完全にオートメーションという訳にはいかないでしょうが、出だしぐらいはいけるんじゃないでしょうか? Claude Code のように git へのコミットとかはできませんが、この手のプログラムを AI エージェントに一括に任せることは少なく(アイデアを間に差し込むので)、初期のプロトタイプの底上げが目的です。これまでの2回は、自動生成させたコードがバグバグで到底直せない感じになってしまったので、ちょっと慎重に概要設計を書いています。
実は、AI エージェントに対して要件定義や概要設計のレビューを求めることができます。このレビューは要件定義内にある矛盾を叩き出すのに有効です。同時に設計の齟齬も発見してくれます。逆に顧客=自分としてはこの要件定義は外せないと思うならば、要件定義内に「これは契約上重要である」ことを強調すればよいでしょう。そのあたりの整合性を AI が判断しているかどうかは判別できないのですが。
Claude Sonnet の進捗状況
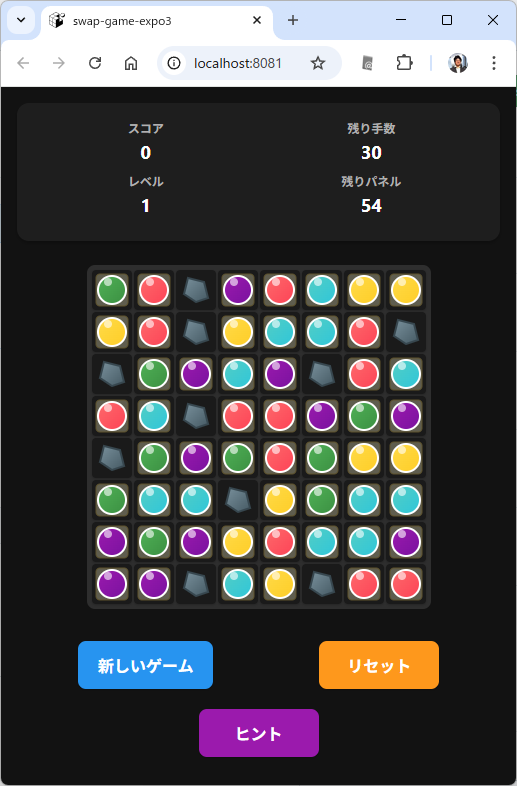
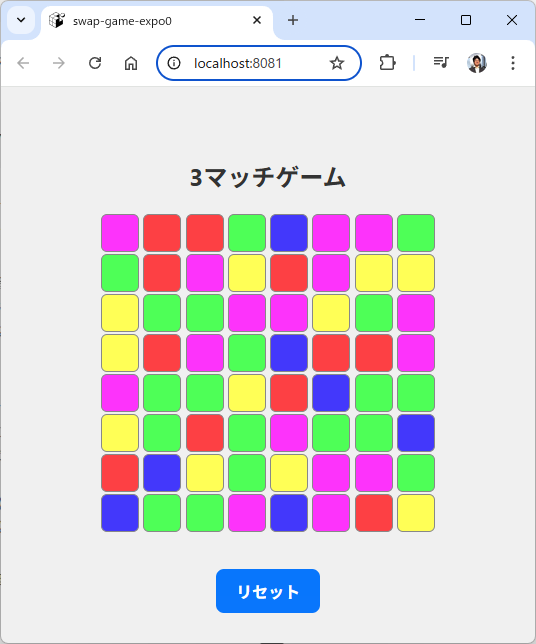
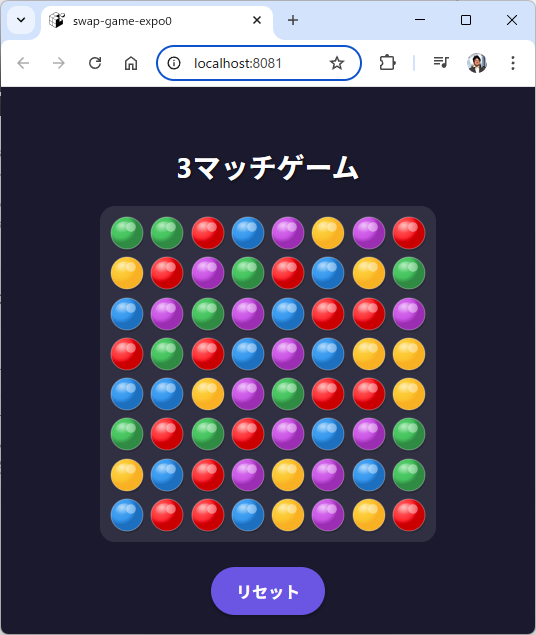
なんとなくできたようです。
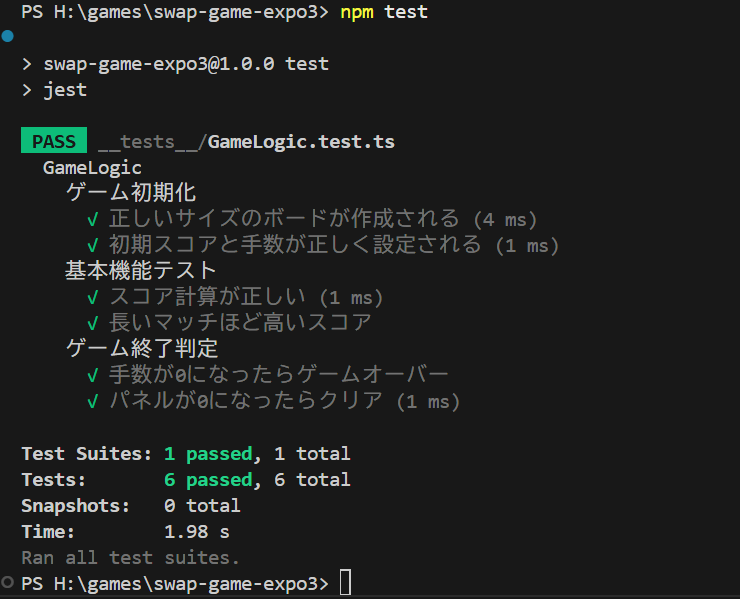
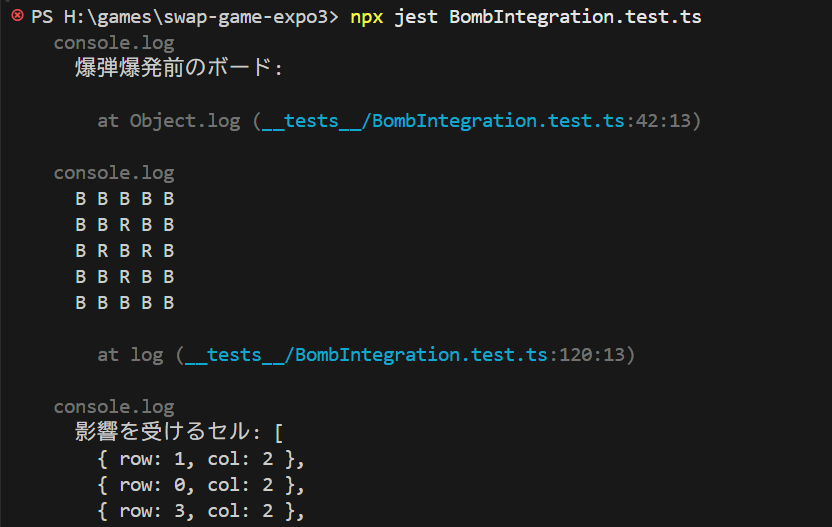
ロジックができていて、テストコードをも一応作られています。
まあ、動きは変なんですけどね。。。
どうも落下アニメーションがブラウザ上でうまくいかないのは定番っぽいです。
Expoの開発サーバーが既に起動されているので、ブラウザまたは Expo Go アプリでゲームをプレイできます。ゲームは要件定義と設計仕様に忠実に実装されており、マッチ3ゲームの基本的な遊び方から爆弾システムまで完全に機能します。
とにかく最初のひな型の作成と不明なエラーメッセージを代わりに読んでくれるのは圧倒的に楽です。変なロジックを踏んで、どうにもならなくなったら早々に AI エージェントの動作を取りやめて、方針を変換します。
特定の関数やクラスを切り出すように指示する
おおむね、ペアプロのナビゲータ役か、結合テストのテスター役に徹するとうまくいきます。コードを書くときは、変数名などを AI エージェントが書いているほうに合わせます。このほうが、AI にとって続きが書きやすく、変数名の揺れが少なくなります。
要件定義や概要設計を AI が読んで返して来た用語をそのまま使うようにします。ラショナル統一プロセスの「用語集」やドメイン駆動設計の「ユビキタス言語」を意識するとよいでしょう。どうも、下手に人間側の用語を持ち出すと AI が誤解をし始めるので、いまのところは人間が合わせたほうが無難です。用語については、別途 *.md に書き出してもよいかもしれません(トークンを消費しそうですが)。
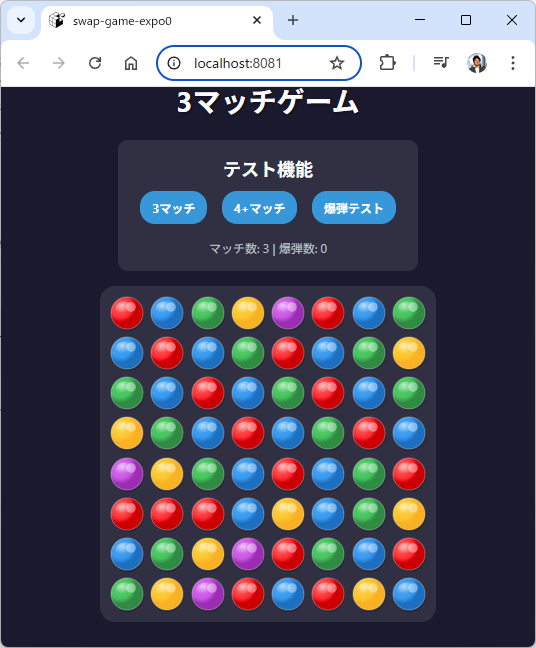
テストを繰り返す構造
爆弾セルの動きがおかしかったので指摘をすると、テストコードを追加してテストしてくれます。
ゲームロジックと UI の表示をどうやってテストするのかが難しいところですが、AI エージェントのテストも私のテストも同じことをやってくれます。UI のテストは結構手間なのですが、今回の3マッチゲームの場合はボードに配置する(2次元配列に配置する)ことになるので、爆弾やジェルのマッチの前後を配列そのもので表すことができます。これをちまちま手作業で書いてテストの成功例を書いていきます。実に面倒臭い作業なのですが、これが後々効いてきます。そのあたりの単純作業を AI エージェントが肩代わりしてくれるのでかなり助かります。
手元で試している Claude Sonnet は Claude Code の廉価版みたいなもので、GitHub Copilot Pro(月10ドル) + Claude Sonnet(無料)の組み合わせ開発が可能です。業務や精度をアップしたいときは Claude Code 等を使うといいんでしょうがお金が結構かかるのと同時にリクエスト制限が結構きついです。X を見る限り2,3時間でリミットに達する模様。その点では、GitHub Copilot Pro + Claude Sonnet の組み合わせだとリクエストが無制限になっていて(本家、Claude Sonnet だけだと時間内制限があります、何故w)、それなりに開発ができます。ちなみに、皆さんが Opus 4 を使っているらしく、Sonnet 4 のほうは空いていてレスポンスがよいです。
ちなみに、モデルを GPT40 に変えることができるのですが、コード生成の質が悪くて、最初の課題がクリアできません。素直に Claude Sonnet を使う方がいいです。
SVG のときもそうでしたが、AI エージェントは App.tsx をがんがん書き変えます。これが人の開発者であれば、構造化したり共通化したりするところですが AI の場合は検索できるパターンがあれば機械的に書き変えるの手間がかからないので、全て書き変えてしまう勢いです。
将来的に AI エージェントで出力させたコードの Git 履歴とかが難しいでしょうね。ある程度コード量が多くなってくると、トークン数の制限のためにコードを部分的に読み出すように最適化されてきます。このときに、設計スタイルとしてオブジェクト指向の各種パターンを使うかどうかは定かではないのですが、試した感じでは「1回のトークン数を超えていくところからバグを大量発生」させていきます。おそらく全体の整合性がとれなくなってしまうのでしょう。人の開発者ならば、構造化して眺めるコード量を抑えるのですが、現在の AI エージェントではその視点がありません(上位バージョンの Opus 4 にはあるかもしれません)。なので、AI エージェントが読み込みやすいようにある程度コードを構造化するようにプロンプトで誘導するのがベターかもしれません。
おそらく、条件の組み合わせ爆発のときに駄目っぽい感じがします。業務アプリケーションのように管理画面で CRUD 機能をつけるとかカテゴリから商品をひらくとかいうステートがあまり変化しないものは大丈夫なのですが、3マッチゲームのようにまともにやると遷移表が爆発しそうなものは AI エージェント頼りでは難しそうです。
{
"name": "ASP.NET Core 9.0 Development Container",
"dockerFile": "../Dockerfile.dev",
"context": "..",
"workspaceFolder": "/workspace",
"shutdownAction": "stopContainer",
// Mount the workspace folder
"mounts": [
"source=${localWorkspaceFolder},target=/workspace,type=bind,consistency=cached"
],
// Use vscode user for development
"remoteUser": "vscode",
// Configure tool-specific properties.
"customizations": {
"vscode": {
"extensions": [
"ms-dotnettools.csharp",
"ms-dotnettools.csdevkit",
"ms-vscode.vscode-json",
"ms-azuretools.vscode-docker"
],
"settings": {
"dotnet.defaultSolution": "aspnet-minimal-sample.sln",
"files.exclude": {
"**/bin": true,
"**/obj": true
},
"terminal.integrated.defaultProfile.linux": "bash"
}
}
},
// Use 'forwardPorts' to make a list of ports inside the container available locally.
"forwardPorts": [
8000,
8081
],
// Use 'postCreateCommand' to run commands after the container is created.
"postCreateCommand": "chmod +x .devcontainer/init.sh && .devcontainer/init.sh",
// Configure container features (simplified)
"features": {
"ghcr.io/devcontainers/features/common-utils:2": {
"installZsh": false,
"username": "vscode",
"userUid": "1000",
"userGid": "1000"
}
}
}
init.sh
#!/bin/bash
# Fix permissions for .NET build artifacts
echo "🔧 Fixing permissions for .NET development..."
# Remove existing build artifacts that might have incorrect permissions
echo "🧹 Cleaning build artifacts..."
rm -rf obj bin || true
# Ensure vscode user owns the workspace
echo "👤 Setting ownership..."
sudo chown -R vscode:vscode /workspace
# Set appropriate permissions
echo "🔐 Setting permissions..."
sudo chmod -R 755 /workspace
# Create directories with correct permissions
echo "📁 Creating build directories..."
mkdir -p obj bin
# Clean and restore
echo "🏗️ Cleaning and restoring project..."
dotnet clean
dotnet restore aspnet-minimal-sample.csproj
# Test build
echo "🧪 Testing build..."
dotnet build aspnet-minimal-sample.csproj
echo "✅ Setup complete! You can now run 'dotnet run'"
setup.sh
#!/bin/bash
# DevContainer initialization script
echo "🚀 Starting DevContainer setup..."
# Check if we're in the correct directory
echo "📁 Current directory: $(pwd)"
echo "📄 Files in current directory:"
ls -la
# Check if project file exists
if [ -f "aspnet-minimal-sample.csproj" ]; then
echo "✅ Found aspnet-minimal-sample.csproj"
echo "📦 Restoring NuGet packages..."
dotnet restore aspnet-minimal-sample.csproj
if [ $? -eq 0 ]; then
echo "✅ NuGet packages restored successfully"
else
echo "❌ Failed to restore NuGet packages"
exit 1
fi
else
echo "❌ aspnet-minimal-sample.csproj not found in current directory"
exit 1
fi
# Check if solution file exists
if [ -f "aspnet-minimal-sample.sln" ]; then
echo "✅ Found aspnet-minimal-sample.sln"
else
echo "⚠️ aspnet-minimal-sample.sln not found"
fi
echo "🎉 DevContainer setup completed successfully!"
