きを置きます。
しかし、昨今のストレージ容量の多さや、データのアクセス性能の向上、コードファースト/ORM を利用した開発スタイルの普及により、論理削除を使う場面が多くなっています。
ゆえに、現在では「ある程度のフレームワーク/ORM を使った開発スタイルであれば、論理削除を使うことも良い」と考え直しています。
つまり、場合によりけり、ということなのですが、その「場合」とは一体なのか? ということですね。
- データ量の多さ、少なさ、100万件以上、それ以下
- サブクエリで参照されやすい、されない、深いところで参照される
- 削除される頻度は、極少、なし、頻繁、1/10 程度
- テーブル数は 100 個ぐらい、20 個以上
- フレームワークは、単一言語、複数種類で多言語
- データの時間性は、ある、なし
という視点があります。テーブル単位で逐一調べる、あるいは開発単位やフレームワークを基準にして考える必要があり、非常に面倒です。ええ、面倒なんですよ…これ。なので、単純に「論理削除をすべきかどうか?」という話ではない、ことに注意してください。
これを具体的に考察するために、具体的なユースケースを考えてみましょう。最近では AI エージェントを使ってコードを出力できるので結構短時間で実験ができます。いくつか手元の AI エージェントを使って自分の使っているプログラム言語&フレームワークで試してみてください。
ここでは、実例として、
- 自治体の住民検索、社会保険等
- 旅館の予約システム
- 工場の部品受注システム
- 回転寿司の受注システム
- 税務関係の社内経理システム、経費処理
- 社内のナレッジ管理、退職者の管理
を具体的に考えてみます。
コードの出力は以下で試してみます。
- PHP + Laravel + Eloquent ORM
- C# + LINQ + Entity Framework
- Java + Spring + Hibernate?(最近 Java を触れていないので…)
- Ruby + ActiveRecord
- Python + SQLAlchemy ? (これもよく知らない。勉強中)
- TypeScript + Node.js + Prisma ? (これもよく知らない。勉強中)
まずは削除の手法
最初にデータ削除の手法だけ紹介しておきます。
基本情報処理試験的には、DELETE してしまうのが「物理削除」、is_delete のようなフラグを使うのが「論理削除」と言いますが。これは基本的な知識として覚えておきます。
物理削除
DELETE FROM users WHERE user_id = 12345;
単純にデータを削除してしまう方法です。テーブルからデータが消えるので後から検索をしたりするときに、変なデータが残って検索されてしまうことはありません。
さらに言えば、万が一データが漏れたとしても、過去のデータは消え去ってしまっているので、漏洩リスクが減るというメリットもあります。
SELECT * FROM users ;
検索するときはシンプルです。
後から何かを復活しようとしたり、過去のデータを遡って調べようとしない限りは DELETE を使った削除で十分です。
フラグによる論理削除
UPDATE users SET is_deleted = true WHERE user_id = 12345;
UPDATE users SET is_deleted = now() WHERE user_id = 12345;
is_deleted のようなフラグを使うパターンですね。上記のように boolean 型で設定する方法と、削除した日付を入れておく方法があります。
is_deleted の型をどう設定するのか、NULL を許容するのか、しないのか、の設計の違いがあります。
SELECT * FROM users WHERE is_deleted is NULL ;
当然検索するときに is_deleted のチェックが必要なのでひと手間かかります。
ここを忘れるのが開発上のネックになります。
特に多人数で開発しているときや、複数の会社で開発しているときはこの is_deleted チェックを忘れることが多いです。
しかし、だからダメというわけではありません。これは ORM によっては、is_delete を自動的にチェックしてくれます。
例えば、Laravel + Eloquent ORM では、Soft Delete という機能があって、
$items = $table->items() ;
という形で、内部では自動的に is_delete チェックが働いています。
また、集計関数などでも自動的に is_delete チェックが働きます。
$count = $table->total() ;
なので、”単一の開発言語で同一フレームワークを使っている” 場合限り、 is_delete フラグを使った論理削除は非常に便利です。
逆に言えば、他のプログラム言語や別々のフレームワークを使い始めたときには、is_delete チェックが問題になることが多いですね。
別テーブルによるデータ退避
