去年だと思いますが、生成AIがちょっと流行った頃に(今はAI エージェントが流行っている)、東京都のとある区で粗大ごみの分類を検索する入札が行われました。で、どこかの会社が受けたと思うのですが、検索した適合率が90%程度だったので採用にならず、というのがありました。
ちょうど、その頃に Azure OpenAI 本を出版したときもあって、この第10章に Function Calling の活用があって、それを使うともう少し精度ができるなぁ、と思った次第です。
OpenAI の Function Calling は AI のプロンプト上から特定の関数を呼び出すことができる仕組みです。ちょうど JSONP のような形でコールバックを返してくれます。で、いまでは MCP (Model Context Protocol) サーバーを立てるというパターンもあるので、Function Calling を使った RAG (Retrieval-Augmented Generation)にするか MCP サーバーにするかというところですが、このあたりはチャット部分を自前で作成するか、Claude Desktop などを利用した既存のチャット/プロンプトを使うか、という形で分かれます。
板橋区粗大ごみの分類を取得
粗大ごみの分類は各自治体でかなり違ってきます。そのために分類も違ってくるので、なかなか統一できません。
粗大ごみ(申込制/有料)・料金検索(AIチャットボット)|板橋区公式ホームページ https://www.city.itabashi.tokyo.jp/tetsuduki/gomi/sodai/1001868.html
ひと世代前のチャットボットが流行りなのですが、まあ、ひと世代前なのです。
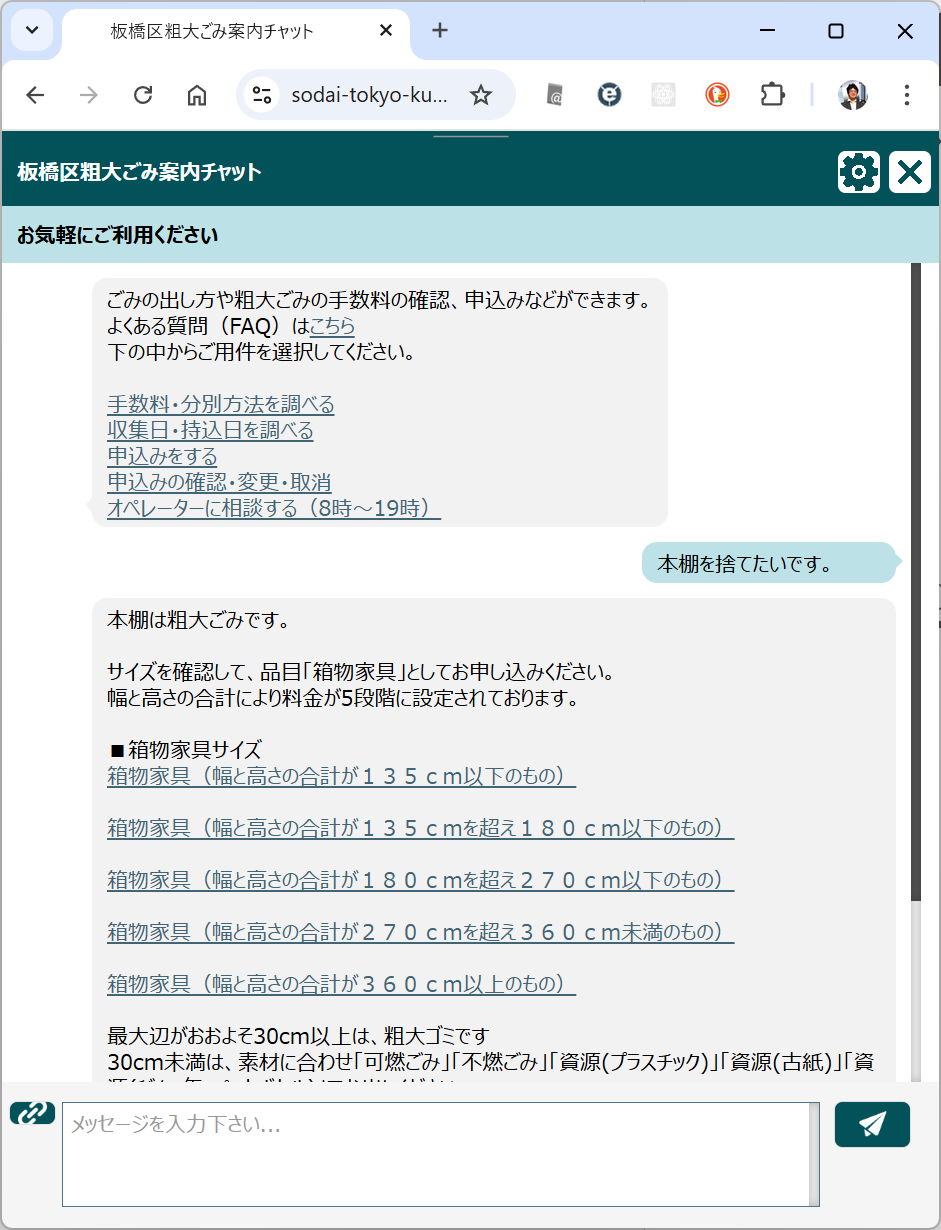
ピンポイントで検索できるものはいいのですが、ちょっと込み入ったものだと微妙です。この例では「ガラス」に引っ張られていますが、「机」のほうがよいですよね。実際に「机」の分類があります。
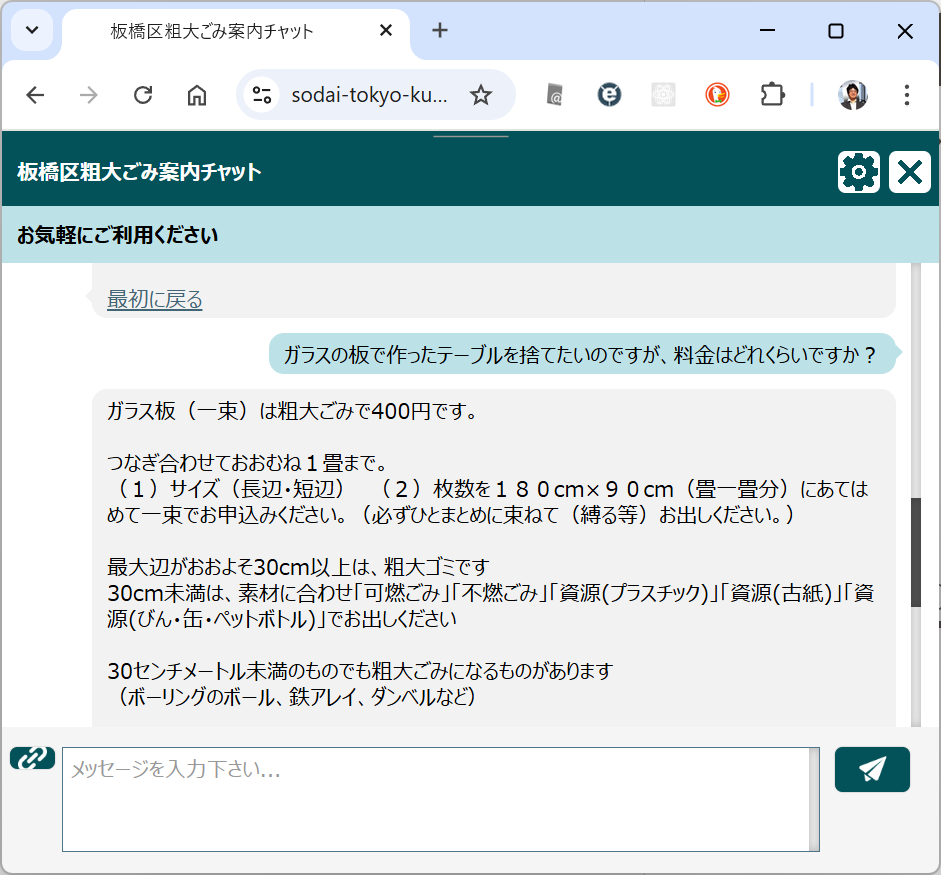
結局めんどうくさくなって、PDF の一覧表から検索したりします。
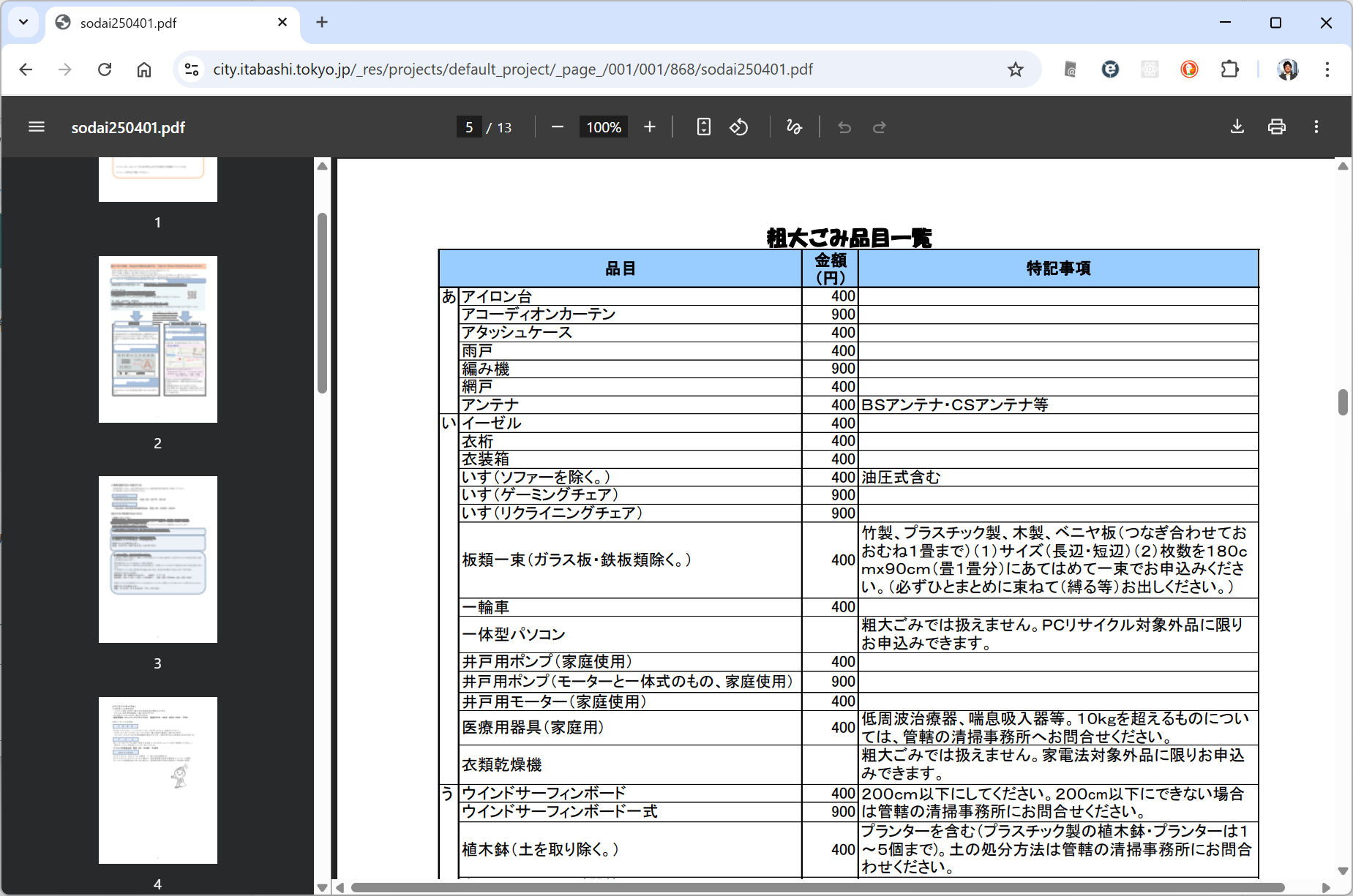
実は分類は400弱ぐらいしかないので、そう多くないです。要は利用者が自然言語を使って質問しているところに、サイト側で「キーワードマッチ」しかしていないのが問題です。というか、当時のチャットボットはそういうものだったので、これでも十分なような気がします。
が、生成AIを使っていけば、もう少し利用者側に便利できるのでは?と思ったのが、RAG や MCP サーバーの登場というところです。
粗大ごみの分類DBを作る