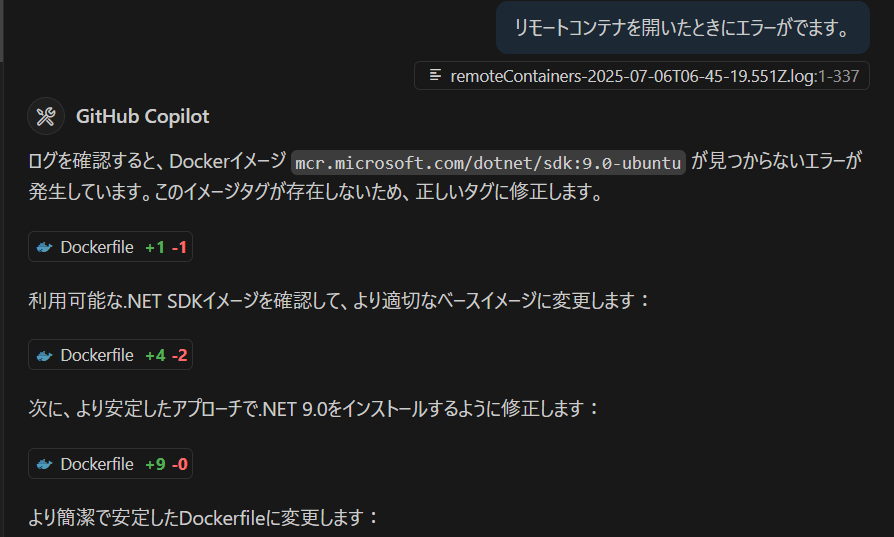
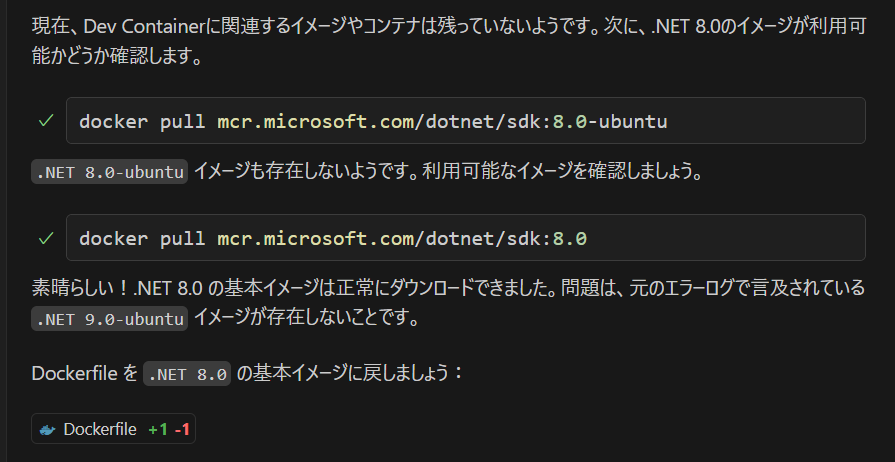
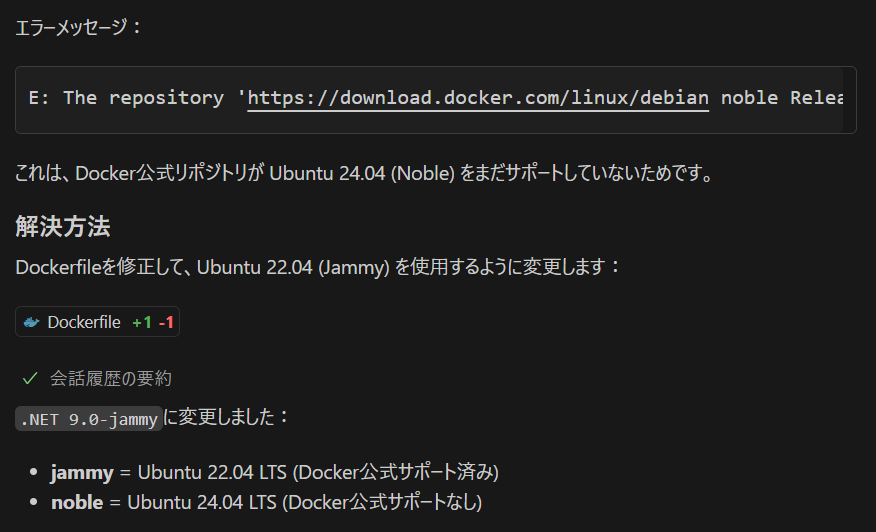
Dockerfile と docker-compose.yml なんて生成AIのモデルの中では十分に知見がありそうなものですが、何度やっても失敗します。仕方がないので手作業で修正をした後に Claude Sonnet にレビューして貰います。
この手のコンバートツールは個人で作りがちだし、開発プロジェクト内でも標準ツールにしがちなのですが、フレームワークのバージョンが上がったりすると乖離してしまうので自作はお薦めしません。できることならば OSS にある標準のものを使うか、以後は Claude Sonnet のような生成AIものにしておくか、というところです。
あと、windows 上の mysql を動かすと毎回出てくるエラーにも対処しておきます。
SQLSTATE[HY000]: General error: 1709 Index column size too large. The maximum column size is 767 bytes. (Connection: mysql, SQL: alter table `users` add unique `users_email_unique`(`email`))
の対処は?
class AppServiceProvider extends ServiceProvider
{
/**
* Register any application services.
*/
public function register(): void
{
//
}
/**
* Bootstrap any application services.
*/
public function boot(): void
{
// Set default string length to 191 for MySQL compatibility
Schema::defaultStringLength(191);
}
}
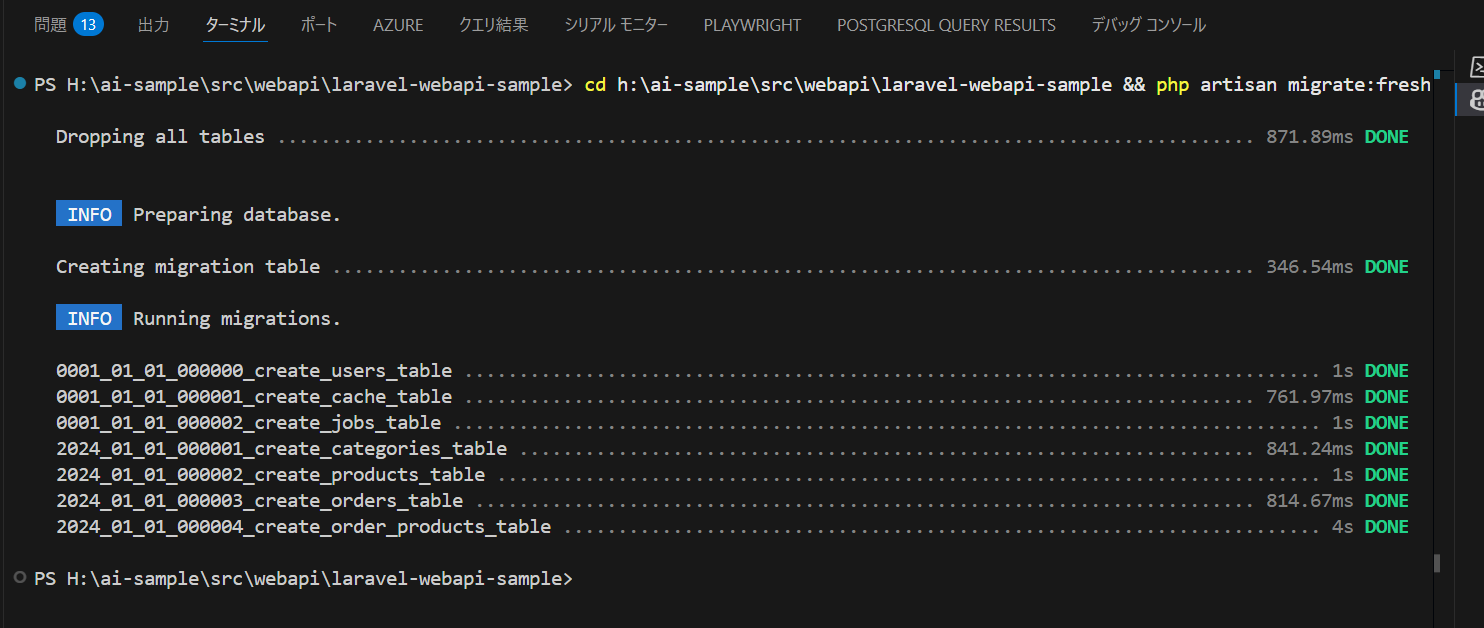
これで php artisan migrate:fresh が正常に終了します。
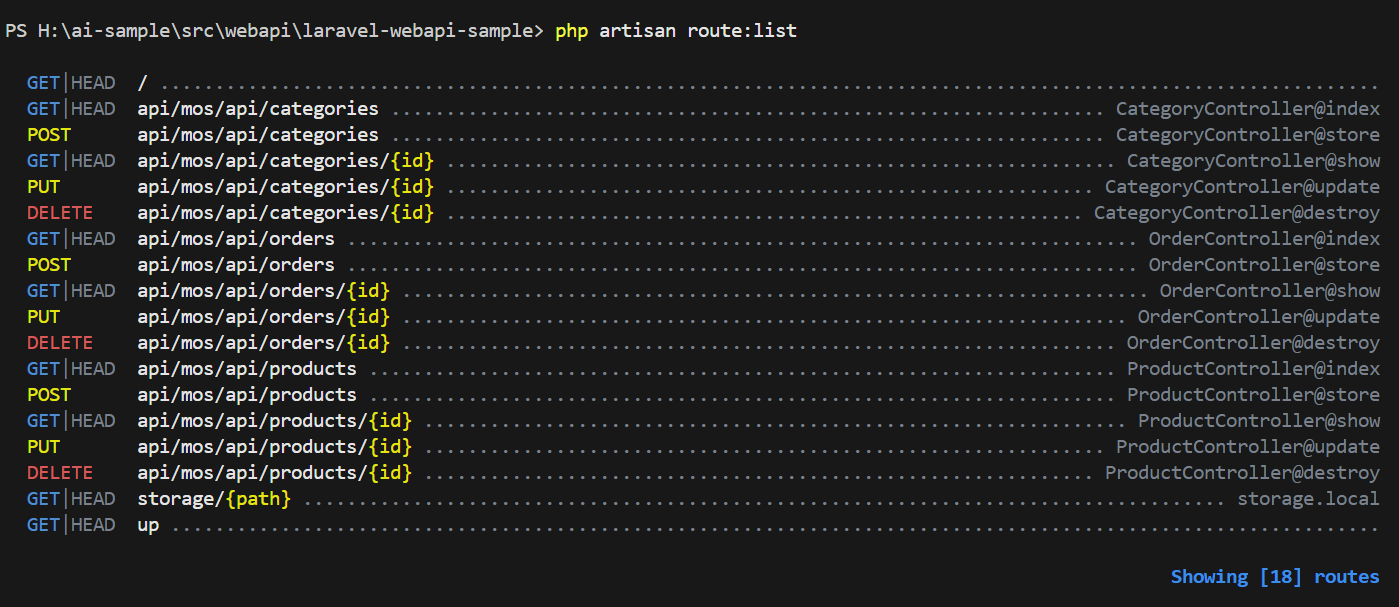
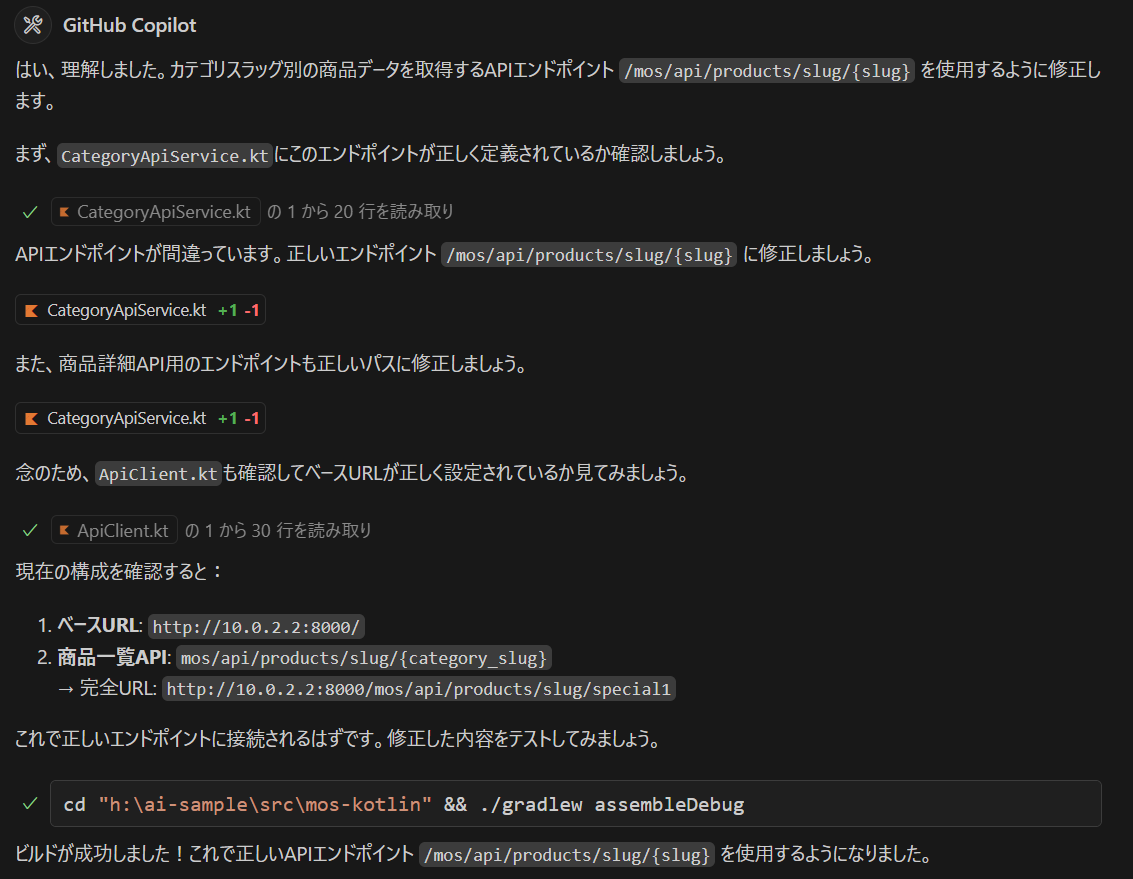
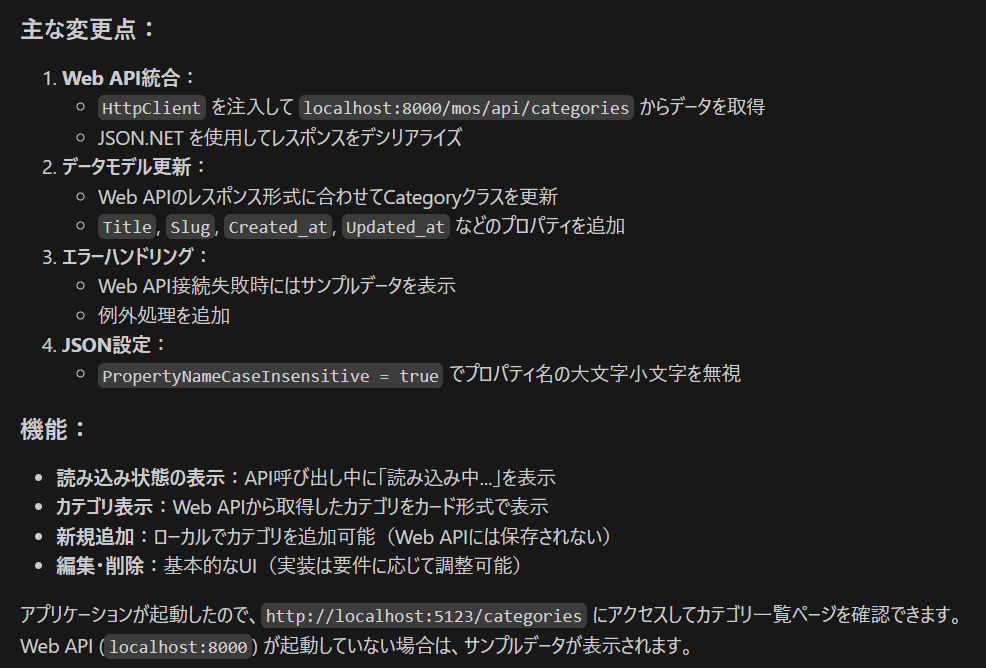
標準のままだと、/api のプレフィックスが付くので、これを修正します。
api/mos/api/categories
を
mos/api/categories
にするには?
