
PP-Club メンバの美崎さんのライフハッカーの記事
SimpleStyle100回突破記念~編集部が選ぶ美崎薫氏のアプリ25選 : ライフハッカー[日本版]
http://www.lifehacker.jp/2012/05/120417misakihacks.html
プログラムのソースコードから変数を出力するヘルパー『makeMessagebox』(SimpleStyle第119回) : ライフハッカー[日本版]
http://www.lifehacker.jp/2012/08/12-08-30makemessageboxsimplestyle119_1.html
をなんとか活用できないかと、美崎さん当人に相談したところ「ライフハッカーの目次って用意されていないんですよね~ orz」の返事が orz ああ、目次ないんですね、これ。
一応、当人的には、http://www42.tok2.com/home/papermoon/ なところで、自動生成を試みているらしいのですが、ちょっとこれではアレすぎて全体の見通しが付きません。CSS で適当にレイアウトすればいいんでしょうが、自動生成の精度が悪いらしくというところだそうです。
で、本格的なところはライフラッカーへのクローリングか、google api を使うのがよいのですが、ひとまず、先のページからリンクとタイトルぐらいは抜き出して Excel で整理するところまではやりたいと思う訳ですよ。なので、手順としては、
- 該当するページを HTML ファイルで「手動」で保存。
- HtmlDom を使って、リンクとタイトルを抽出する。
- CSVファイルへ書き出し。
- Excel で開いてファンクションを使って適当に整形
「手動」なところが混じっていますが、全体の作業量を考えるとなにも全体を「自動化」する必要がありませんッ!!! ってのが PP-Club の信条でして(つーか、私自身の信条)、リンクとタイトルだけを取り出せばよいわけです。
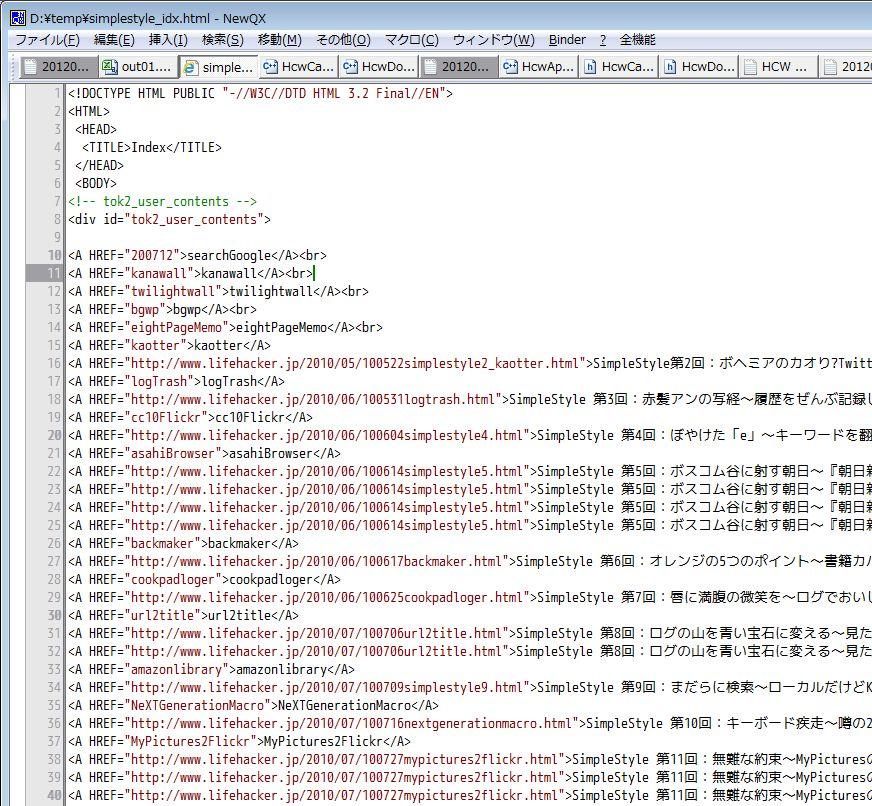
元の HTML ソース
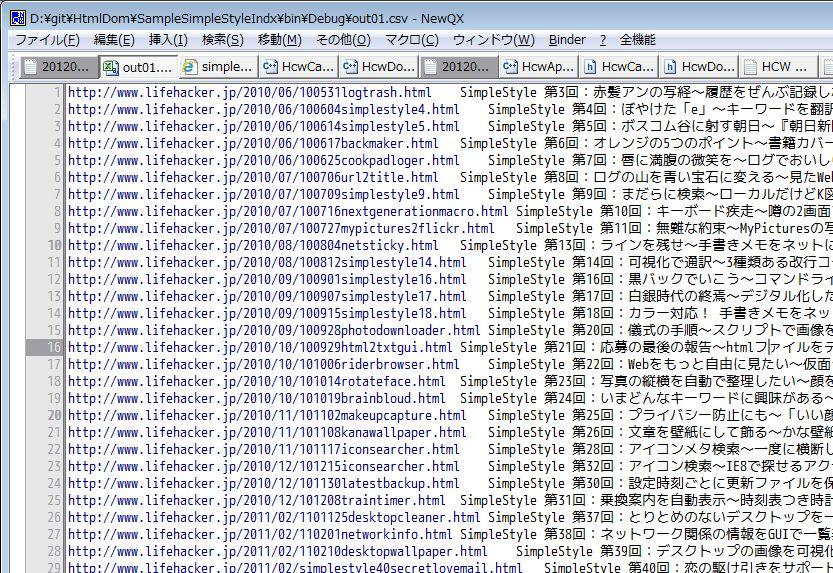
抽出後のソース
Excel に貼りつけ
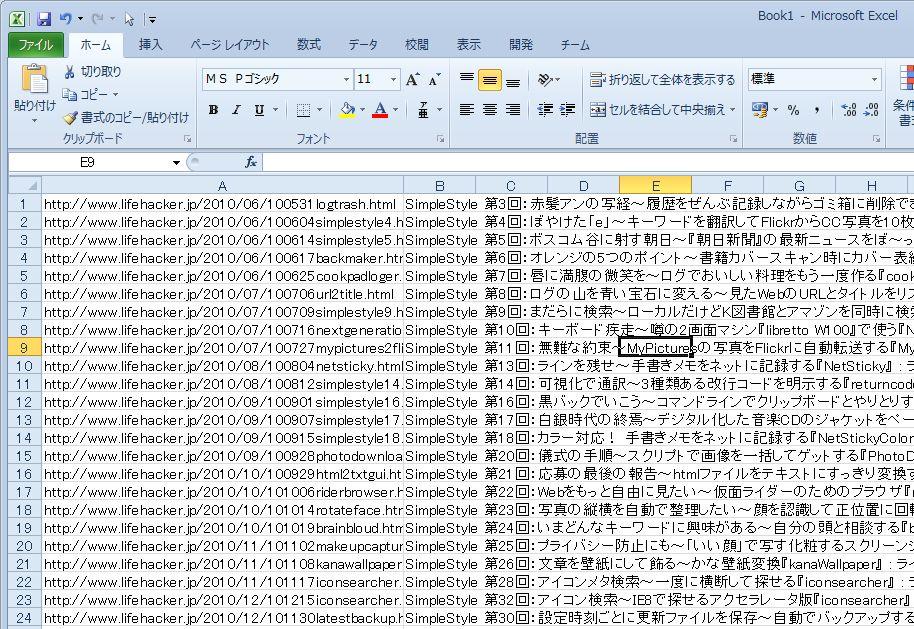
とする訳です。
実は元の HTML ソースは、
- タイトルが重複している