かつては、元データを残したいときには別テーブルに退避することが多いです。
ただし、これは削除トリガーを使うとかしないと結構面倒くさいので、削除があまり発生しないテーブルに対してという限定手段になるでしょう。
あと、退避テーブルの構造を元のテーブルと同じにしないといけないので、テーブル設計が意外と面倒です。
BEGIN TRANSACTION;
INSERT INTO users_deleted SELECT * FROM users WHERE user_id = 12345;
DELETE FROM users WHERE id = 12345;
COMMIT;
2つの SQL 文が必ず動くので、トランザクションが必須です。
この部分は、DELETE トリガーを使ったも構いません。SQL だと、いちいち退避コードを書くのが面倒なので、トリガーを使った方が楽です。ただし、一気に DELETE するとその分トリガーも呼び出されてしまうので、その点は注意が必要です。
さらに言えば、これでは不十分で、users テーブルでは user_id がユニークキーになっているのですが、二重にデータを退避できません。例えば、id が一意、user_id がユーザーに見えるようなキー情報だと考えてみましょう。
CREATE TABLE users (
id BIGINT PRIMARY KEY,
user_id VARCHAR(64) UNIQUE,
name VARCHAR(128),
...
);
このような場合、退避テーブル users_deleted を二重に退避できるようにするには、次のようなテーブルになります。
CREATE TABLE users_deleted (
users_deleted_id BIGINT PRIMARY KEY,
deleted_at TIMESTAMP,
id BIGINT,
user_id VARCHAR(64),
name VARCHAR(128),
...
);
退避テーブルにユニークキーを置くかどうか、という設計もあり(ユニークキーがないと ORM からアクセスできないことが多い)、テーブル構造が users と users_deleted で異なります。
ここも設計ルールということになりますが、なかなか統一性を保つのは難しいですよね。
補助テーブルを使う
実は is_deleted フラグ自体は、主体となる user 情報の補助であるので、補助テーブルとして正規化してしまうのもひとつの方法です。
CREATE TABLE users (
id BIGINT PRIMARY KEY,
user_id VARCHAR(64) UNIQUE,
name VARCHAR(128),
...
);
CREATE TABLE users_status (
user_id BIGINT PRIMARY KEY,
is_deleted BOOLEAN,
deleted_at TIMESTAMP,
FOREIGN KEY (user_id) REFERENCES users(id)
);
常に users と users_status を JOIN して使わないといけないのが面倒ではありますが、users テーブルの内容が明確になります。ある意味で、一度作成したら絶対に消えません。
あと、本来はカード番号とか住所とか、セキュリティ上分離しておいたほうが良い情報を、users_status テーブルに保持しておくと漏洩のリスクが減ります。
これらは、あくまでデータを削除するための手法であったり、データを復活するような場面があったらどうするのか? セキュリティの確保や開発時のミスをどのように防ぐのか? という部分最適化の話になっています。
なので、ひとつの開発手法としては、
- 物理削除するならば、全体を物理削除で統一する
- is_deleted フラグを使う論理削除ならば、全体を論理削除で統一する
のがひとつの手段です。
これだと話が簡単なのですが、当然、それぞれの場面がありパーフォーマンスや開発ミスなどを考慮すると、そうでもないことが多いのです。
具体例をあてはめてみる
では、最初に示したように具体例を当てはめてみましょう。
- 自治体の住民検索、社会保険等
- 旅館の予約システム
- 工場の部品受注システム
- 回転寿司の受注システム
- 税務関係の社内経理システム、経費処理
- 社内のナレッジ管理、退職者の管理
データ量や時間軸の有無なども関係しているのですが、そこは具体例をみたほうがイメージしやすいと思います。
SQL 文やアクセスのための ORM コードを AI エージェントを使って書き出してみてください。昔は、手作業でちまちま整合性を確認していたのですが、今だと OpenAPI.xml を作成して MVC マッピングのコードを出力させることができます。そのなかで ORM や SQL を使ったデータ抽出を試してみるとよいです。
以下は、私の都合上 Laravel + Eloquent ORM の例を示しておきます。
自治体の住民検索、社会保険等
実は自治体のガバクラで「論理削除」が結構揉めていた時期があります。最終的には決裂してしまったのですが、さて、それからどうなったのかは私は知りません。