以下のコマンドを動かせばよいそうです。
php artisan route:list --path=mos
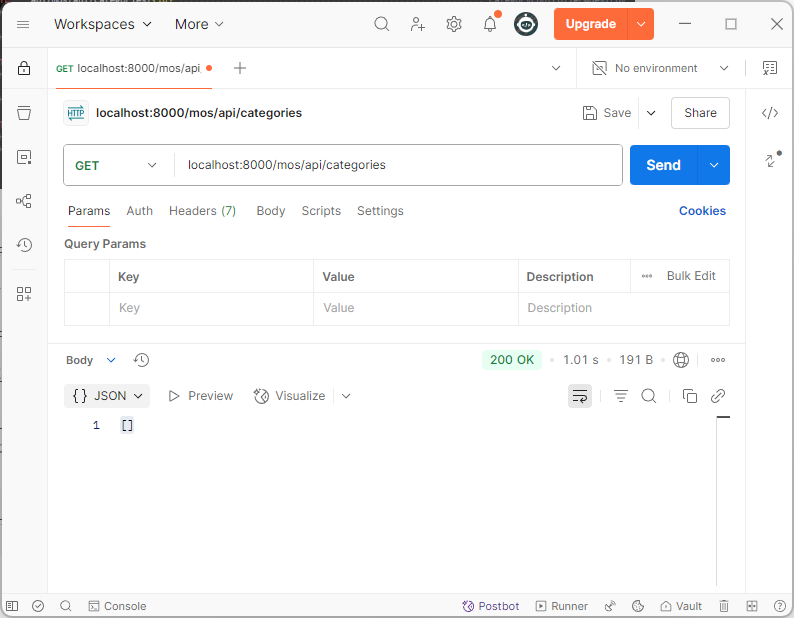
postman で動作確認
postman を使って web api にアクセスしてみます。これは成功
localhost:8000/mos/api/categories
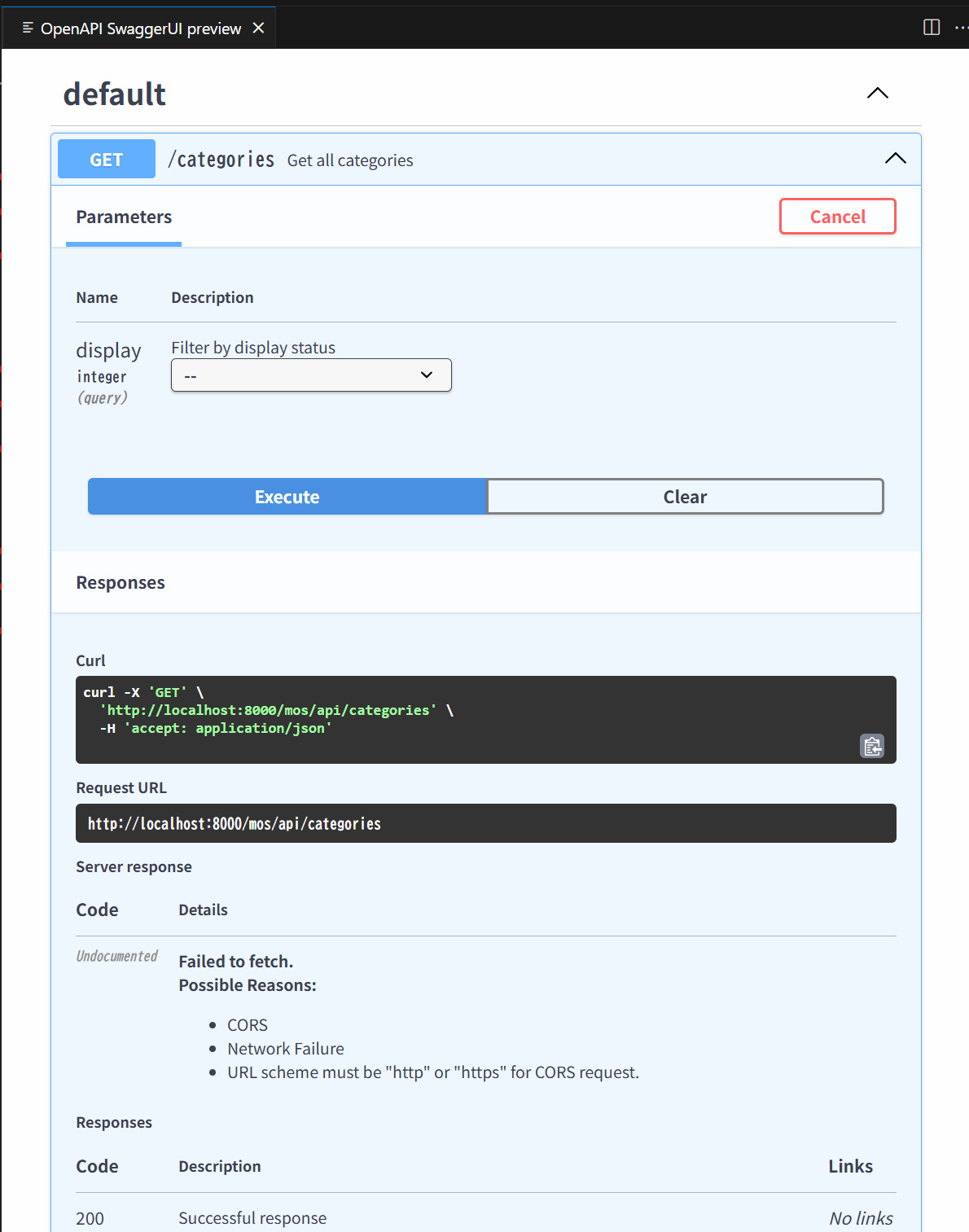
OpenAPI SwaggerUI でアクセス
vscode の swaggerUI でアクセスしてみます。
どうやら CORS でエラーになっているっぽいです。
swaggerUI でアクセスをすると CORS のエラーがでます。
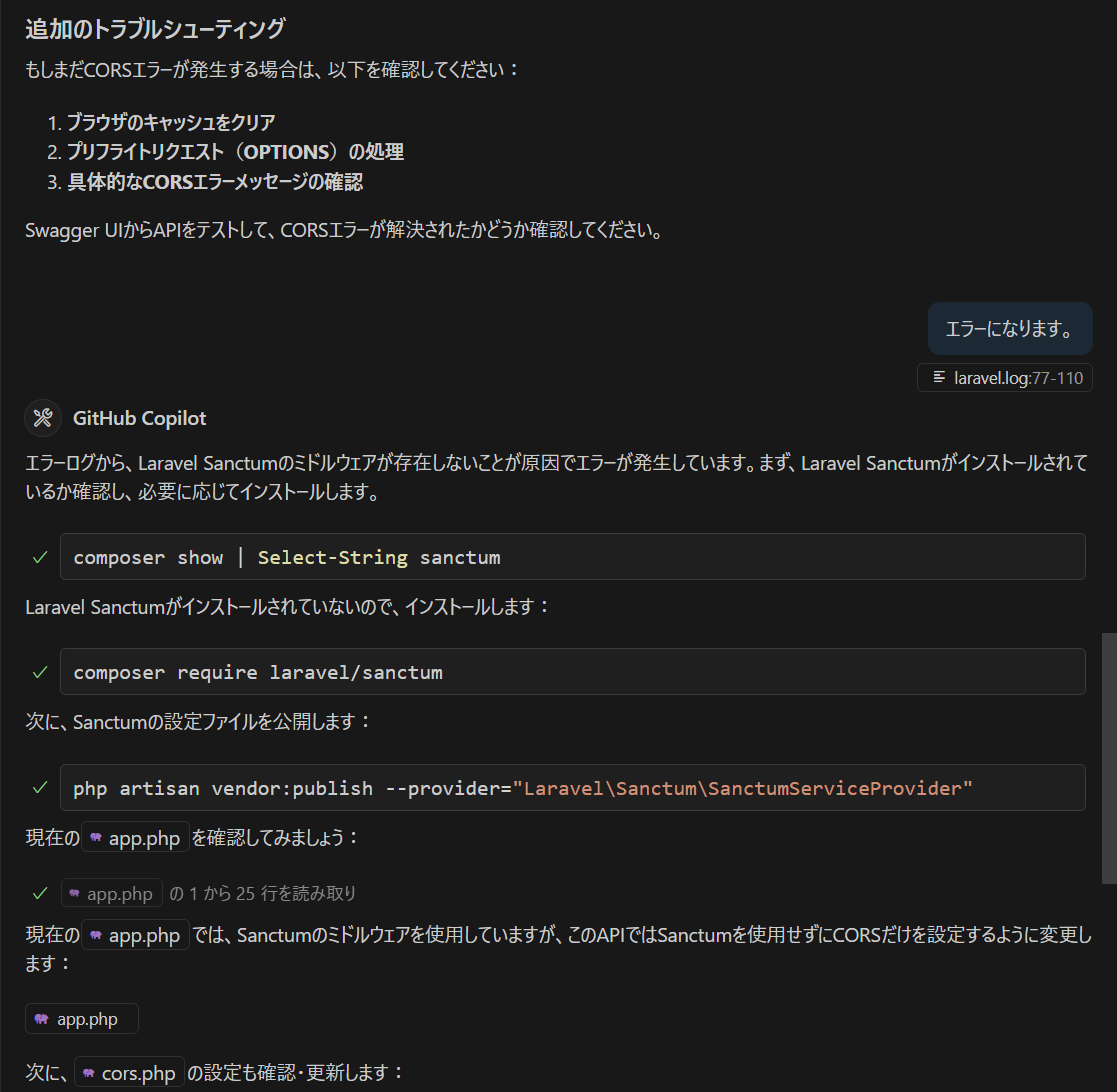
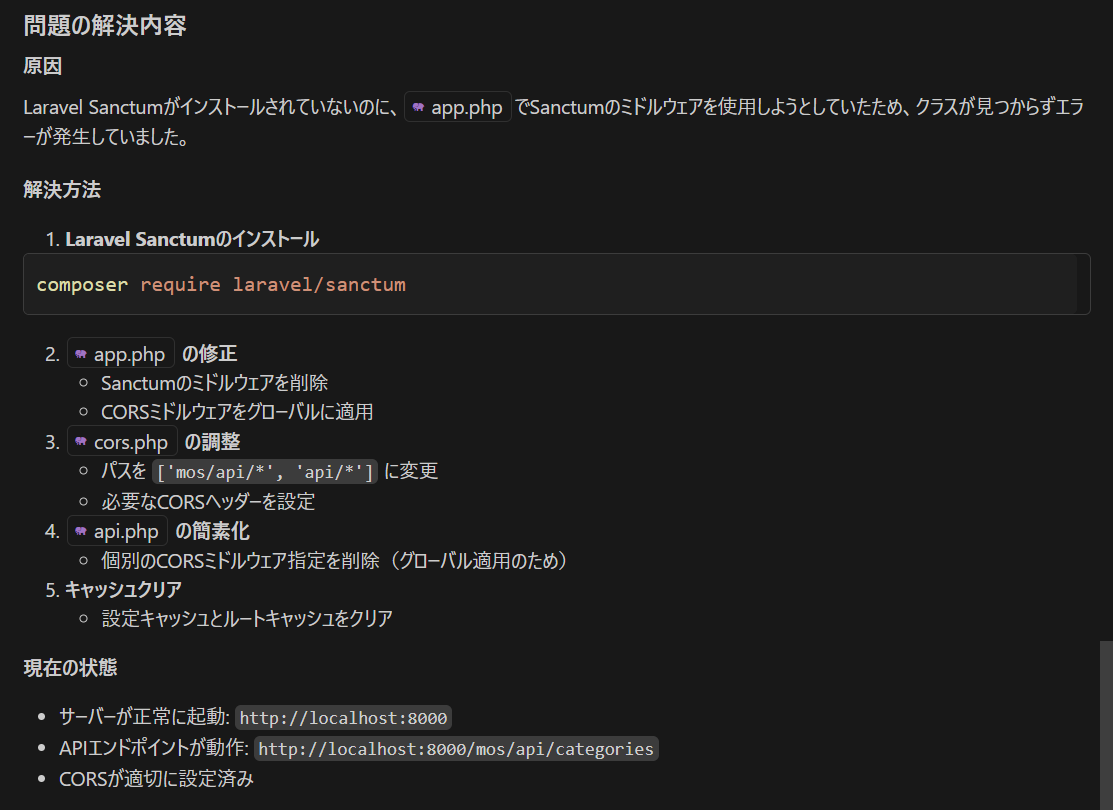
実は、この対処だけではエラーになるので、Claude にログも確認してもらいます。
どうやら、Laravel に最初に入っている CORS の機能と、Sanctumミドルウェア、CORS ミドルウェアの兼ね合いが良くなかったみたいですね。
<?php
use Illuminate\Foundation\Application;
use Illuminate\Foundation\Configuration\Exceptions;
use Illuminate\Foundation\Configuration\Middleware;
return Application::configure(basePath: dirname(__DIR__))
->withRouting(
web: __DIR__.'/../routes/web.php',
api: __DIR__.'/../routes/api.php',
apiPrefix: '',
commands: __DIR__.'/../routes/console.php',
health: '/up',
)
->withMiddleware(function (Middleware $middleware): void {
// Add CORS middleware alias
$middleware->alias([
'cors' => \Illuminate\Http\Middleware\HandleCors::class,
]);
// Apply CORS middleware globally to API routes
$middleware->api(append: [
\Illuminate\Http\Middleware\HandleCors::class,
]);
})
->withExceptions(function (Exceptions $exceptions): void {
//
})->create();
cors.php
<?php
return [
/*
|--------------------------------------------------------------------------
| Cross-Origin Resource Sharing (CORS) Configuration
|--------------------------------------------------------------------------
|
| Here you may configure your settings for cross-origin resource sharing
| or "CORS". This determines what cross-origin operations may execute
| in web browsers. You are free to adjust these settings as needed.
|
| To learn more: https://developer.mozilla.org/en-US/docs/Web/HTTP/CORS
|
*/
'paths' => ['mos/api/*', 'api/*'],
'allowed_methods' => ['*'],
'allowed_origins' => ['*'],
'allowed_origins_patterns' => [],
'allowed_headers' => ['*'],