粗大ごみの分類が PDF で提供されているので、これを SQLite のような DB で扱えるようにします。この作業を ChatGPT を使おうと苦戦したのですが、あえなく挫折しています。どうも PDF の表面は表形式に見えるのですが、中身がぐちゃぐちゃになっているようで ChatGPT が python で読み込もうとして失敗してしまいます。画像読み込みを試せばよかったのですが、まあ、数も400行位だしということで、手作業で Excel に直しました。
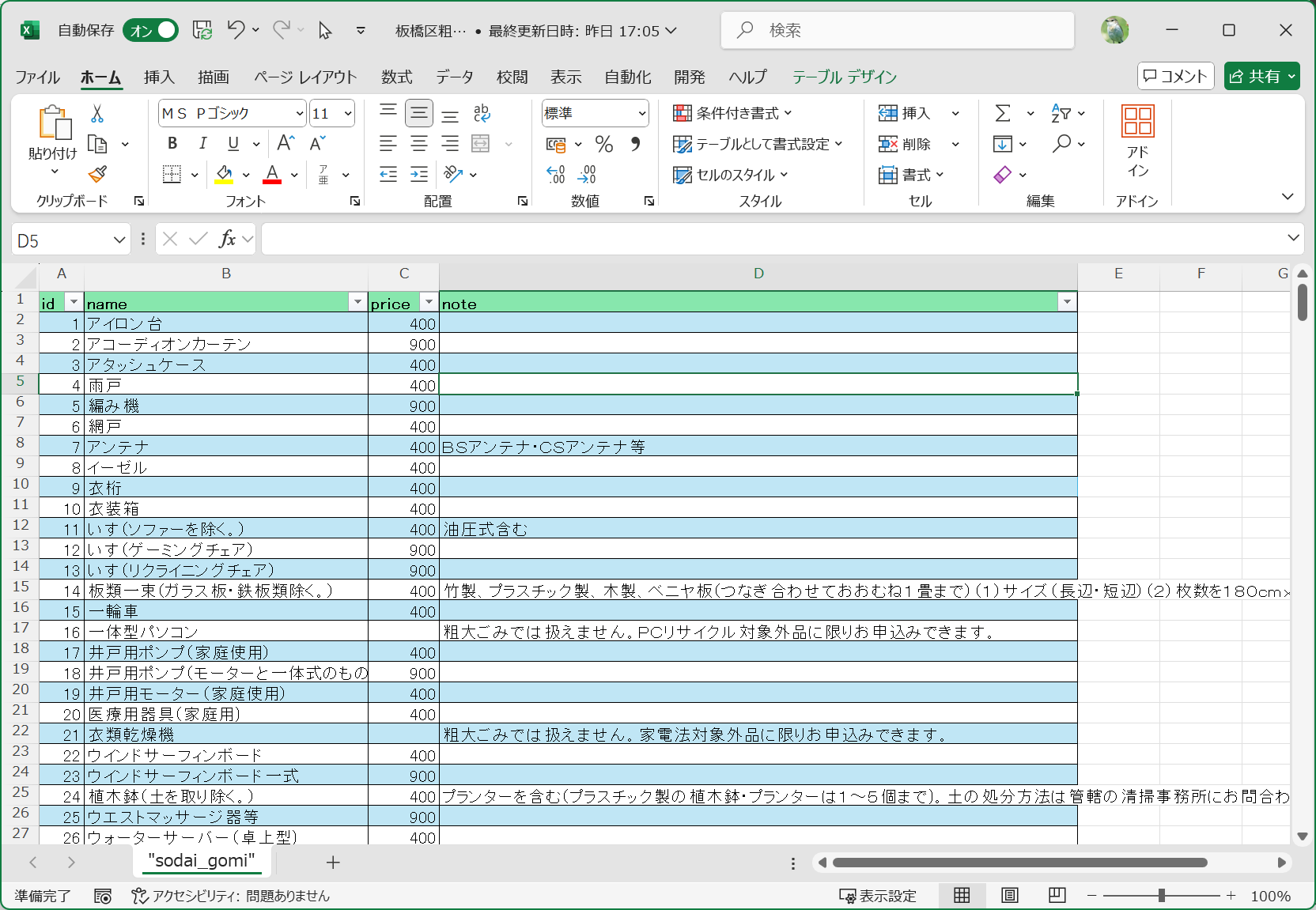
試しに分類をやってみたいという奇特な方はこれを使ってみてください。自分の自治体に CSV 形式であればそれを使ってください。
板橋区の場合は「名前」「金額」「特記事項」となっています。まあ、中身をみるとわかるのですが、特記事項に品名っぽいものが書いてあったり、名前にサイズ(机のサイズとか)が書いてあったりしてかなり混乱しています。この手のやつは自治体では仕方ないことで、まあデ庁の標準化は大変だろうな、といいますか、そもそもデ庁主導では標準化できないだろう、などと思ったりししつつ、さてどうしたものかと考えるのです。
面倒な場合は Excel にした後で検索すれば一発なので、うまくキーワードが検索できればそれで十分ですよね。
ユーザーインターフェースを考える