要は、自治体の住民情報は「調べたときのその時の情報」になります。過去の遡って転出してしまった住民の情報を調べることは…できなくもないのですが、それらを Web API で提供するかどうかという話になります。ガバクラで、その API 仕様があったのがそのあたりの難点になります。
- 自治体での住民情報の管理
- 住民の入退出の情報
- 社会保険の加入、脱退の情報
-- 自治体の住民情報スキーマ例
CREATE TABLE residents ( -- 住民基本台帳
id BIGINT PRIMARY KEY AUTO_INCREMENT,
resident_id VARCHAR(64) UNIQUE NOT NULL,
name VARCHAR(128) NOT NULL,
address VARCHAR(255) NOT NULL,
birth_date DATE NOT NULL,
status ENUM('active', 'moved_out', 'deceased') DEFAULT 'active',
registered_at TIMESTAMP NOT NULL,
status_changed_at TIMESTAMP NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
deleted_at TIMESTAMP NULL
);
CREATE TABLE resident_histories ( -- 住民の入退出履歴
id BIGINT PRIMARY KEY AUTO_INCREMENT,
resident_id BIGINT NOT NULL,
event_type ENUM('registration', 'move_in', 'move_out', 'status_change') NOT NULL,
address VARCHAR(255) NULL,
event_date TIMESTAMP NOT NULL,
remarks TEXT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
FOREIGN KEY (resident_id) REFERENCES residents(id)
);
CREATE TABLE insurance_records ( -- 社会保険加入履歴
id BIGINT PRIMARY KEY AUTO_INCREMENT,
resident_id BIGINT NOT NULL,
insurance_type VARCHAR(64) NOT NULL,
status ENUM('enrolled', 'withdrawn') DEFAULT 'enrolled',
enrolled_date DATE NOT NULL,
withdrawn_date DATE NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
FOREIGN KEY (resident_id) REFERENCES residents(id)
);
residents 住民基本台帳には deleted_at カラムを設けて論理削除を可能にしていますが、実際にはステータス status カラムでチェックすることになります。このテーブルでは、住民が自治体にいるときは「active」になるので、必ず where status = ‘active’ の検索が必要になります。
例えば、住民が 30 万人程度だとしても、転出や転入、死亡なども含めれば毎年結構な量になりますよね。大抵は active な筈ですが、長年使っていると active 以外が多くなりそうな可能性が高いです。
個人の一意性は、residents.resident_id で特定ができるので、他テーブルを使うことも可能なのですが、ちょっと待ってください。この個人が、同じ自治体に転出→転入をしたときはどうなるのでしょうか?
ひとりの個人に対して、ふたつ以上の resident_id になります。
なので、履歴自体を resident_histories や insurance_records テーブルで保持できるように管理していて「ひとりの個人の過去の履歴を取ってくる」ことが一見できそうな感じがしていて、実はできません。
-- residents.resident_id を指定して、住民の入退出履歴と社会保険加入履歴を取得する例
SELECT rh.*, ir.*
FROM residents r
LEFT JOIN resident_histories rh ON r.id = rh.resident_id
LEFT JOIN insurance_records ir ON r.id = ir.resident_id
WHERE r.resident_id in ( 'some_resident_id', 'another_resident_id' )
AND r.status = 'active';
この場合、residents.is_deleted チェックは、何を意味するのでしょうか?