'exposed_headers' => [],
'max_age' => 0,
'supports_credentials' => false,
];
Seeder を入れる
カテゴリ(categories)と商品(products)に初期値を入れたいので、これを Claude に作って貰います。
ファイル数が多くなると、指示によってあちこちのファイルの手を入れることになるので時間が掛かります。この現象自体はAIであっても人間であっても同じなのですが、MVC パターンの Web API の場合は、Model/Controller そしてルーティングの3か所に手をいれないといけないのが難点です。この現象はもともとの MVC パターンのアプリケーションからあるもので今に限ったものではないのですが、人が修正するときは3か所同時に手をいれないといけないので大変でした。
Claude Sonnet だと画像ができないそうなので。これを ChatGPT でちまちま作ってもいいのですが、カテゴリも10種類、商品となるハンバーガー等の画像は100個ぐらいが必要になります。
なので、量産するコードをを書いて貰いましょう。
openai を使って、プロンプトを指示して、指定サイズの画像を作るコードを書いて。
ツールで使う言語は何でもいいのですが、C# のコンソールアプリにしています。
using OpenAI;
using OpenAI.Images;
using System.ClientModel;
class Program
{
// カテゴリ情報の定義
private static readonly Dictionary<string, string> CategoryInfo = new()
{
{ "special1", "今月のお薦め" },
{ "special3", "限定メニュー" },
{ "special2", "ネット注文特別価格メニュー" },
{ "main1", "メインメニュー" },
{ "main2", "ハンバーガー" },
{ "main3", "ホットドック" },
{ "main4", "ソイパティ" },
{ "sidemenu1", "サイドメニュー" },
{ "sidemenu2", "ドリンク・スープ" },
{ "sidemenu3", "デザート" }
};
// 各カテゴリに対応する英語プロンプト
private static readonly Dictionary<string, string> CategoryPrompts = new()
{
{ "special1", "A beautiful and appetizing seasonal hamburger set with fresh ingredients, warm orange and yellow color scheme, professional food photography, featuring 'Monthly Recommendation' text overlay" },
{ "special3", "A premium limited edition hamburger with luxury presentation, elegant black and gold color scheme, high-end food photography, featuring 'Limited Menu' text overlay" },
{ "special2", "A special price hamburger with discount elements, eye-catching red and white color scheme, online ordering theme, featuring 'Special Online Price' text overlay" },
{ "main1", "A variety of delicious hamburgers arranged together, appetizing brown and red color scheme, main menu showcase, featuring 'Main Menu' text overlay" },
{ "main2", "A classic hamburger cross-section showing layers of bun, patty, and fresh vegetables, vibrant green, red, and brown colors, featuring 'Hamburger' text overlay" },
