
築地市場から豊洲市場への移転に関して、諸々を調べていた時にちょうどよさそうな大量データをみつけたので、紹介がてら。
中央卸売市場の卸売数量は公開されている
いわゆる築地とか豊洲とかの卸売市場は都が経営をしていて、もろもろの情報は以下で公開されています。
東京都中央卸売市場日報
http://www.shijou-nippo.metro.tokyo.jp/
2004年から記録があるので10年以上のデータを取得できます。が、あまり多くても仕方がないのでひとまず5年間分(2013年1月から2018年11月)までの青果と水産のデータをとってきました。
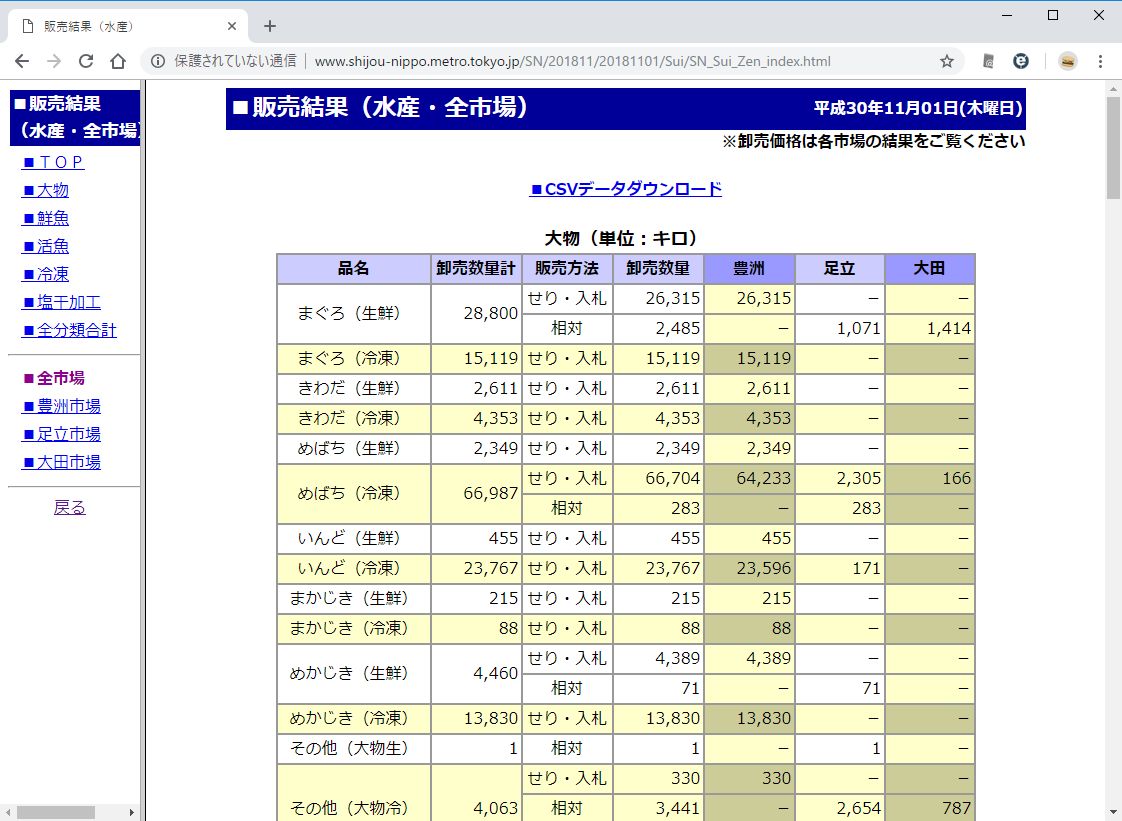
ページを探っていくと、こんな形でテーブルで表示されています。これをCSV形式でダウンロードができます。
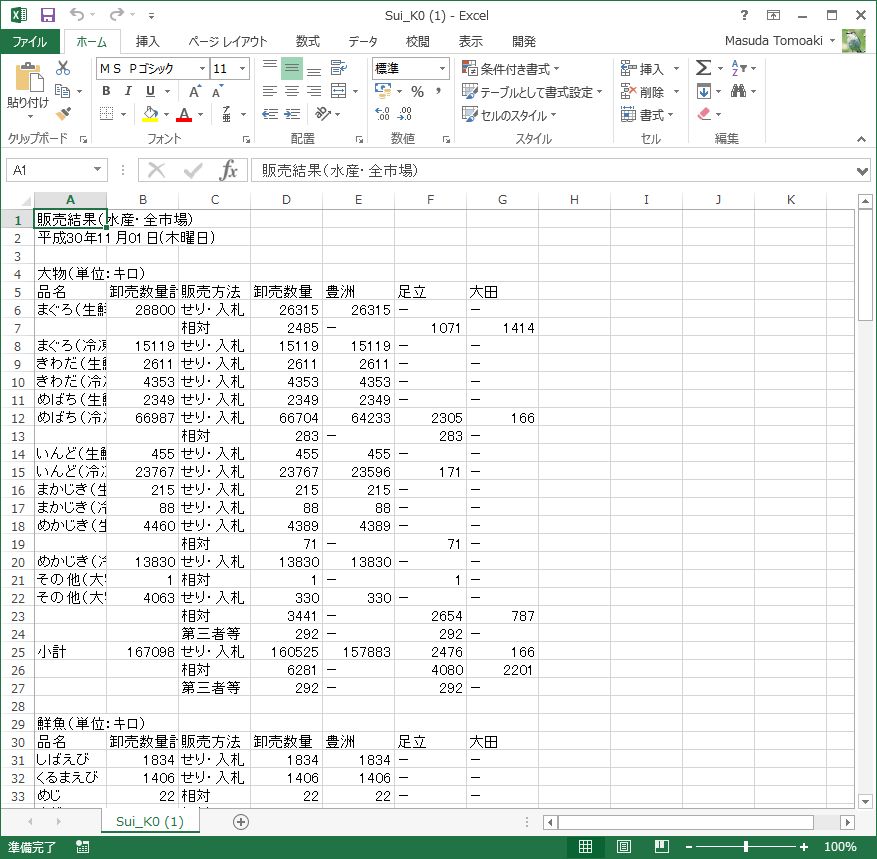
CSV形式とはいえ、こんな風にテーブルからとってきたような形のCSV形式なので(一応カンマ区切りにはなっている)ちょっと扱いにくいのです。
公開されているデータ整形する
このままではデータとして扱いづらいので、データベースに挿入できるように本当のCSV形式に直してしまいます。
open System
open System.IO
// 1行目: 販売結果(青果・全市場) → 棟
// 2行目: 平成30年08月01日(水曜日) → 日付
// "(単位:キロ)" で → 分類
// "品名..." で → 市場
// 以降、1行ごとに 品物, 販売方法, 卸売数量(市場ごと)
// ただし、小計、全分類合計は取り込まない
// 出力フォーマット
// 日付, 棟, 分類, 市場, 品名, 販売方法, 卸売数量
let rec readtable (sr:System.IO.StreamReader) 棟 (日付:DateTime) 分類 (市場:string[]) 品名_ =
let 数量 = sr.ReadLine().Split(",")
let 品名 = if 数量.[0] <> "" then 数量.[0] else 品名_
if 数量.[0] <> "小計" then
for i in [4..市場.Length-1] do
let 市場名 = 市場.[i]
let 卸売数量 = if 数量.[i] = "−" then "0" else 数量.[i]
let 販売方法 = 数量.[2]
printfn "%s" (
String.Format("{0},{1},{2},{3},{4},{5},{6}",