最近は要件定義や設計を readme.md に残すようにしています。
# 粗大ごみ検索システムの試作
粗大ごみの分類を LLM を既存データベースを組み合わせて金額を調べるシステム
## 概要
- 粗大ごみの分類は、既存のデータベース(SQLite)を使用
- フロントエンドの UI は Chat を使う
- フロントエンドは OpenAI API を使うと高くなるので、ローカル LLM を利用する
## ユースケース
例1
- ユーザーが「ソファを捨てたい」と入力
- システムが「ソファは粗大ごみです。料金は500円です。」と応答
例2
- ユーザーが「冷蔵庫と洗濯機を捨てたい」と入力
- システムが「冷蔵庫の料金は1500円です。洗濯機の料金は1000円です。」と応答
例3
- ユーザーが「本棚を捨てたい」と入力
- システムが「本棚の高さは200cm以上ですか?」と応答
- ユーザーが「はい」と入力
- システムが「本棚は粗大ごみです。料金は800円です。」と応答
## 技術スタック
- フロントエンド: React
- データベース: SQLite
- LLM: Local LLM + Next.js
- API: OpenAI API + Laravel
こんな風にユースケースを書いておきます。例をいくつか書いておいて、こういうプロンプトを入れたらこういう形で AI が返してくれる。再びチャットを続ける、という形でユーザーインターフェースをデザイン=設計していきます。
以前ならば、このユースケースを設計書に落とし込んで、ルールベースに直して、実装してという手順になり、それを自分でやらなくてはならないのですが、AI エージェントのおかげでこのあたりの手順を AI に任せることができます。漠然としたユースケースなので自動化という訳にはいきませんが、以前よりも実装スピード=プロトタイプが出来るスピードが早いです。
- ユースケースを示しながら、設計を AI と相談する
- ユースケースが実験できるような、プロトタイプの画面を AI に作成して貰う
- 設計に従って、AI にコーディングしてもらう
- 細かい動きを AI に修正してもらう
という形で、ほぼほぼ AI がコーディングを担当していきます。私は、動作確認をしたり、プロトタイプを見て感想を言ったり、テストするポイントを AI に伝えたりという役目です。
AI コーディングには Claude Sonnet を使っていますが、こんな風なイテレーション開発の場合にはこれで十分です。
利用者のプロンプトを解釈する
ユースケースから考えると、プロンプトは利用者のブラウザで動かすことになります。
- 利用者が、プロンプトを開いて「ソファを捨てたい」と入力する
- 「ソファを捨てたい」から「ソファ」の単語を抜き出す。