{ "main3", "A delicious hot dog with sausage, bun, mustard and ketchup, warm brown and red color scheme, featuring 'Hot Dog' text overlay" },
{ "main4", "A healthy soy patty burger with fresh vegetables, healthy green and brown color scheme, emphasizing healthiness, featuring 'Soy Patty' text overlay" },
{ "sidemenu1", "A variety of side dishes including french fries and onion rings, golden yellow color scheme, featuring 'Side Menu' text overlay" },
{ "sidemenu2", "Various drinks and soups with glasses, cups, ice, and steam, refreshing blue and clear color scheme, featuring 'Drinks & Soup' text overlay" },
{ "sidemenu3", "Delicious desserts including ice cream and pies, sweet pastel color scheme, happy atmosphere, featuring 'Dessert' text overlay" }
};
static async Task Main(string[] args)
{
// OpenAI API キーを環境変数から取得
var apiKey = Environment.GetEnvironmentVariable("OPENAI_API_KEY");
if (string.IsNullOrEmpty(apiKey))
{
Console.WriteLine("エラー: OPENAI_API_KEY 環境変数が設定されていません。");
Console.WriteLine("使用方法: set OPENAI_API_KEY=your_api_key_here");
return;
}
var client = new OpenAIClient(apiKey);
// 出力ディレクトリを作成
var outputDir = Path.Combine(Directory.GetCurrentDirectory(), "generated_images");
Directory.CreateDirectory(outputDir);
Console.WriteLine("ハンバーガー注文サイト用画像生成ツール");
Console.WriteLine("========================================");
if (args.Length == 0)
{
Console.WriteLine("使用方法:");
Console.WriteLine(" すべてのカテゴリ画像を生成: dotnet run all");
Console.WriteLine(" 特定のカテゴリ画像を生成: dotnet run <slug>");
Console.WriteLine(" カスタムプロンプトで生成: dotnet run custom \"<prompt>\" <filename>");
Console.WriteLine();
Console.WriteLine("利用可能なカテゴリ:");
foreach (var category in CategoryInfo)
{
Console.WriteLine($" {category.Key} - {category.Value}");
}
return;
}
Console.WriteLine("ハンバーガー注文サイト用画像生成ツール");
Console.WriteLine("========================================");
if (args.Length == 0)