日付.ToString("yyyy/MM/dd"),
棟,
分類,
市場名,
品名,
販売方法,
卸売数量 ))
readtable sr 棟 日付 分類 市場 品名
()
let readblock (sr:System.IO.StreamReader) 棟 日付 =
let 分類 = sr.ReadLine().Replace("(単位:キロ)","")
let 市場 = sr.ReadLine().Split(",")
if 分類 <> "全分類合計" then
readtable sr 棟 日付 分類 市場 ""
()
let readcsv (sr:System.IO.StreamReader) =
let 棟 = sr.ReadLine().Replace("販売結果(","").Replace("・全市場)","")
let ci = new System.Globalization.CultureInfo("ja-JP")
let 日付 = DateTime.Parse(
sr.ReadLine().Substring(0,11),
new System.Globalization.CultureInfo("ja-JP"),
System.Globalization.DateTimeStyles.AssumeLocal)
sr.ReadLine() |> ignore // 空行
while sr.EndOfStream = false do
readblock sr 棟 日付
// 空行まで読み捨て
while sr.EndOfStream = false && sr.ReadLine() <> "" do
()
()
[<EntryPoint>]
let main argv =
if argv.Length = 0 then
printfn "ex. tukizi sui_20181105.csv"
else
// printfn "%s" argv.[0]
for fname in argv do
let sr = new System.IO.StreamReader( fname )
readcsv sr
sr.Close()
0
コードがF#になっているのはいつものことですね。この手の整形をやるのはC#よりもF#で書いたほうがやりやすかったりします。一番内側の readtable 関数内で再帰を使って品名の部分を読み込んでいます。もっと頑張れば for ループを無くせるはずなのでしょうが、ひとまずこれ動いたのでokということで。
何ができるのか?