既に、住民であるか否かは status カラムとして用意してあるので、is_delete は住民の有無をしめしません。
利用パターンとしては、「一時的に転入情報を個人として入れておいたが、実はデータの間違いが発生したのを削除しようとした」ぐらいと思われます。
つまり、この is_delete フラグは、住民基本台帳のデータとしてはかなり補助的な役割を示していると考えられ、status 的な意味とは異なります。更に言えば、後から戻すことも考えられません。転出したときのデータは status で管理するのですから、住民基本台帳である residents テーブルは “消されることがない” ことになります。
データとして増加し続けるのは容量的に問題だとは思いますが、たかだか 30 万人(10年後だったとしても 300 万人のレコードにはならないでしょう)ぐらいならば、ストレージを十分にとっておけば大丈夫そうです。
そういう試算をしたうえで、residents.is_deleted フラグは不要と考えられます。
-- 自治体の住民情報スキーマ例
CREATE TABLE residents ( -- 住民基本台帳
id BIGINT PRIMARY KEY AUTO_INCREMENT,
resident_id VARCHAR(64) UNIQUE NOT NULL,
name VARCHAR(128) NOT NULL,
address VARCHAR(255) NOT NULL,
birth_date DATE NOT NULL,
status ENUM('active', 'moved_out', 'deceased') DEFAULT 'active',
registered_at TIMESTAMP NOT NULL,
status_changed_at TIMESTAMP NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
さらに、自治体のデータベースアクセスは、単一のフレームワークからだけアクセスするとは限りません。将来的にさまざまな業者がプログラムを作ることになると考えられます。
こんな感じで、is_delete フラグの利用有無を考えていきます。
旅館の予約システム
今度は、旅館の予約システムを考えてみましょう。WEB サイトから旅館を予約します。ユーザーが部屋の空きがあるところを選んで予約します。当然、ユーザーログインが必要になり、ユーザーによるキャンセルも発生します。
- 旅館の部屋情報
- 部屋の空き/予約情報
- 予約カレンダー
- ユーザー情報
- ユーザーの予約履歴
- ユーザーのキャンセル履歴(やっぱり予約したいとか)
AI エージェントを使って、DDL を作成します。このとき、旅館の部屋の価格が期間によって異なるのでこれも追加します。
-- 旅館の部屋情報
CREATE TABLE rooms (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
room_number VARCHAR(64) UNIQUE NOT NULL,
room_type VARCHAR(64) NOT NULL,
capacity INT NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
CREATE TABLE room_pricing (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
room_id BIGINT NOT NULL,
season_start_date DATE NOT NULL,
season_end_date DATE NOT NULL,
price DECIMAL(10, 2) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
FOREIGN KEY (room_id) REFERENCES rooms(id),
UNIQUE KEY unique_pricing (room_id, season_start_date, season_end_date)
);
-- 予約情報
CREATE TABLE reservations (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
user_id BIGINT NOT NULL,
room_id BIGINT NOT NULL,
check_in_date DATE NOT NULL,
check_out_date DATE NOT NULL,
status ENUM('confirmed', 'cancelled', 'completed') DEFAULT 'confirmed',
reserved_at TIMESTAMP NOT NULL,
cancelled_at TIMESTAMP NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
FOREIGN KEY (user_id) REFERENCES users(id),
FOREIGN KEY (room_id) REFERENCES rooms(id),
UNIQUE KEY unique_reservation (room_id, check_in_date, check_out_date)
);
-- ユーザー情報