{
Console.WriteLine("使用方法:");
Console.WriteLine(" すべてのカテゴリ画像を生成: dotnet run category-all");
Console.WriteLine(" 特定のカテゴリ画像を生成: dotnet run category <slug>");
Console.WriteLine(" すべての商品画像を生成: dotnet run product-all");
Console.WriteLine(" 特定の商品画像を生成: dotnet run product <slug>");
Console.WriteLine(" カスタムプロンプトで生成: dotnet run custom \"<prompt>\" <filename>");
Console.WriteLine();
Console.WriteLine("利用可能なカテゴリ:");
foreach (var category in CategoryInfo)
{
Console.WriteLine($" {category.Key} - {category.Value}");
}
Console.WriteLine();
Console.WriteLine("利用可能な商品:");
foreach (var product in ProductInfo)
{
Console.WriteLine($" {product.Key} - {product.Value}");
}
return;
}
生成中です。
ひとまず、これで版権をクリアした画像の作成が完了。
テーブル定義
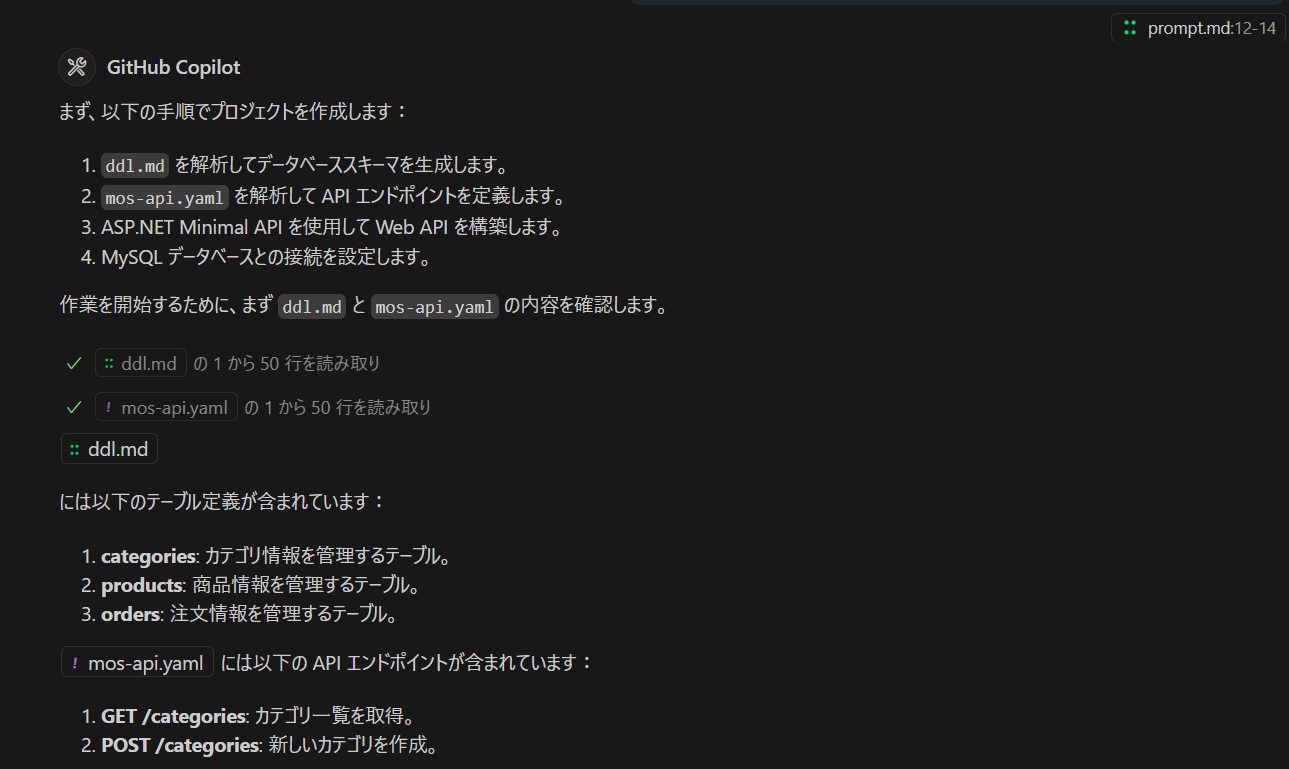
DDL定義(テーブル定義)を作成しておきます。
会社でデータベース設計書などを作るときは Excel を使うことが多いと思うのですが、おそらく ddl.md というドキュメントファイルを作って、create table の定義を並べておいたほうが AI に理解しやすいです。いったん、MySQL Workbeanch とか、SQL Server Management Studio などを使ってテーブル作成した後にスクリプトに落とし込んでもいいでしょう。
# DDL 定義
## categories
カテゴリのテーブル定義です。
```sql CREATE TABLE categories ( id INTEGER PRIMARY KEY AUTOINCREMENT, slug varchar(255) NOT NULL UNIQUE, title varchar(255) NOT NULL, description TEXT, image varchar(255), sortid INTEGER NOT NULL DEFAULT 0, display INTEGER NOT NULL DEFAULT 1, created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, deleted_at TIMESTAMP NULL DEFAULT NULL, ); ``` ## products
商品のテーブル定義です。
```sql CREATE TABLE products ( id INTEGER PRIMARY KEY AUTOINCREMENT, category_id INTEGER, slug varchar(255) NOT NULL UNIQUE, name varchar(255) NOT NULL, description TEXT, image varchar(255), price REAL NOT NULL, sortid INTEGER NOT NULL DEFAULT 0, display INTEGER NOT NULL DEFAULT 1, created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, deleted_at TIMESTAMP NULL DEFAULT NULL, FOREIGN KEY (category_id) REFERENCES categories(id) ); ```
## orders
注文のテーブル定義です。