- 別のリンクも含まれている
な感じで、ちょっとプログラム的にはややこしいのです。そう、トライ&エラーが必要なのですね。
…が、HtmlDom を使うと、これぐらい簡単に書けます。
static void Main(string[] args)
{
string path = "\\temp\\simplestyle_idx.html";
var doc = new HtmlDocument().Load(path);
// Aタグで「SimpleStyle 第??回」を含むものを取得
var cont = new HtmlNavigator(doc)
.Where(n => n.TagName == "a" &&
n.Value.Contains("SimpleStyle 第"))
.Select(n => new { url = n % "href", text = n.Value })
.Distinct();
foreach (var n in cont)
{
Console.WriteLine("{0}\t{1}",
n.url, n.text);
}
}
まあ、これも一発で書けたわけではなくて何度か書き直している訳ですが、これぐらい短いとちまちまと設計を書いているよりも何かとコードを書いたほうが早い訳です。ええ、当然「設計」が必要な場合もあるので、それの話はまた別のときに。
HtmlDom は github で
https://github.com/moonmile/XmlDom
ちなみに、ライフハッカーの SimpleStyle の目次はもうちょっと考えます。元ソース自体が、第87回までしかないのでちょっと古いので。今は120回位です。
ちなみに、現状の HtmlDom は使い物にならない位遅いので、現在パフォーマンスを調節中です。どうやら、COM -> .NET 変換のところが遅すぎるみたいなので、C++/CLI で書き直せばよいかと模索中。

ちなみに、google 経由のクローリングとか、twitter のクローリングは api 経由じゃなくて HTML 経由でやるために HtmlDom を作っているってのもある訳で、ちまちまと WebBrowser を立てなくても WebClient 経由で出来るのでは?ってのが別な目的。
ただし、現状だと .NET/COM が遅いので、本格的に動かせるようになるのは C++/CLI で作ってから。