CREATE TABLE users (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
username VARCHAR(128) UNIQUE NOT NULL,
email VARCHAR(255) UNIQUE NOT NULL,
name VARCHAR(128) NOT NULL,
phone VARCHAR(20) NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
-- キャンセル履歴
CREATE TABLE cancellation_history (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
reservation_id BIGINT NOT NULL,
cancelled_at TIMESTAMP NOT NULL,
reason TEXT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (reservation_id) REFERENCES reservations(id)
);
ここで、部屋 rooms と部屋の価格 room_pricing は、基本的に削除されないように設計されてしまいますが、いや、そんなことはないですよね。部屋が老朽化して使えなくなったり、旅館自体が閉鎖されたりすることもあります。そういう場合は、rooms テーブルから削除しないといけません。しかし、削除してしまうと過去の部屋の予約履歴がなくなってしまいます。id のリンクが外れてしまうわけです。
この場合、rooms.id を残しつつ、同じ room_number を再利用できるようにしなければいけません。
ここで、is_deleted フラグを使うのか、別テーブルに退避するのかという設計の選択が必要になります。
rooms の一意性を確保したい場合には、別テーブルに退避して、過去の経理情報を調べるときには退避テーブルのほうも参照する、という設計にすることになります。
ただし、rooms テーブルのデータ数は非常に少ないと考えられます。さらに言えば、頻繁に変わることはないでしょう。
そこを考慮したうえで rooms テーブルに is_deleted フラグを追加することにしましょう(もちろん、逆に is_deleted フラグを追加しない設計もありえます)。
-- 旅館の部屋情報(削除を考慮)
CREATE TABLE rooms (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
room_number VARCHAR(64) NOT NULL,
room_type VARCHAR(64) NOT NULL,
capacity INT NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
deleted_at TIMESTAMP NULL
);
room_number がユニークキーにならないので、注意してください。
ただし、過去も含めて room_number だけで検索することができます。過去の年間の予約状況を調べるときに便利ですね。
-- 過去の部屋の予約状況を調べる例
SELECT r.room_number, res.check_in_date, res.check_out_date, res.status
FROM rooms r
LEFT JOIN reservations res ON r.id = res.room_id
WHERE r.room_number = '101'
AND res.status = 'completed' -- 完了した予約のみ
AND res.check_in_date between '2023-01-01' AND '2023-12-31'
ORDER BY res.check_in_date DESC;
過去の場合は is_delete のチェックを外します。
逆に言えば、現在利用できる rooms のリストでは is_deleted チェックが必須です。
-- 現在利用可能な部屋のリストを取得する例
SELECT *
FROM rooms
WHERE deleted_at IS NULL;
これは、どちらを主要に使うかですね。
主に経理系や過去の取引履歴などを参照することが多い場合は、is_deleted フラグを使ったほうが便利です。
工場の部品受注システム
過去のデータを遡らなくてはいけないのは、おそらく工場の BOM 関係のシステムです。
部品自体は BOM 情報としてスナップショットがいいのですが、過去の受注状態を顧客から調べるときには BOM 表にないデータも必要になります。つまりは、生産終了したものも含めないといけないので、ここも BOM テーブルに残さないといけません。
これも、現在持っている部品と、生産中止した部品を別テーブルに持つことも可能なのですが、かなり煩雑です。部品に関連する情報が常に補助テーブルを参照するようになってしまいます。
- 部品マスター
- 部品補助情報
- 部品の調達先
- 受注情報
- 部品生産管理
- 部品の組み合わせテーブル
- 受注組みあわせ番号管理
- 顧客発注履歴
このパターンで AI に作成して貰います。
-- 部品マスター
CREATE TABLE parts (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