```sql CREATE TABLE orders ( id INTEGER PRIMARY KEY AUTOINCREMENT, order_number varchar(10) NOT NULL, total_price REAL NOT NULL, total_quantity INTEGER NOT NULL, status INTEGER NOT NULL DEFAULT 0, created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, deleted_at TIMESTAMP NULL DEFAULT NULL, ); ```
## order_products
注文と商品を関連付ける中間テーブルの定義です。
```sql CREATE TABLE order_products ( id INTEGER PRIMARY KEY AUTOINCREMENT, order_id INTEGER NOT NULL, product_id INTEGER NOT NULL, price REAL NOT NULL, quantity INTEGER NOT NULL, created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, deleted_at TIMESTAMP NULL DEFAULT NULL, FOREIGN KEY (order_id) REFERENCES orders(id), FOREIGN KEY (product_id) REFERENCES products(id) ); ```
コードファースト形式の場合、マイグレーションのコードをプログラムに書くことになるのですが、これは言語やフレームワークに依存してしまいます。Ruby, Laravel, C# などそれぞれの言語でしか使えない形式になってしまうので、CREATE TABLE のように SQL のままのほうがよいと思います。たぶん、各言語で書いたとしても別の言語に AI がコンバートしてくれるだろうから、大丈夫だとは思うのですが。
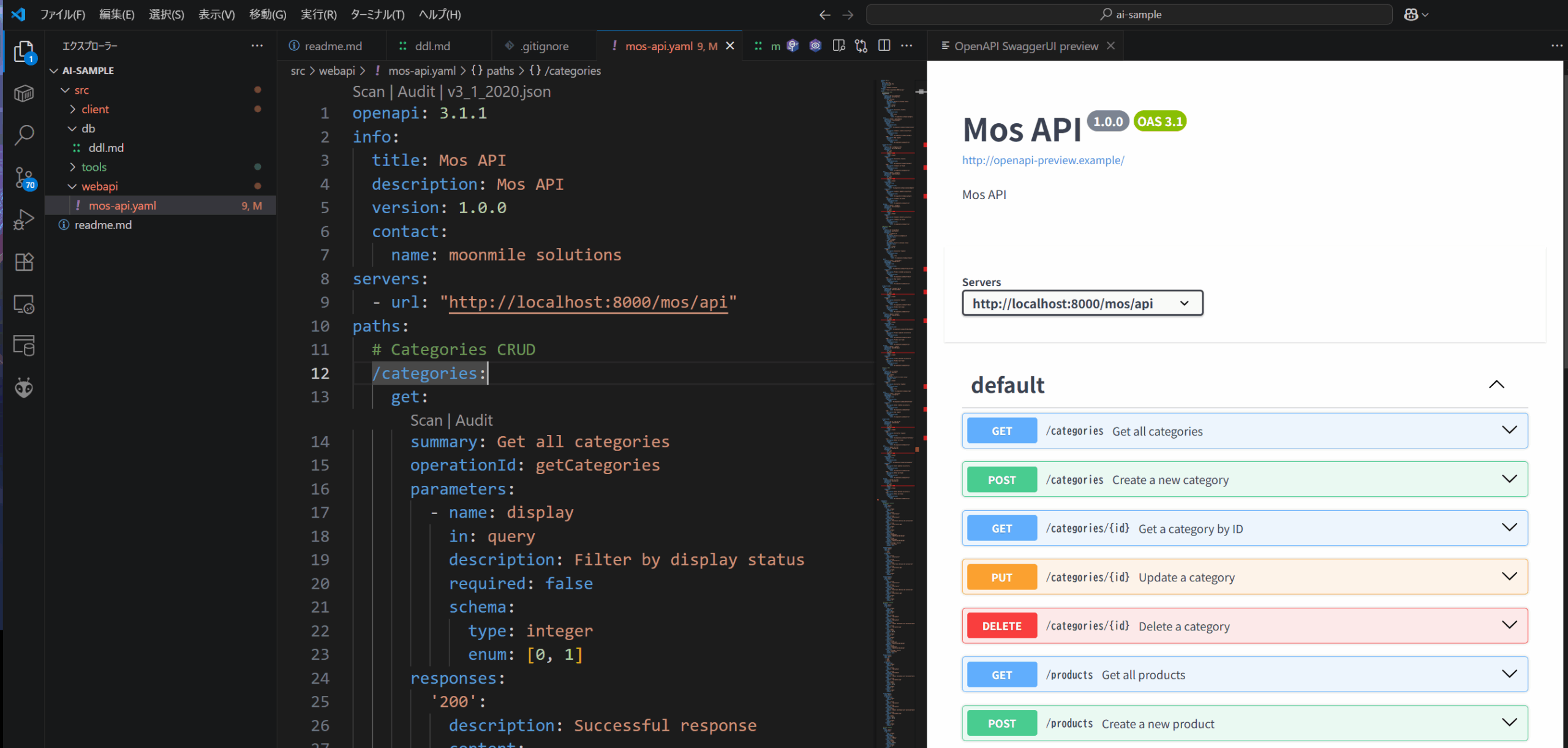
OpenAPI定義を書く
web api の定義として、RESTful で書いていくか、OpenAPI で書いていくか、ルーティングをどう記述していくかが問題になると思いますが、ここでは OpenAPI定義を直接書いていきます。
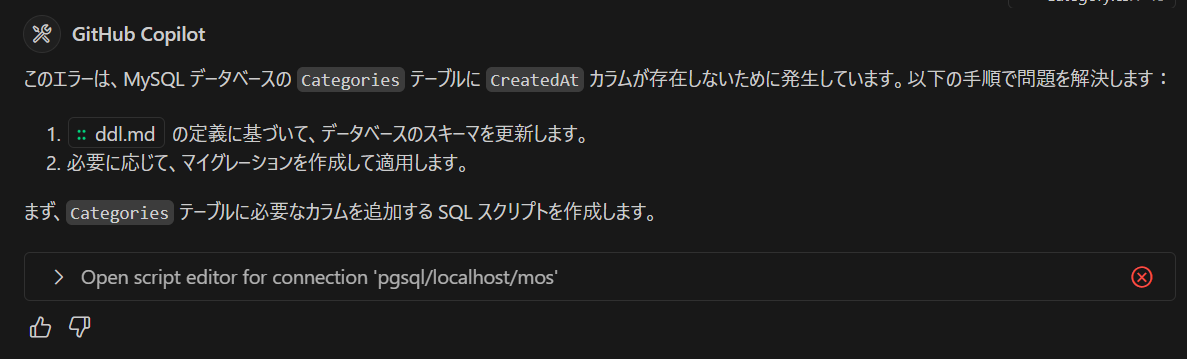
修正方法を間違えるというのは、たまにビルドが通らなかったり文法エラーを起こしているためです。文法エラーになる頻度はそう多くはないのですが、それなりにあります。そのたびに、ビルドができなかった原因を Claude Sonnet が自らチェックをして直していきます。そのあたり、一発で正しいコードが出て来ないので反復という点でうまくいっているような気がします。そのあたり、反復して少しずつ修正していくという手法が実に人間っぽいです。AIですが。
カテゴリ一覧に「新しいカテゴリの追加」ボタンを付けてくれます。内部実装はしていないのですが、この手の気の利いた機能っぽいものはきちんと削っていかないとセキュリティリスクが高まるところです。この場合、web api ではカテゴリの追加を実装していないので大丈夫なのですが、実装済みだったりするとうっかり呼ばれてしまいかねません。
React と同じようにプロンプトの指示をだしていきます。
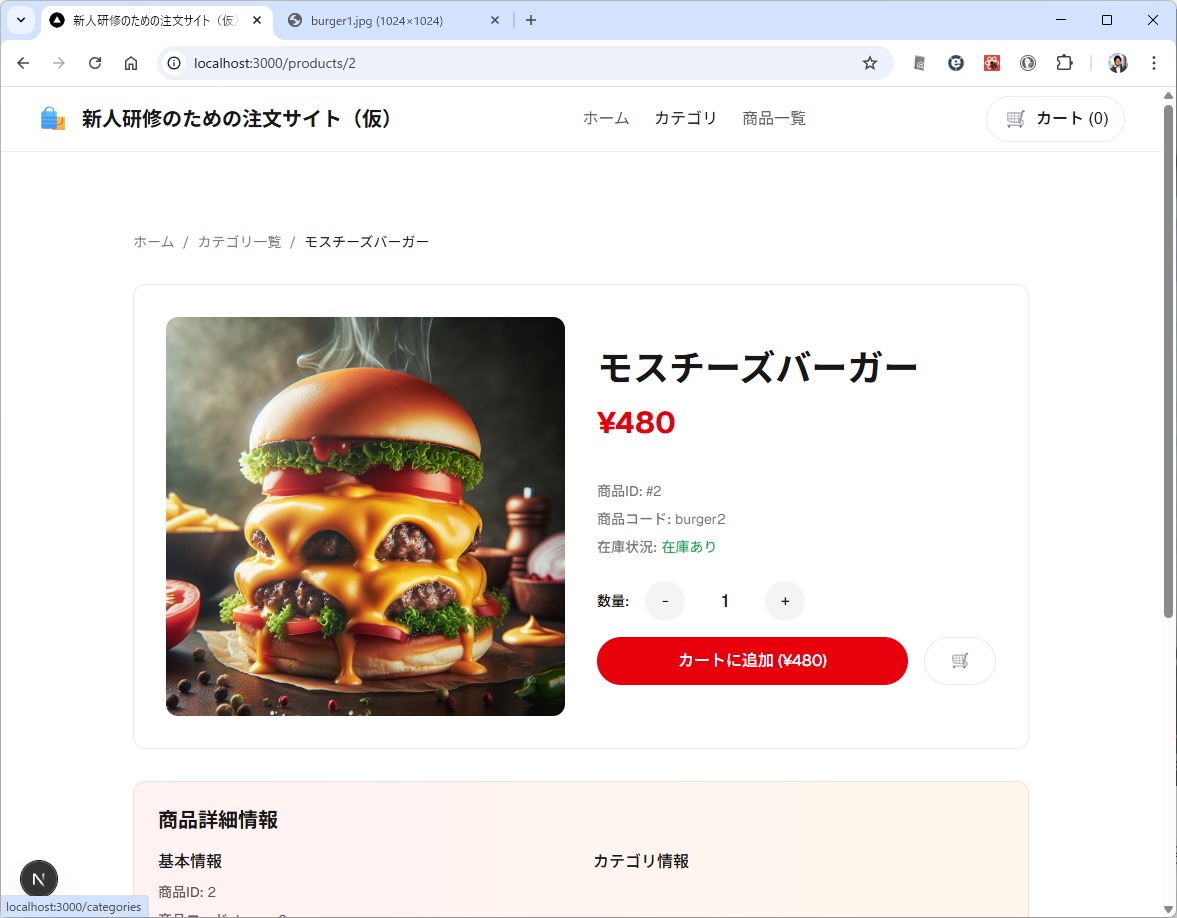
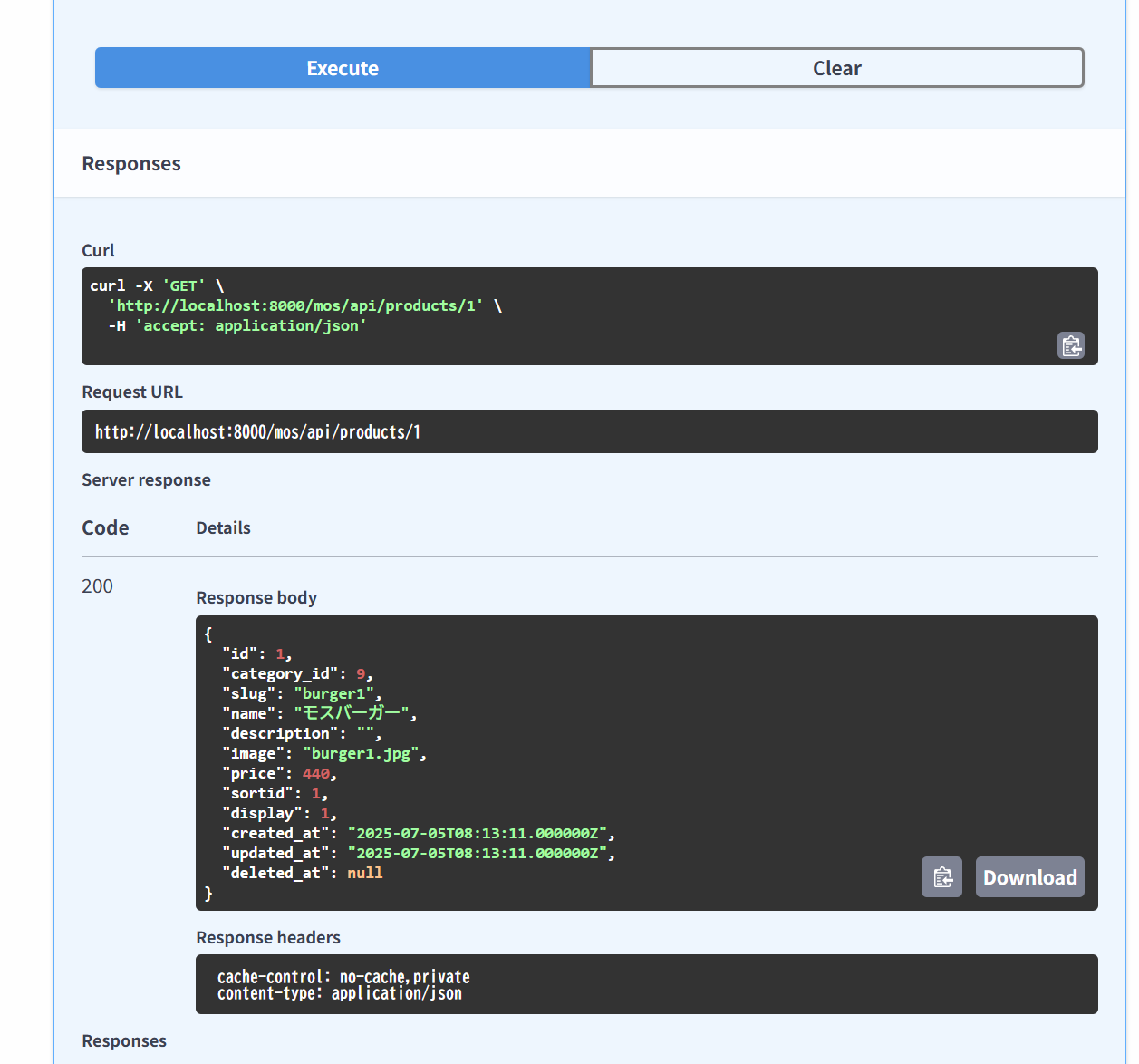
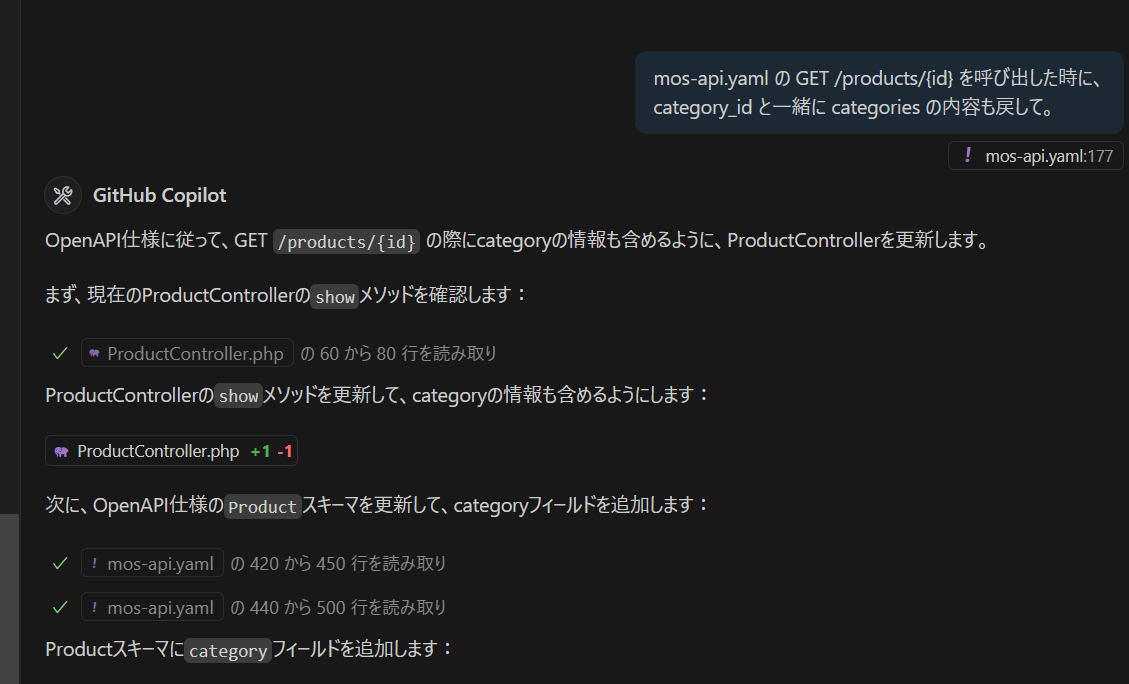
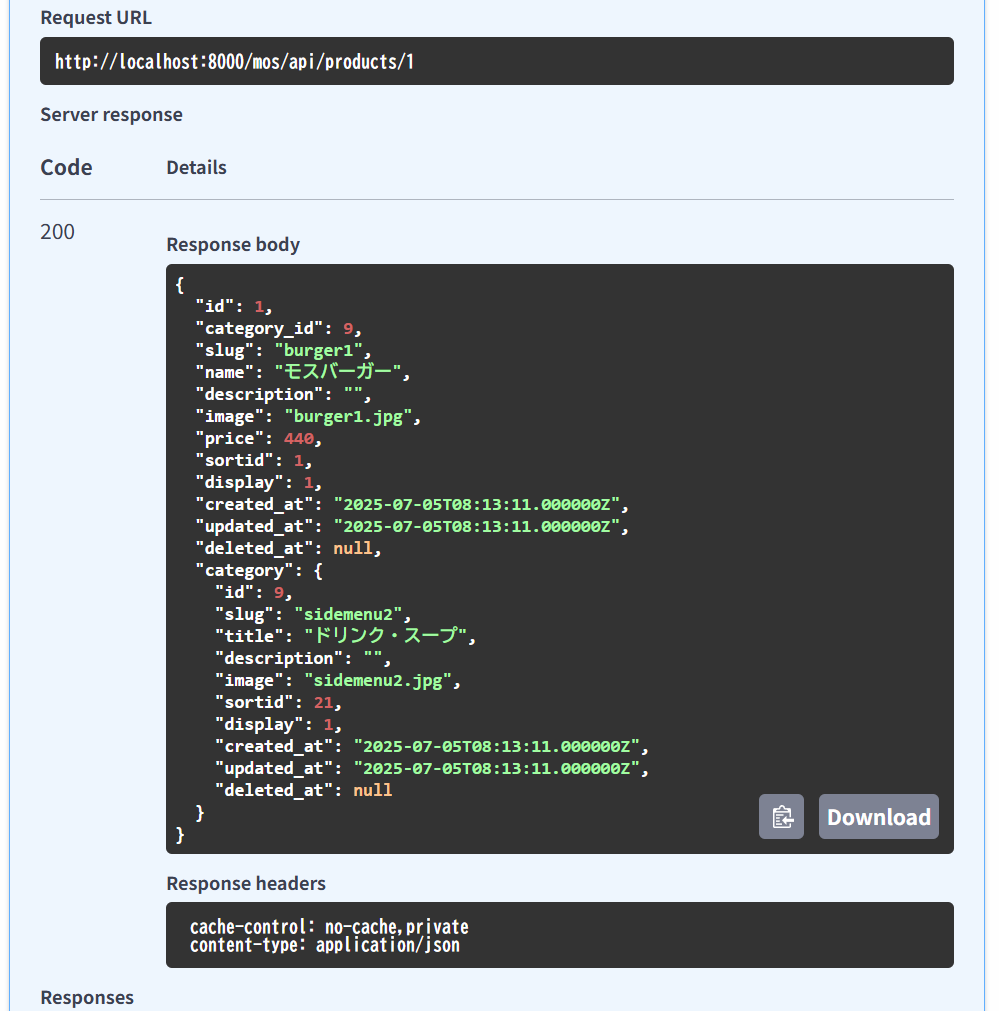
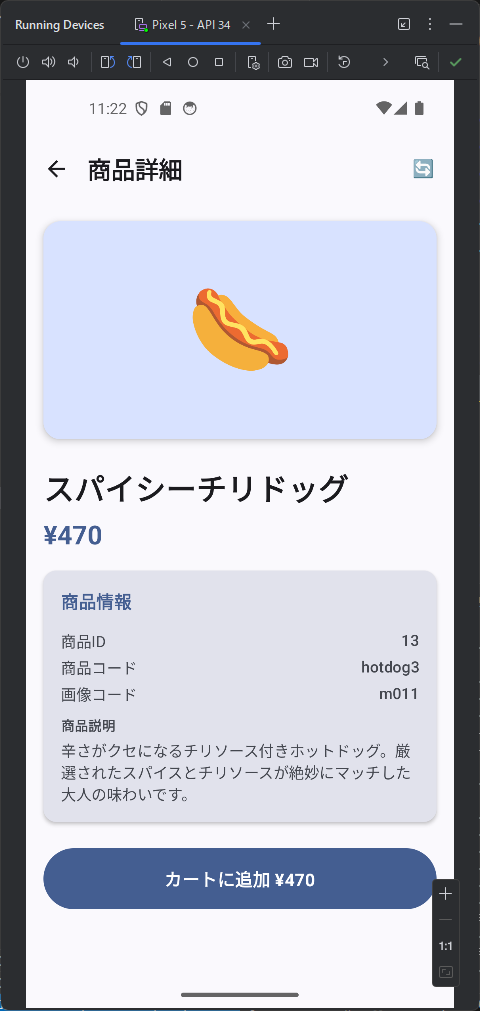
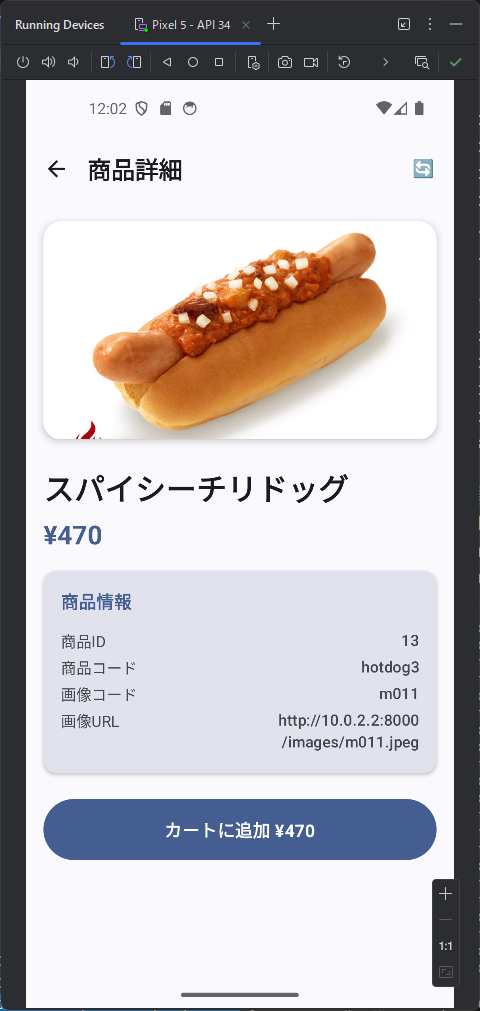
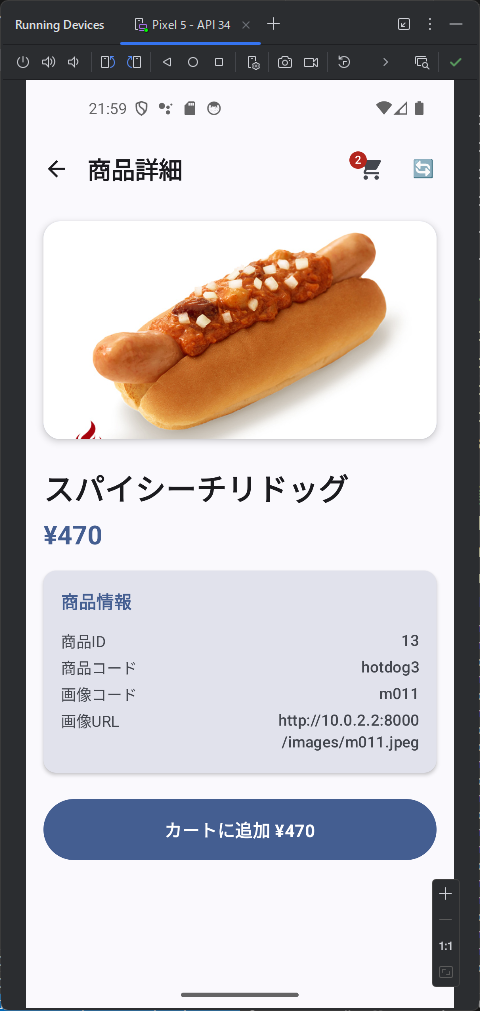
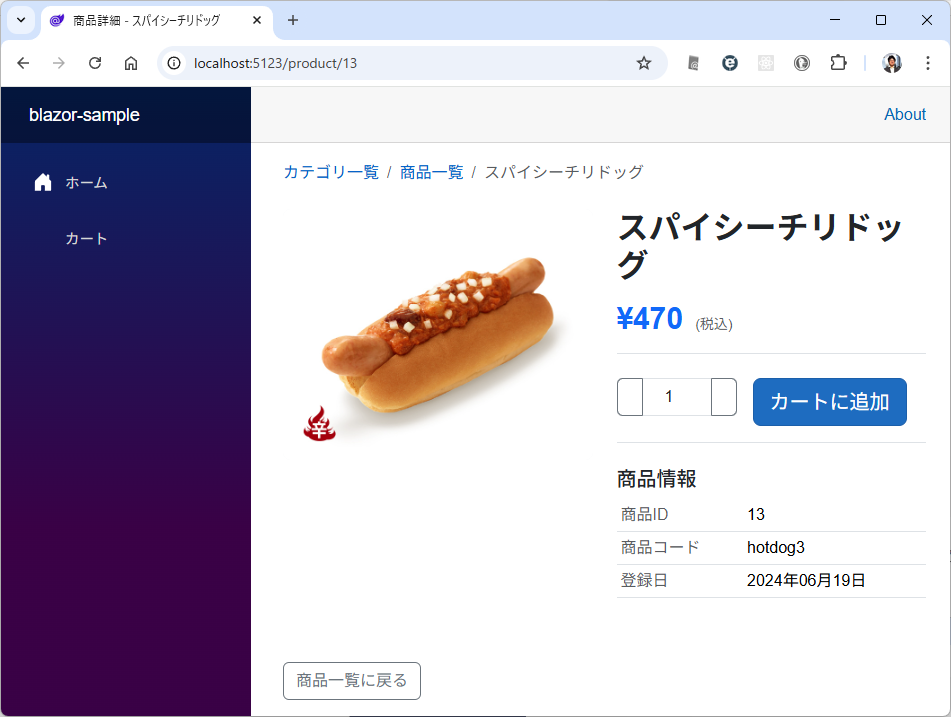
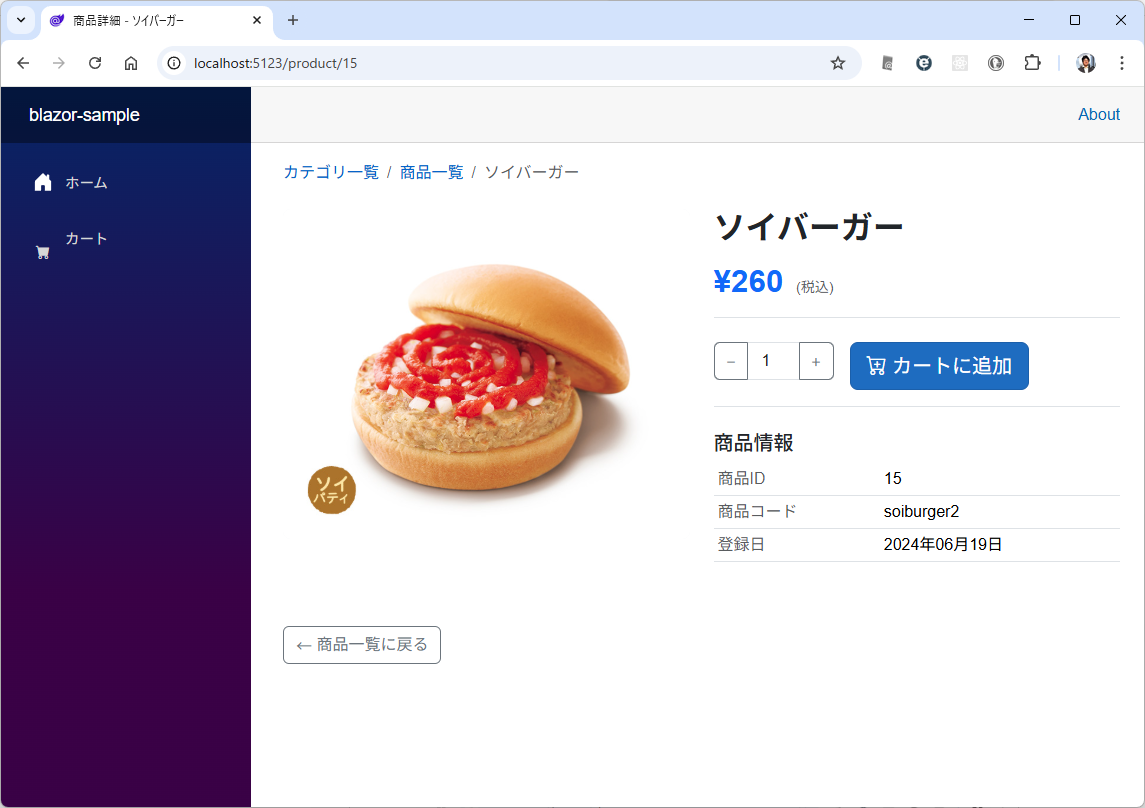
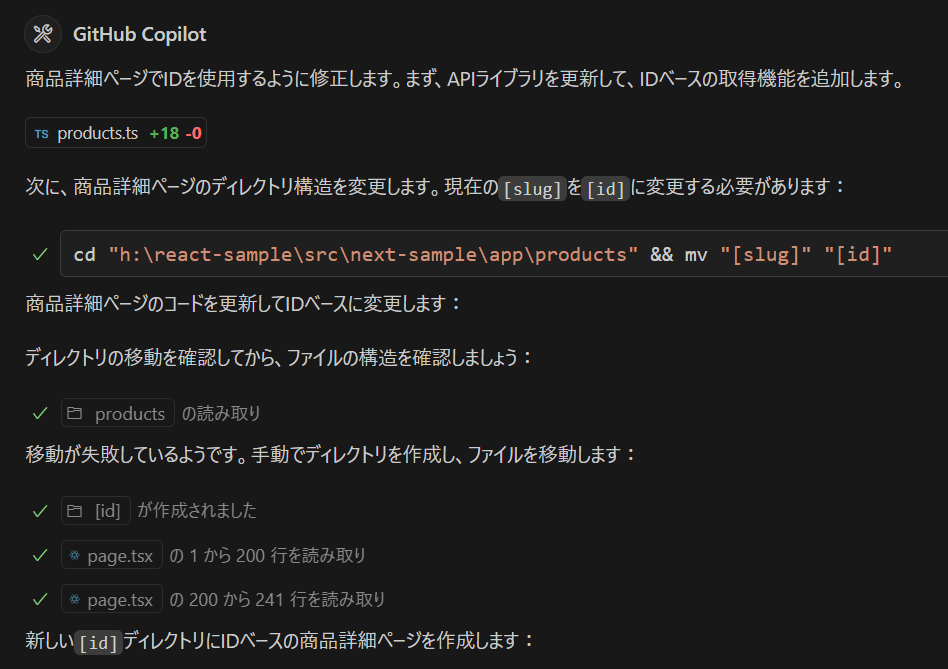
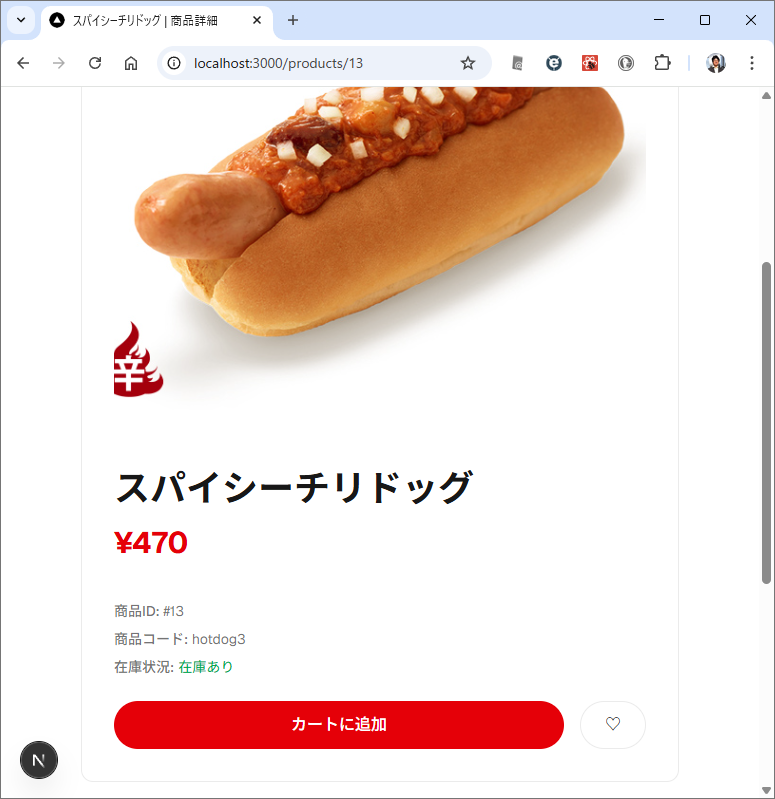
商品一覧の商品をクリックしたときに、商品詳細ページを開いて web api は /products/{id}