- 「ソファ」にマッチするデータを、粗大ごみ DB から検索する
- 「ソファ」の金額が検索できる
- プロンプトが「ソファの金額は400円です」と回答する
というユースケース記述ができます。「ユースケース記述」は要件定義やシステム概要設計で使うときの UML のひとつです。
さて、自然言語で「ソファを捨てたい」と利用者が入力するわけですが、単純な単語のマッチングではなくて、AI を使って「ソファ」という単語を取り出します。つまりは、プロンプトのプレ処理に OpenAI API を使う訳です。AI の活用では、こういうように文章から重要な用語を抜き出す用途にも使えます。
が、いちいち OpenAI API を呼び出していると課金されて高いですよね(実は ChatGPT5 の値段が相当安いので、呼び出しても大したことはないのですが)。なので、ここでローカルLLM を使います。ローカルLLMを使えば課金が一切なくなるので、API の呼び出し放題です。
と、いうところまで構想をたてて、まずは laravel の webapi を作成中です。もう少しできあがったら追記します。
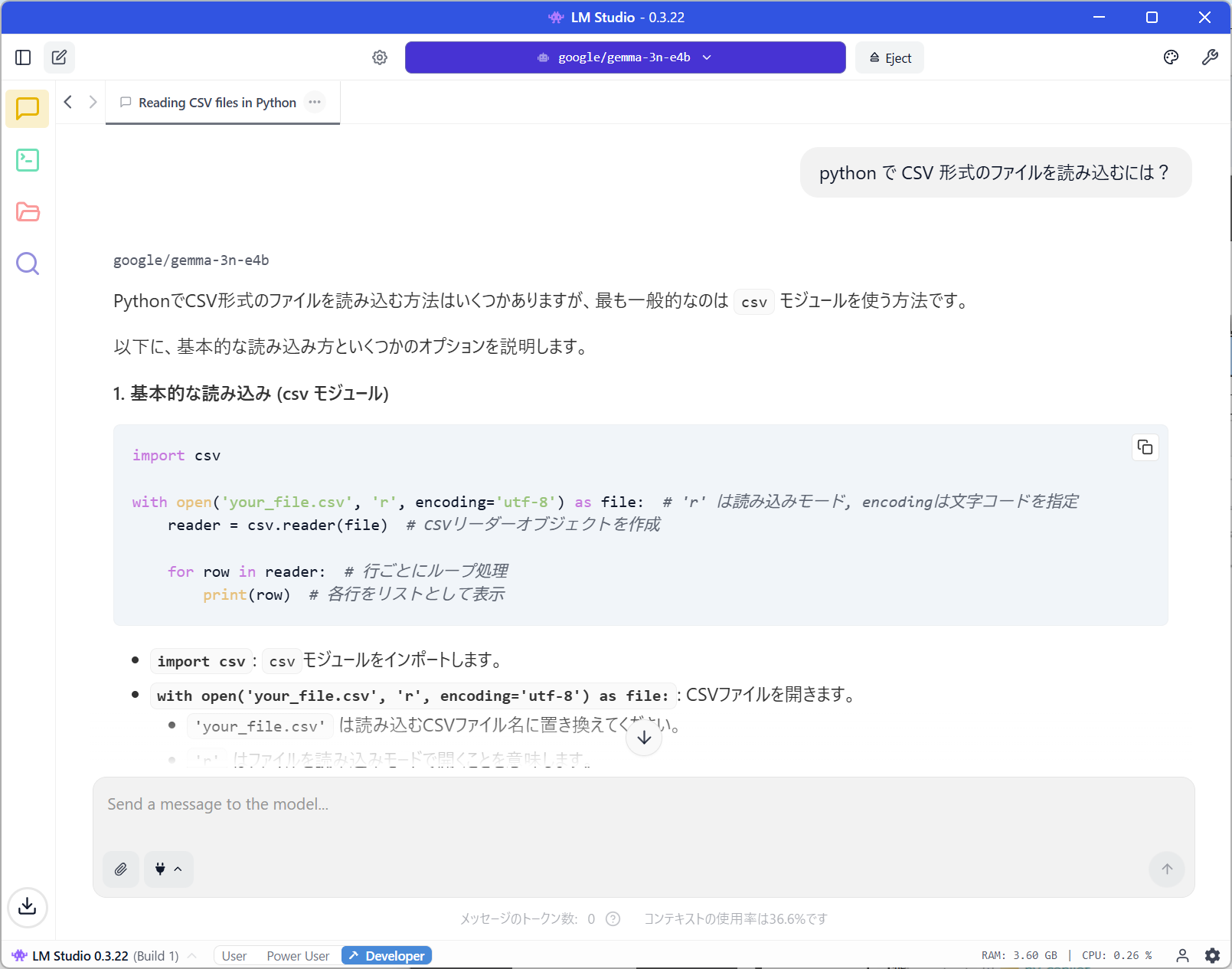
ローカル LLM には LM Studio あたりを使う予定。モデルは Google の gemma あたりで十分です。