part_number VARCHAR(64) UNIQUE NOT NULL,
part_name VARCHAR(255) NOT NULL,
description TEXT NULL,
unit_price DECIMAL(10, 2) NOT NULL,
lead_time_days INT DEFAULT 0,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
deleted_at TIMESTAMP NULL
);
-- 部品補助情報
CREATE TABLE part_details (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
part_id BIGINT NOT NULL,
weight DECIMAL(10, 4) NULL,
dimensions VARCHAR(255) NULL,
material VARCHAR(128) NULL,
storage_location VARCHAR(128) NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
FOREIGN KEY (part_id) REFERENCES parts(id)
);
-- 部品の調達先
CREATE TABLE part_suppliers (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
part_id BIGINT NOT NULL,
supplier_id BIGINT NOT NULL,
supplier_part_number VARCHAR(64) NULL,
supplier_price DECIMAL(10, 2) NOT NULL,
lead_time_days INT DEFAULT 0,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
FOREIGN KEY (part_id) REFERENCES parts(id),
FOREIGN KEY (supplier_id) REFERENCES suppliers(id)
);
-- 受注情報
CREATE TABLE purchase_orders (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
po_number VARCHAR(64) UNIQUE NOT NULL,
supplier_id BIGINT NOT NULL,
order_date DATE NOT NULL,
expected_delivery_date DATE NOT NULL,
actual_delivery_date DATE NULL,
status ENUM('pending', 'ordered', 'received', 'cancelled') DEFAULT 'pending',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
FOREIGN KEY (supplier_id) REFERENCES suppliers(id)
);
-- 部品生産管理
CREATE TABLE part_production (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
part_id BIGINT NOT NULL,
production_date DATE NOT NULL,
quantity_produced INT NOT NULL,
quality_status ENUM('pass', 'fail', 'rework') DEFAULT 'pass',
notes TEXT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
FOREIGN KEY (part_id) REFERENCES parts(id)
);
-- 部品の組み合わせテーブル(BOM)
CREATE TABLE bom_items (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
bom_id BIGINT NOT NULL,
part_id BIGINT NOT NULL,
quantity INT NOT NULL,
sequence INT NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
FOREIGN KEY (bom_id) REFERENCES bom(id),
FOREIGN KEY (part_id) REFERENCES parts(id),
UNIQUE KEY unique_bom_part (bom_id, part_id)
);
-- BOM マスター
CREATE TABLE bom (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
product_number VARCHAR(64) UNIQUE NOT NULL,
product_name VARCHAR(255) NOT NULL,
version INT DEFAULT 1,
effective_date DATE NOT NULL,