データ量はざっと200万件近くあります。200万件あると検索が重たくなって大変なのでは?と思っていたのですが、MySQL に突っ込めば全然平気ですね。ひとつのテーブルしか扱わないというのもあるのですが(面倒なので敢えて正規化していません)、一千万件ぐらいあると検索に時間が掛かるのかもしれませんが、200万件位だったら sum を使って集計しても全然あっという間に終わります。
実は200万件の実データを集めるのは結構大変なのです。調査するにしてもデータベースの勉強をするにしても、これだけのデータを扱えるのは結構貴重ではないかな?と思うのです。
5年間分のデータは https://1drv.ms/u/s!AmXmBbuizQkXgpUYeqUVYd7WhAl4uw からダウンロードしてください。MySQLに入れてからエクスポートしたデータと、先のツールで成形したCSV形式のデータが入っています。
テーブル構造以下の通りです。面倒だったので列名は日本語のままw
CREATE TABLE `tt` ( `日付` datetime NOT NULL, `棟` varchar(45) NOT NULL, `分類` varchar(45) NOT NULL, `市場` varchar(45) NOT NULL, `品名` varchar(45) NOT NULL, `販売方法` varchar(45) NOT NULL, `卸売数量` double NOT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
去年のさんまの卸売数量を調べてみよう
例えば、去年1年間の「さんま」の取扱量をみてみましょう。
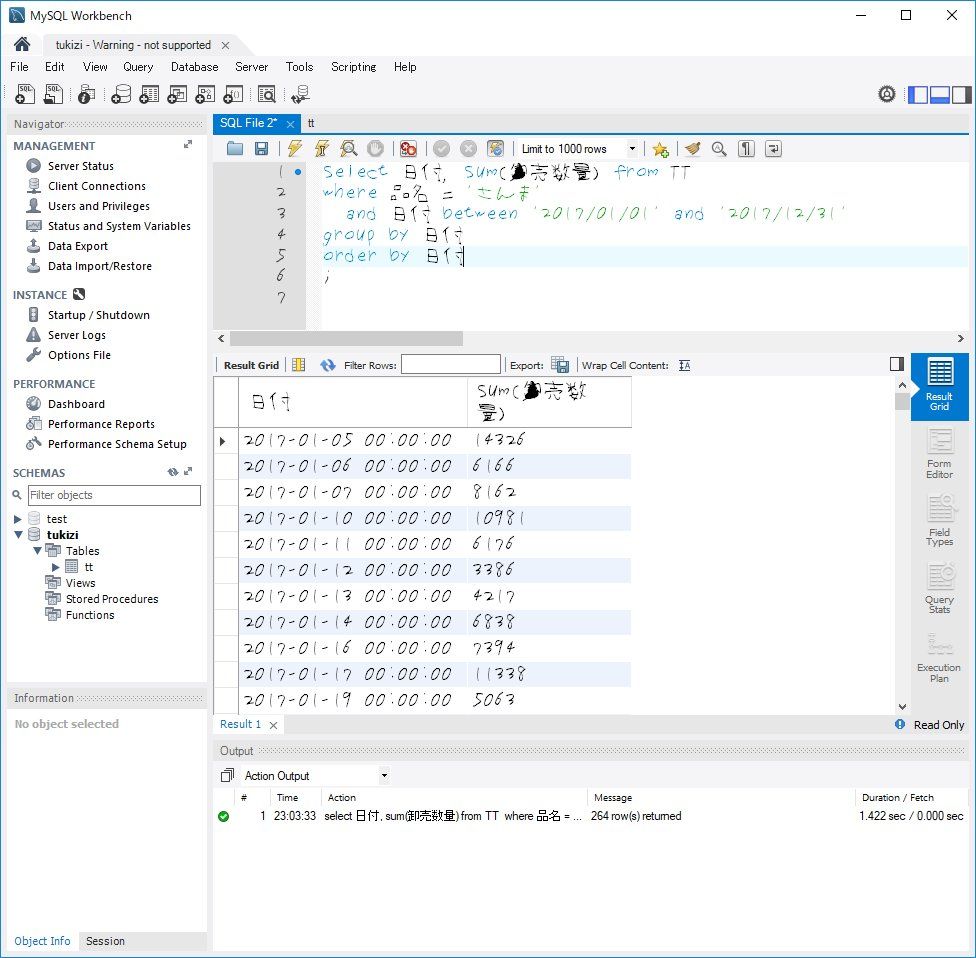
select 日付, sum(卸売数量) from TT where 品名 = 'さんま' and 日付 between '2017/01/01' and '2017/12/31' group by 日付 order by 日付 ;
こんなクエリを書いて日付でソートすれば、日単位の卸売数量がわかります。
結果をExcelに貼り付けてグラフを追加すれば、ほら自由研究のできあがり。
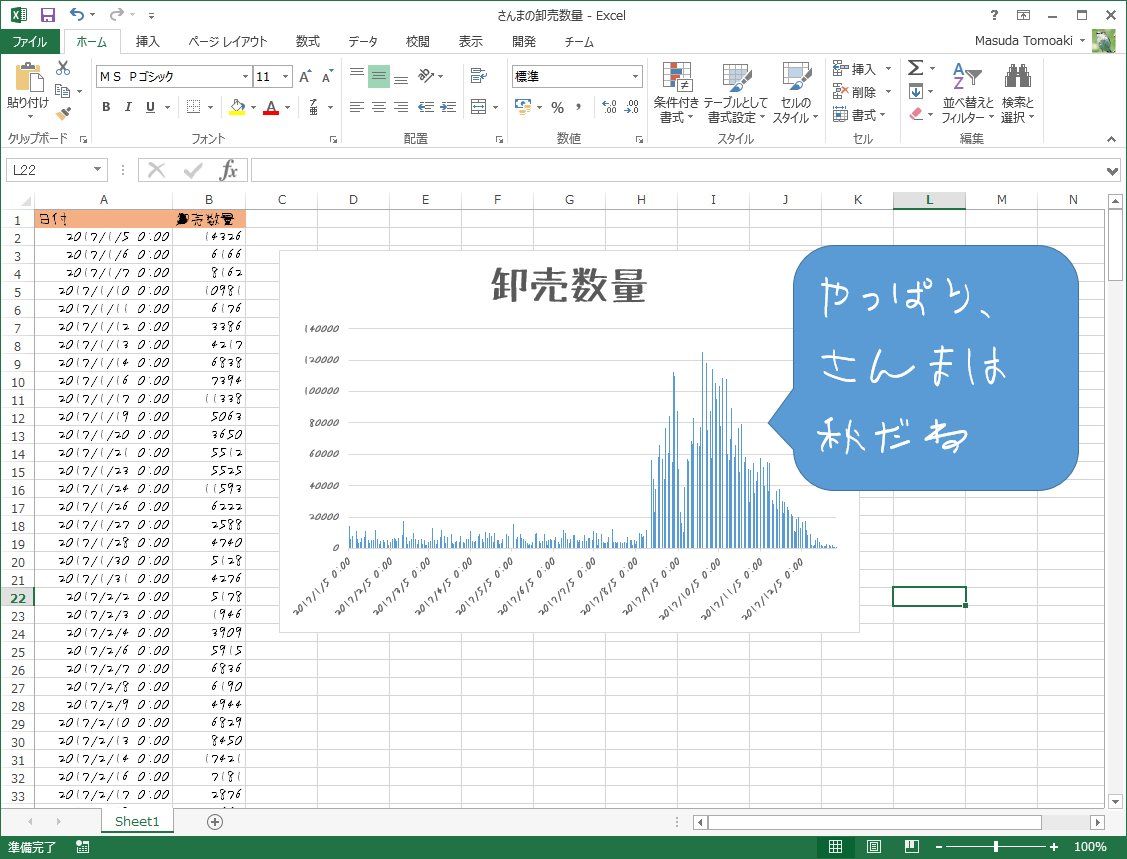
ちなみにフォントは「全児童フォント(フェルトペン)」 http://tanukifont.com/zenjido/ を使っています。お試しあれ。