status ENUM('active', 'obsolete') DEFAULT 'active',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
deleted_at TIMESTAMP NULL
);
-- 受注組み合わせ番号管理
CREATE TABLE customer_orders (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
order_number VARCHAR(64) UNIQUE NOT NULL,
customer_id BIGINT NOT NULL,
bom_id BIGINT NOT NULL,
order_date DATE NOT NULL,
delivery_date DATE NOT NULL,
quantity INT NOT NULL,
status ENUM('pending', 'in_production', 'completed', 'cancelled') DEFAULT 'pending',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
FOREIGN KEY (customer_id) REFERENCES customers(id),
FOREIGN KEY (bom_id) REFERENCES bom(id)
);
-- 顧客発注履歴
CREATE TABLE order_history (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
customer_order_id BIGINT NOT NULL,
status_changed_to VARCHAR(64) NOT NULL,
changed_at TIMESTAMP NOT NULL,
notes TEXT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (customer_order_id) REFERENCES customer_orders(id)
);
-- 顧客マスター
CREATE TABLE customers (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
customer_code VARCHAR(64) UNIQUE NOT NULL,
customer_name VARCHAR(255) NOT NULL,
contact_person VARCHAR(128) NULL,
phone VARCHAR(20) NULL,
email VARCHAR(255) NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
-- サプライヤーマスター
CREATE TABLE suppliers (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
supplier_code VARCHAR(64) UNIQUE NOT NULL,
supplier_name VARCHAR(255) NOT NULL,
contact_person VARCHAR(128) NULL,
phone VARCHAR(20) NULL,
email VARCHAR(255) NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
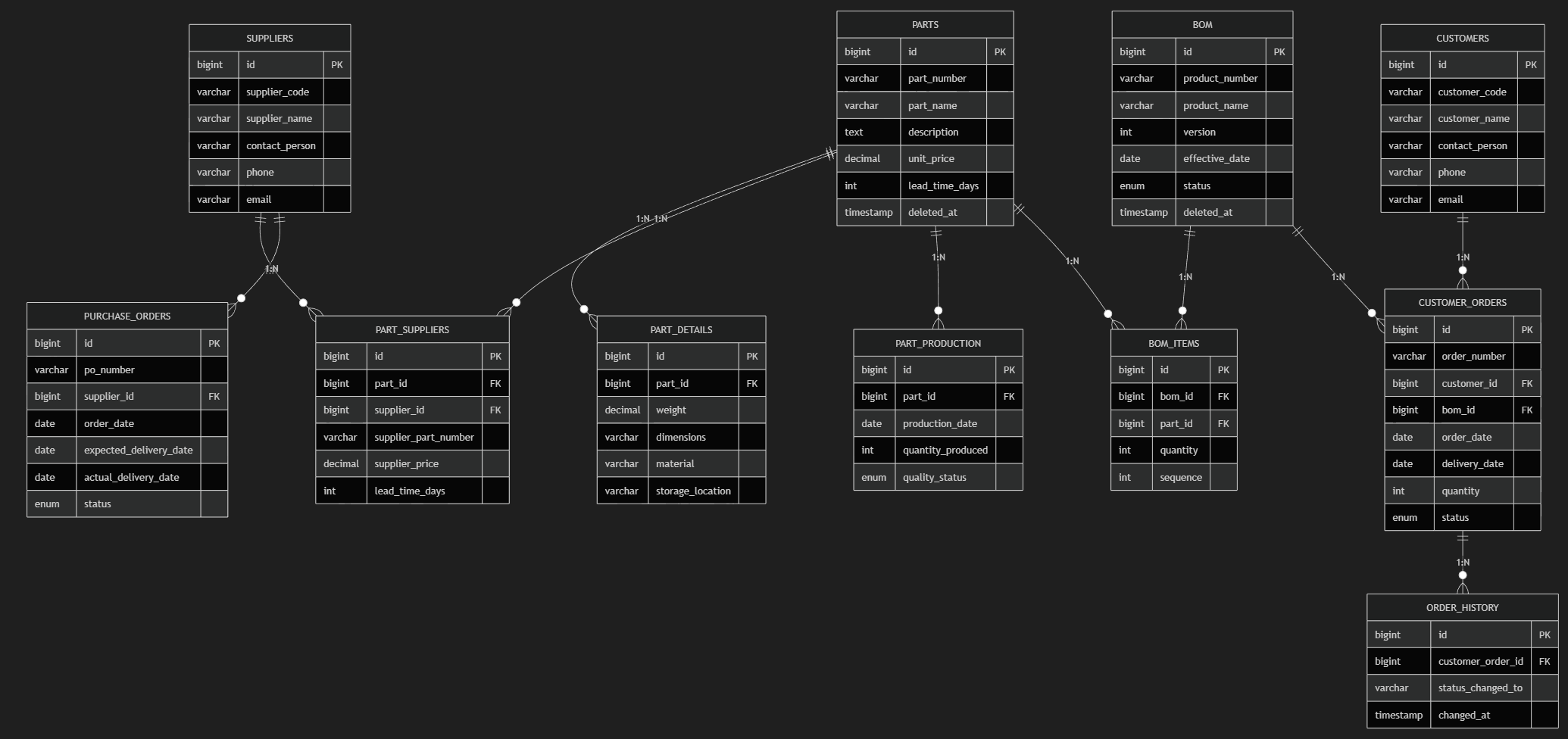
この状態で deleted_at が付いているのは、
- parts テーブル
- bom テーブル
の 2 つです。部品 parts テーブルは、過去の受注履歴を調べるときに必要になります。BOM テーブルも同様です。生産管理の部品調達は、他社のコードと自社のコードが混在します。更に、現在生産可能なもの調達可能なもの、調達不可能なものが混在するわけです。これを期間で管理する必要もあり、調達不可能な場合にはほかの会社に切り替える必要がでてくるので、ここも調節しないといけません。
これらを過去の情報も含めて、顧客から参照できるようにする(過去の調達の組み合わせや履歴を参照できるようにするため)ので、テーブル数が膨大になります。ここではサンプルなのでこの程度なのですが、実際には 100 テーブルを超えてしまいます。
そんな中で、統一的に is_deleted にするのか、物理削除にするのか、というのはかなり不可能に近いです。集計クエリの対象になりやすいとか、過去を参照せずに、物理削除で十分であるとか、そのような考慮をいれてそれぞれのテーブルの設計を行わなければいけません。
いったんここで区切り
この記事、結構長くなりそうなので、いったんここで区切ります。
- 回転寿司の受注システム
- 税務関係の社内経理システム、経費処理
- 社内のナレッジ管理、退職者の管理
については次回で。
単なる「論理削除/物理削除とは?」という単純な話ではなくて、具体的にユースケースを出して考えるとよいです。先にも書きましたが AI エージェントを使うと SQL とか ORM のサンプルコードを出してくれるので、実験がしやすくなっています。仮説を立てるだけでなく、検証がやりやすくなったので活用してください。
続き 2025/12/22
論理削除と物理削除の続き https://www.moonmile.net/blog/archives/11878