個人的に言えば、後者の管理サイトみたいなのは Ruby on Rails などの特定ツールを使って一気に作ってしまうほうがよい。開発プロジェクトにとって、管理系の画面は定型のものが多く、利用者はコンピュータ―にある程度強いという前提が成り立っている。なので、多少レイアウトや使い勝手を犠牲にしてでも、MVCパターン系のツール(CakePHPのbekeとか)を使って100枚ぐらい一気に作ってしまうと、またそれ系のツールを自作して一気に作るほうがよい。
余談ですが、厳密な設計書は厳密なプロンプトから目的のサイト作成を一気に作るように頑張る位だったら「厳密な設計書は設定から目的のサイトを自動作成するツールを作成する」のがベターですね。つまりは、先の Ruby on Rails のようなツールを生成AIに作って貰う乃至は協同で作るといパターンです。魚を得るのではなくて釣り竿を作るとか、金を掘るのではなくてツルハシを売るとかジーンズを売るとかそいうレベルの話です。
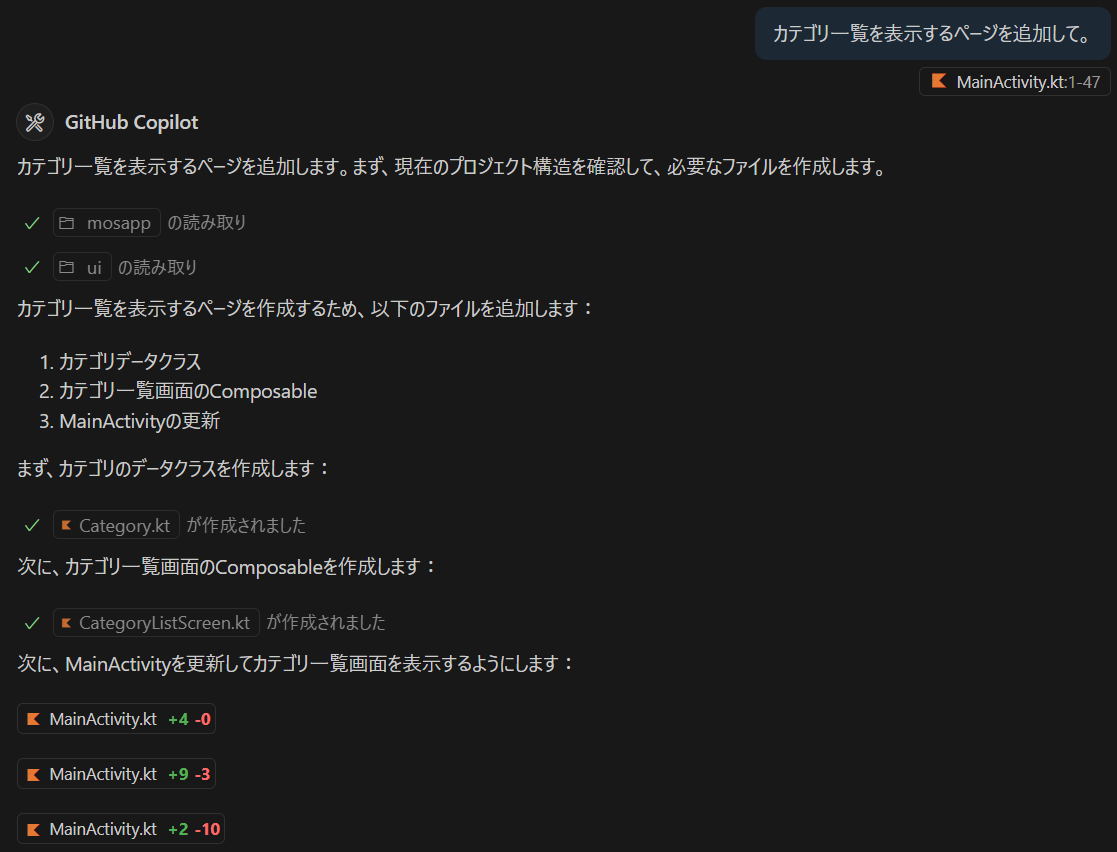
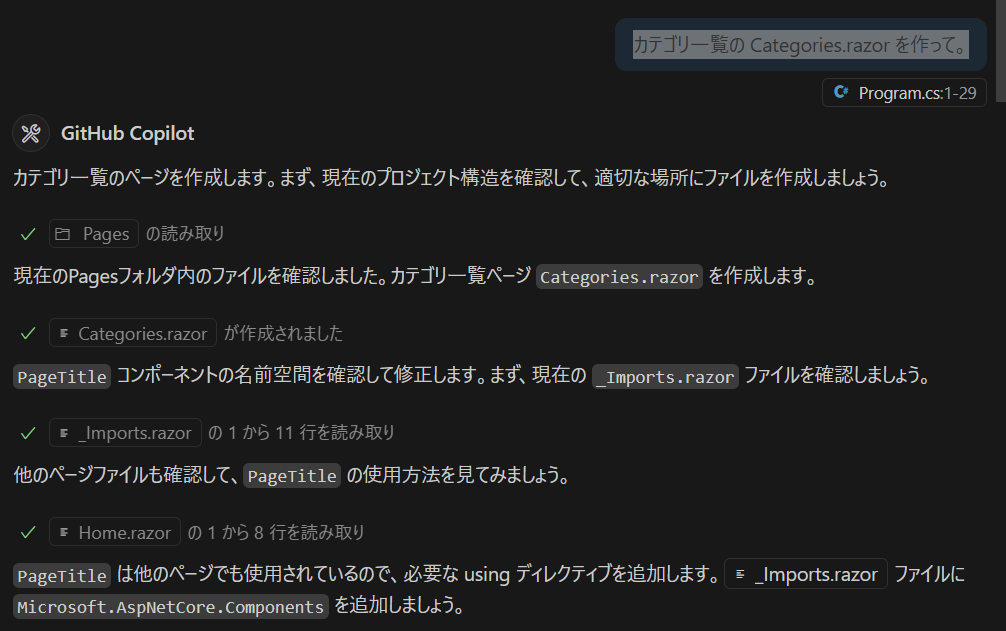
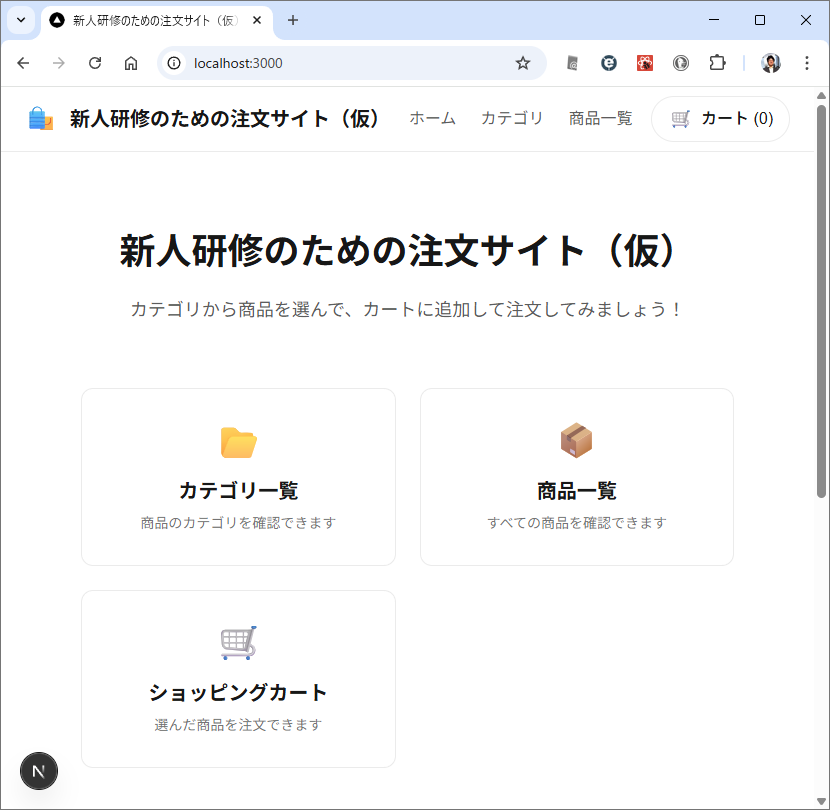
ページ単位でプロンプトで指示する
npx create-next-app@latest
で next.js のプロジェクトを作成した後に vscode で開きます。
Coilot は “Agent” モードにしておきます。普通のチャットを使いたいときは “Ask” にすれば ok です。
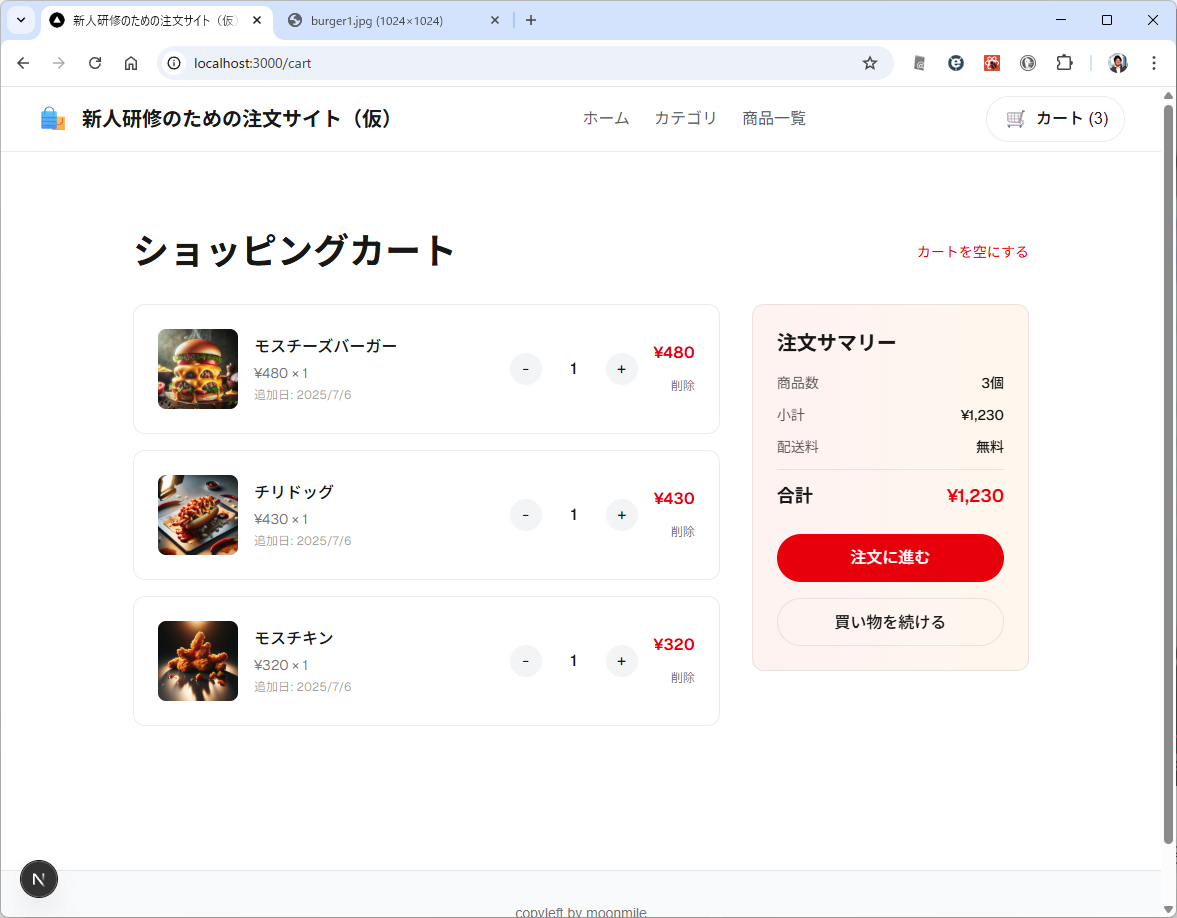
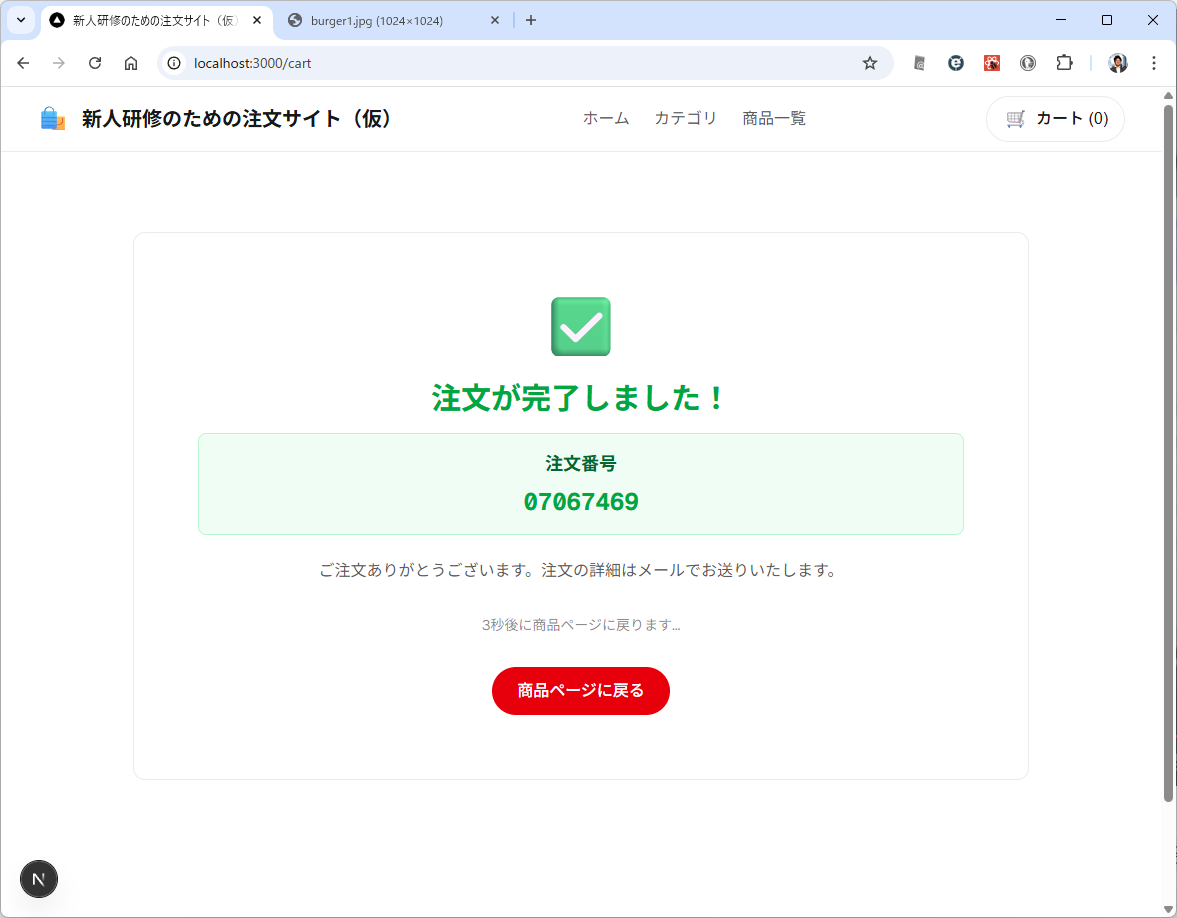
既に web api は Laravel で作ってあるので動作が可能な状態です。新人教育でも web api は提供するパターンで画面を Vue3/Nuxt で作って貰っています。web api まわりはデータベースアクセスなどの範囲が広いのとルーティング設定や Controller やらとややこしいことが多いので、提供することにしています。このあたり、良い教科書がないですかね? Web APIの設計の本は小難しいものが多いのです。
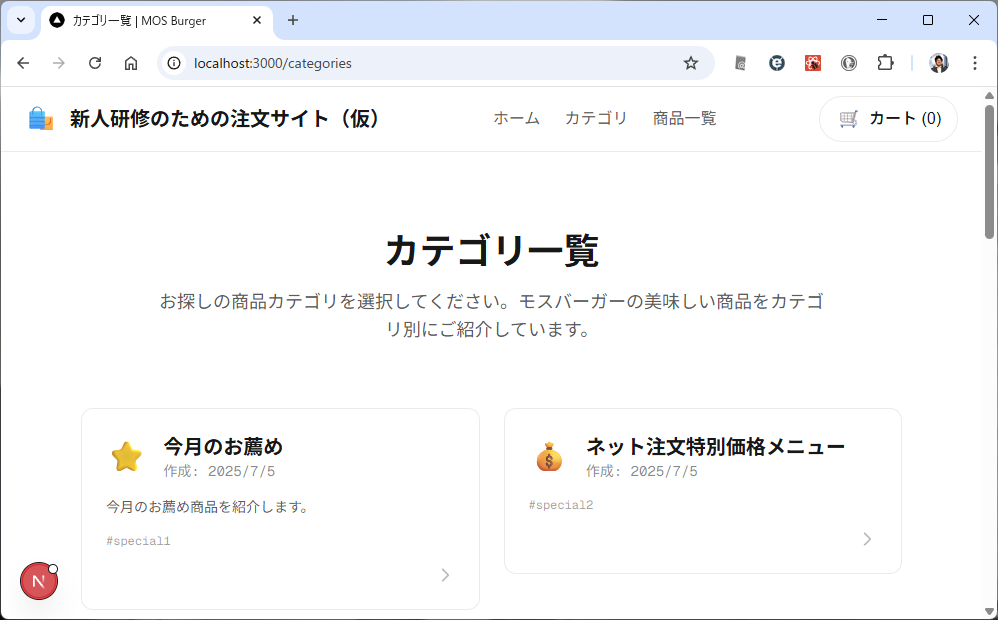
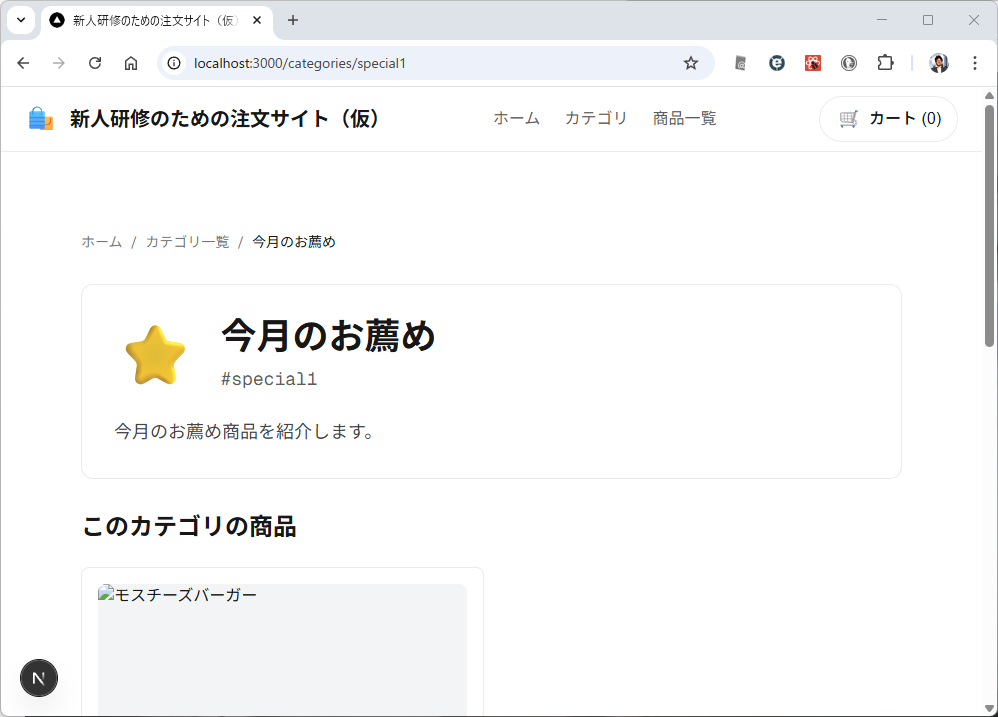
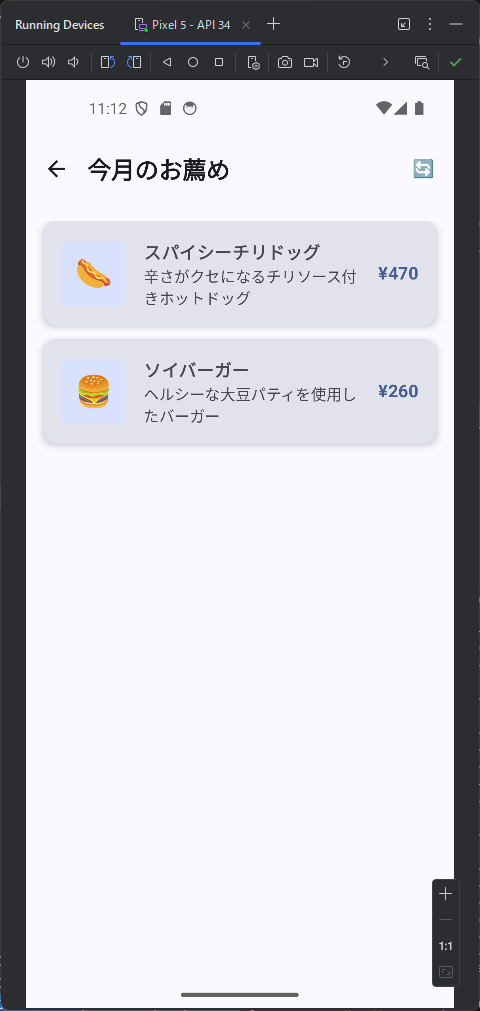
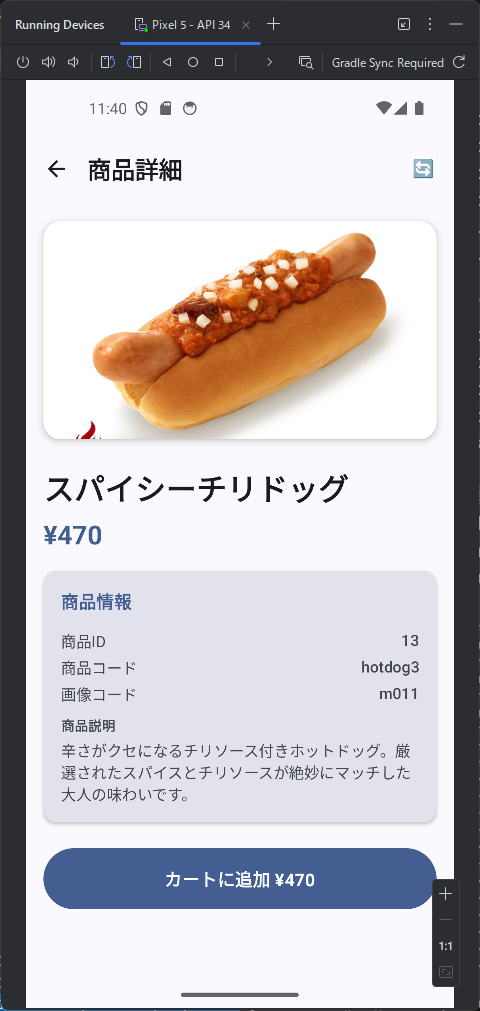
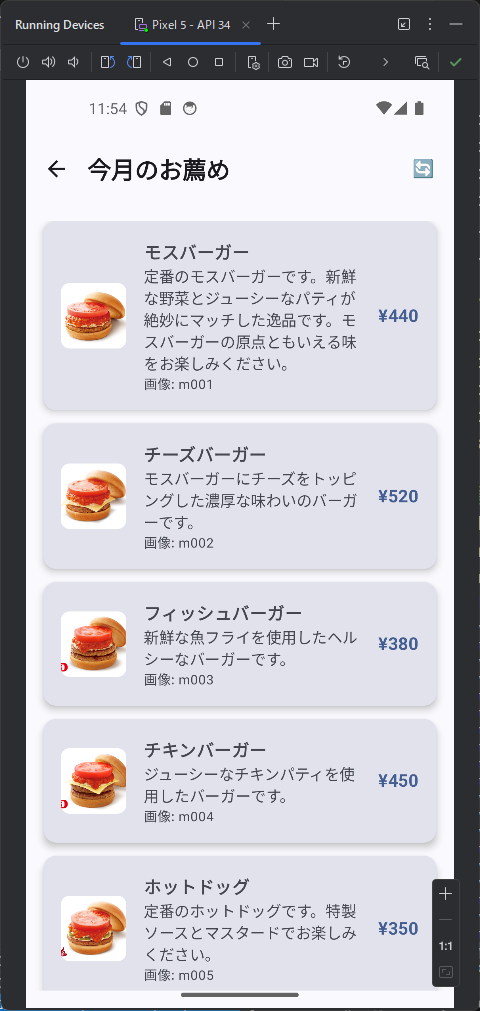
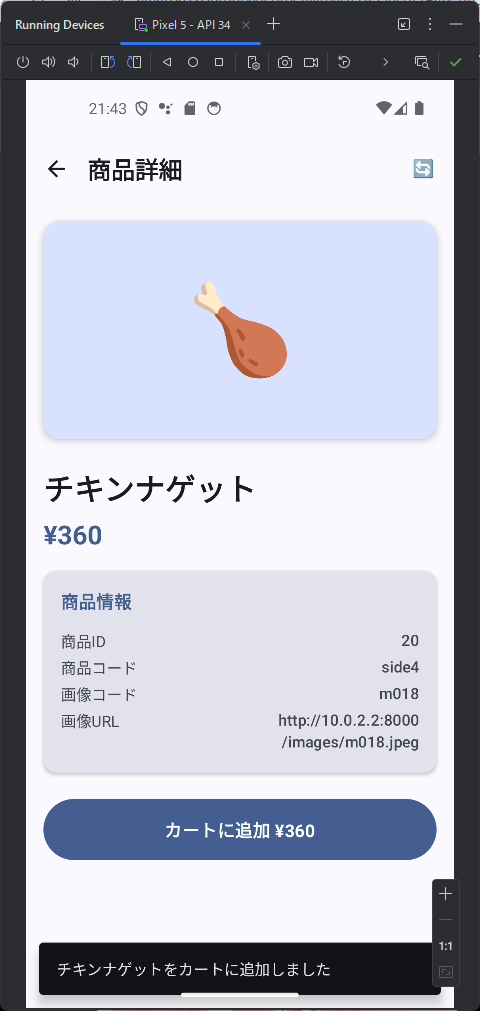
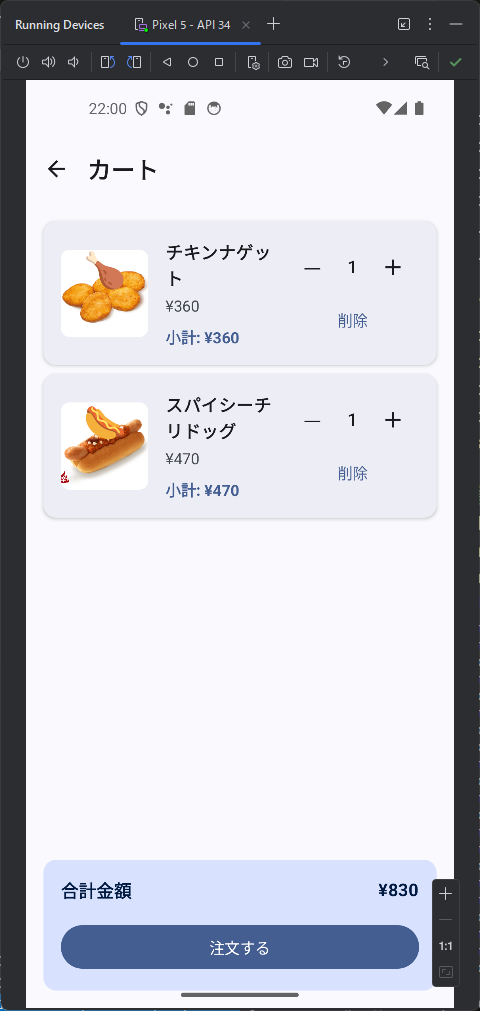
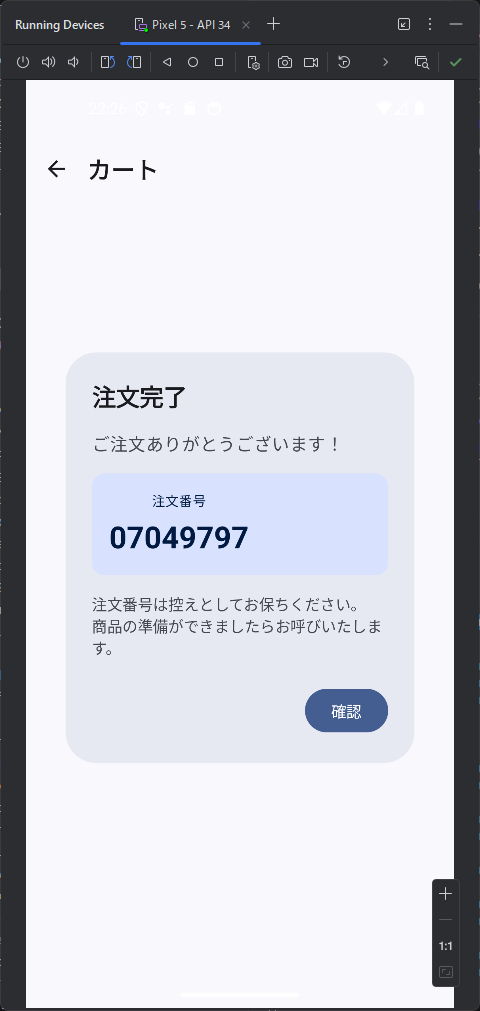
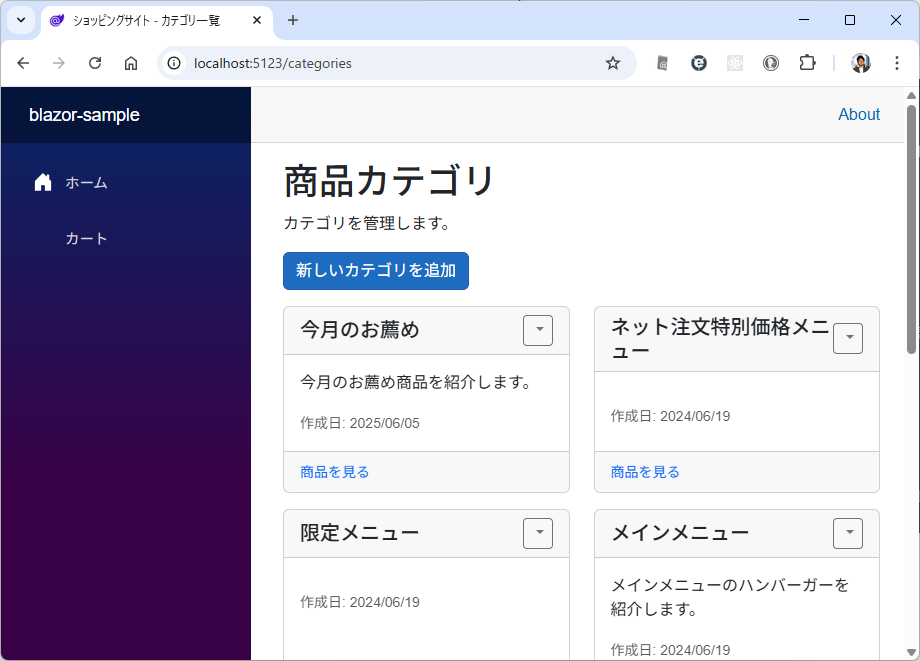
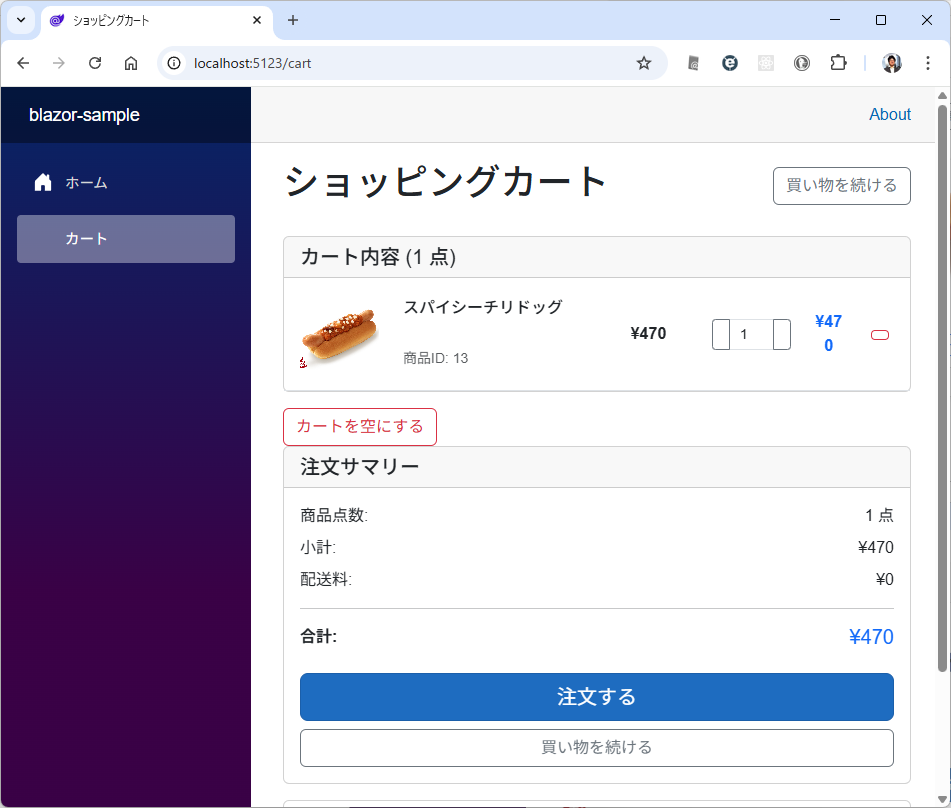
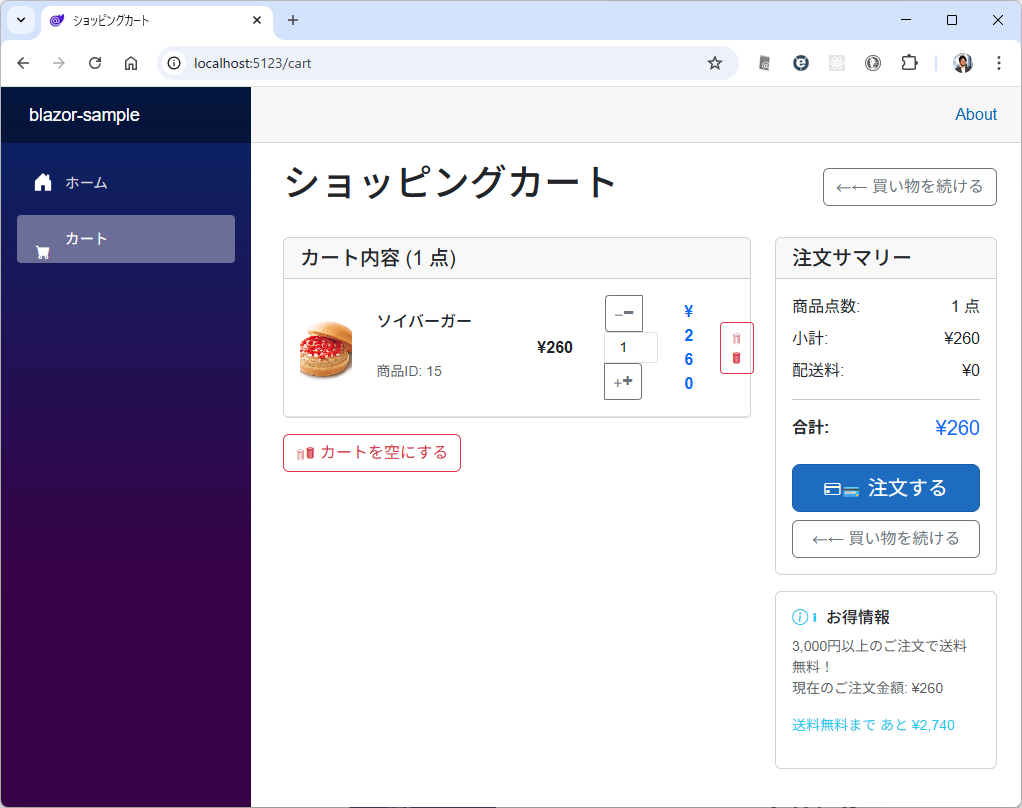
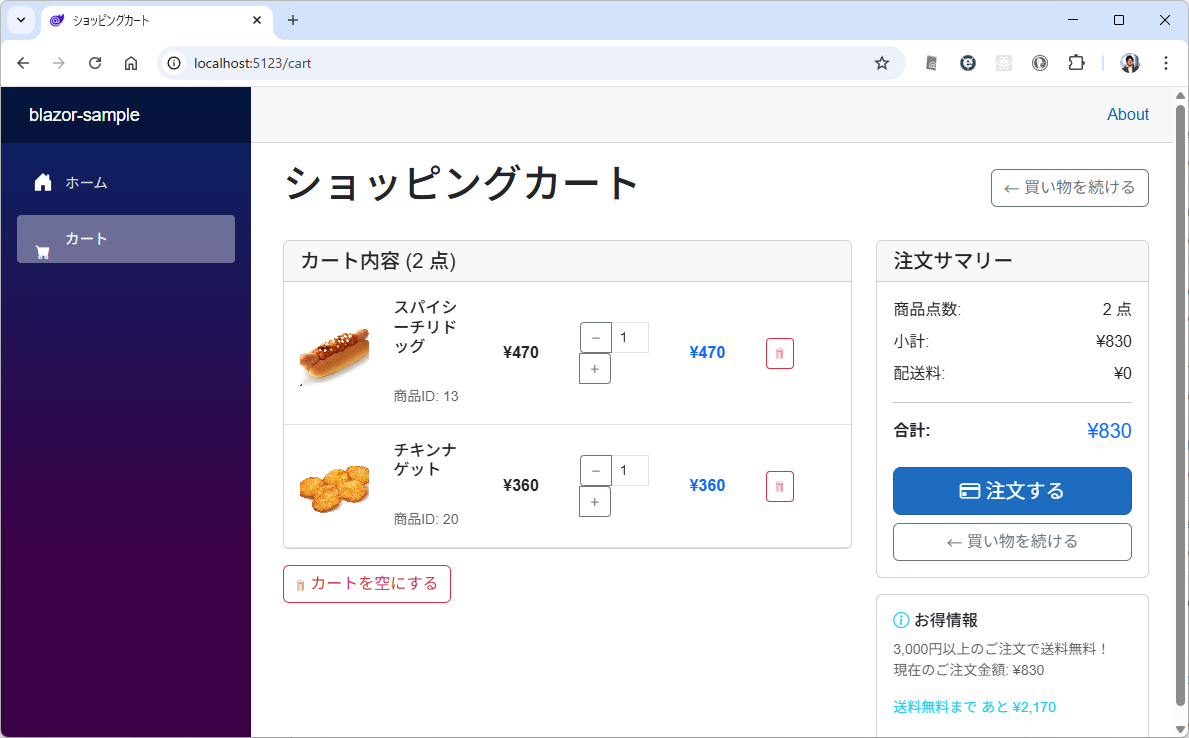
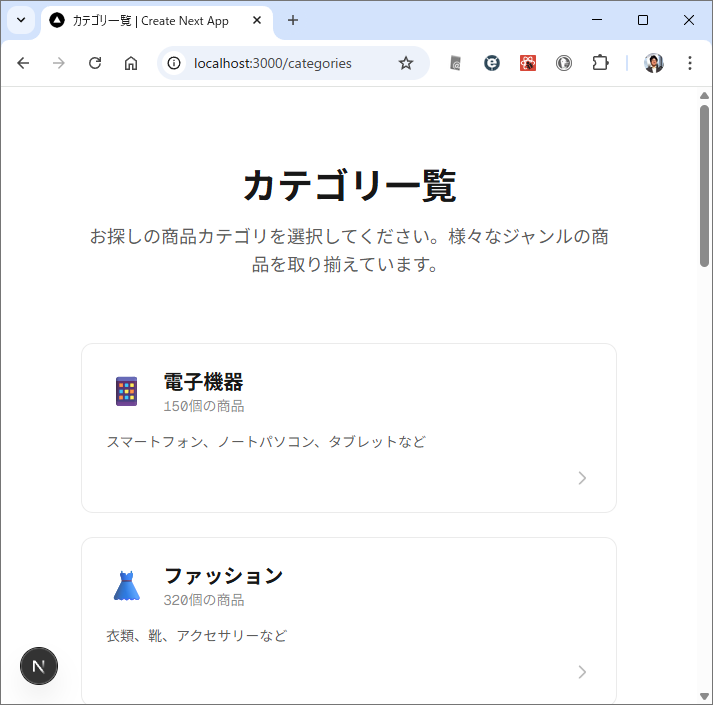
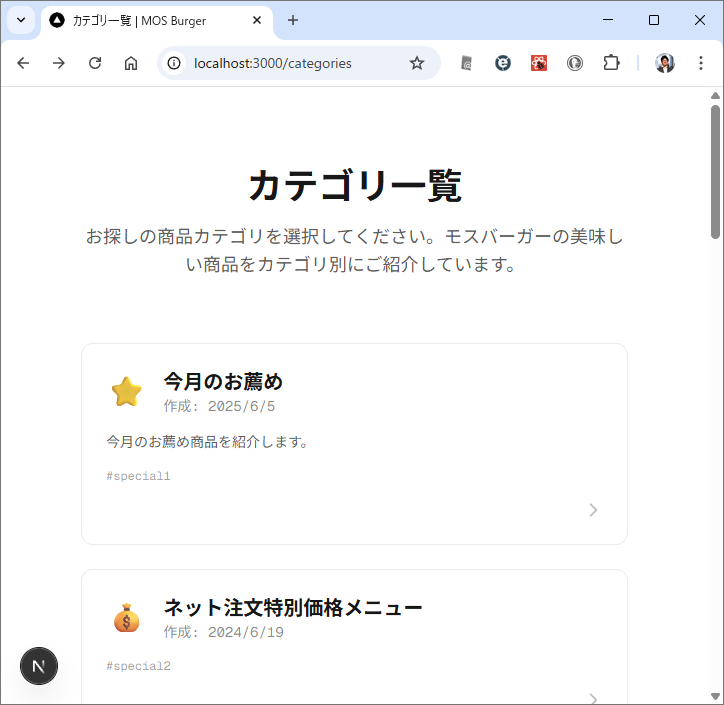
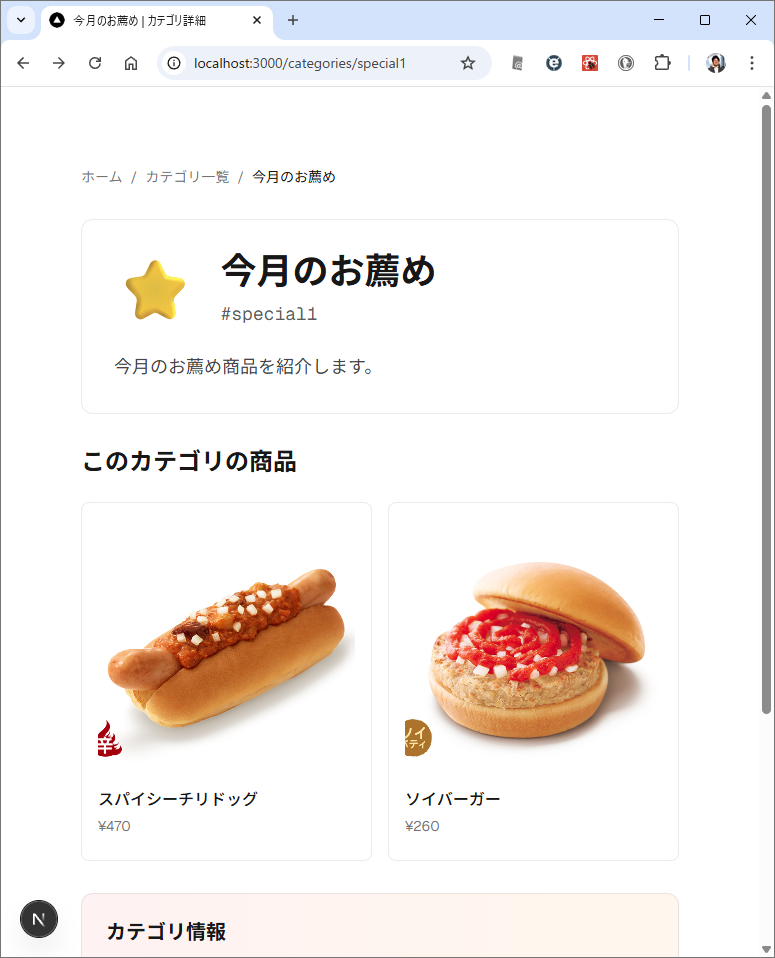
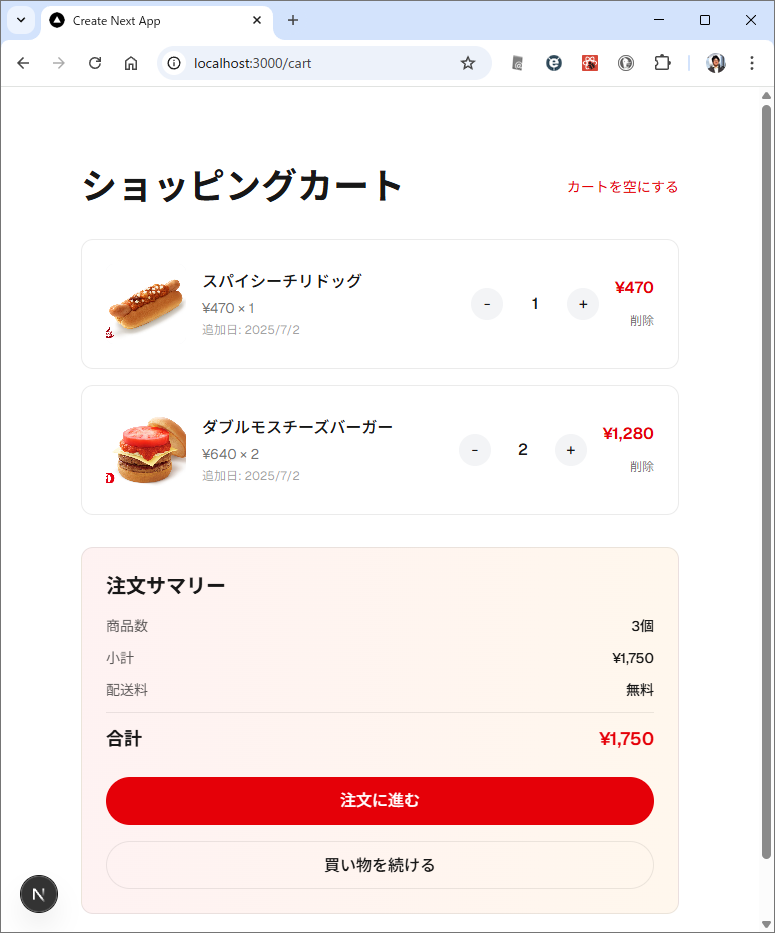
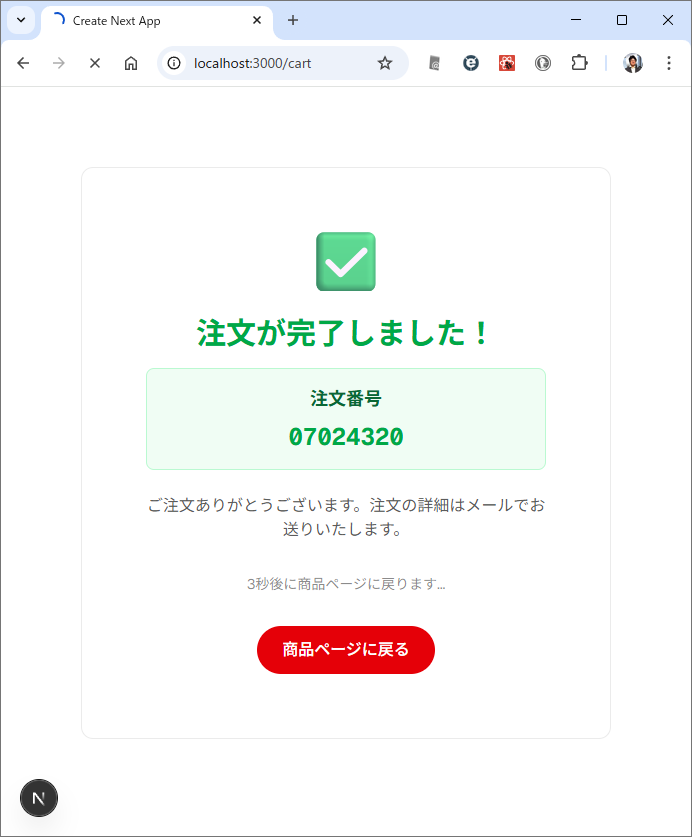
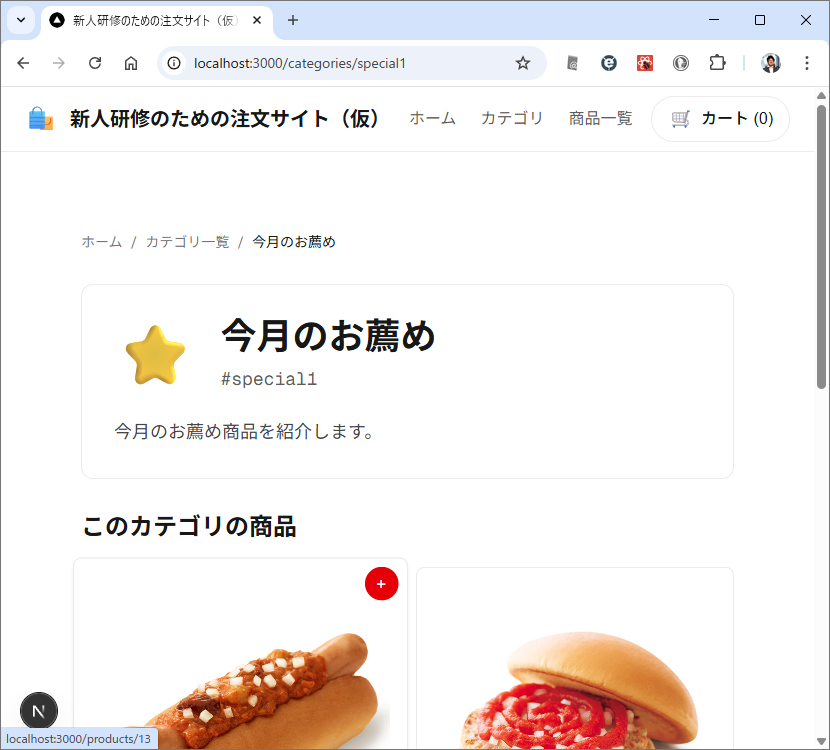
カテゴリ一覧のページとカテゴリ内の商品のページが表示されます。商品のほうはまだダミーデータですね。このあたりは、最初のところで web api の一覧とか OpenAPI を使って情報を突っ込んでやるうまく解析してくれるかもしません。今回は最初なので1手順ずつやっています。しかも、このブログを書きながらリアルタイムでやっている。
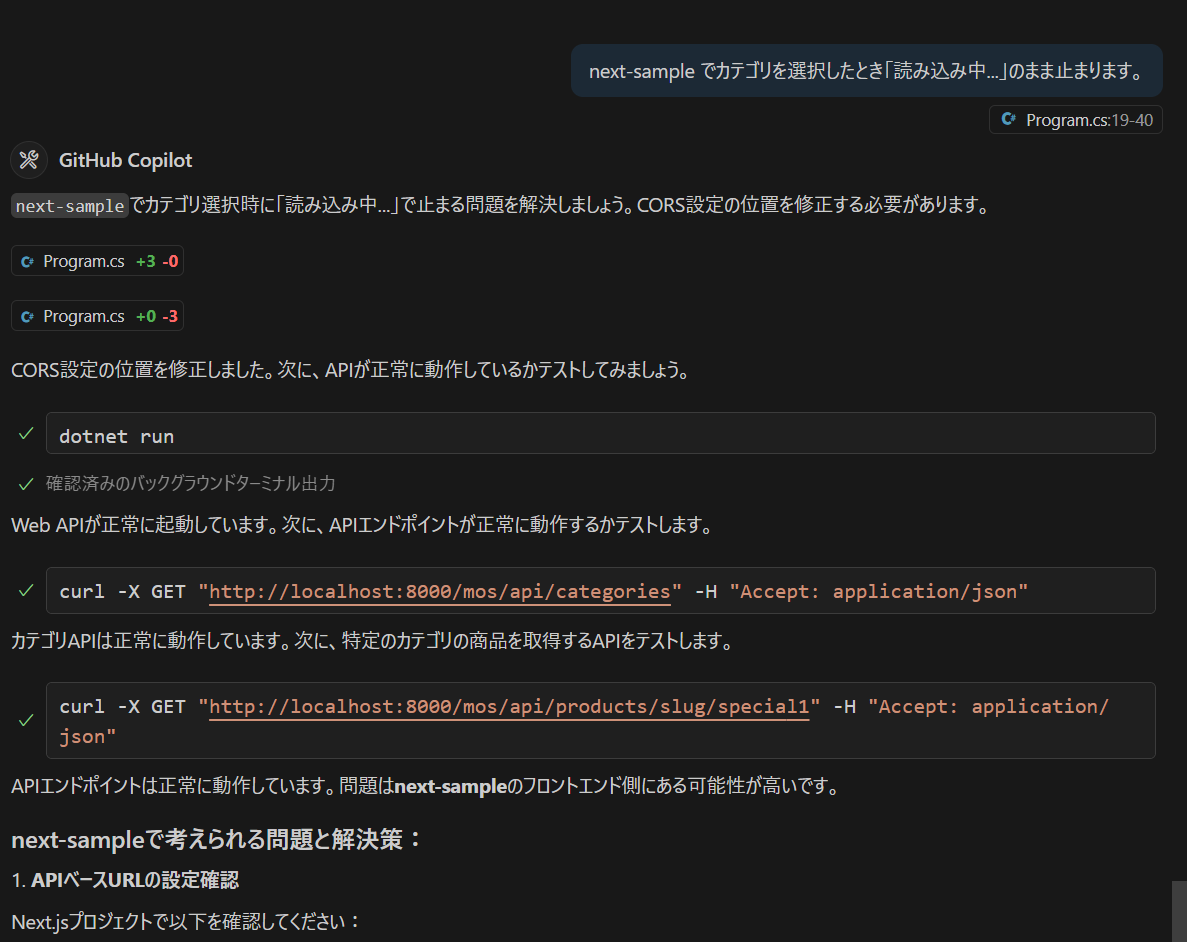
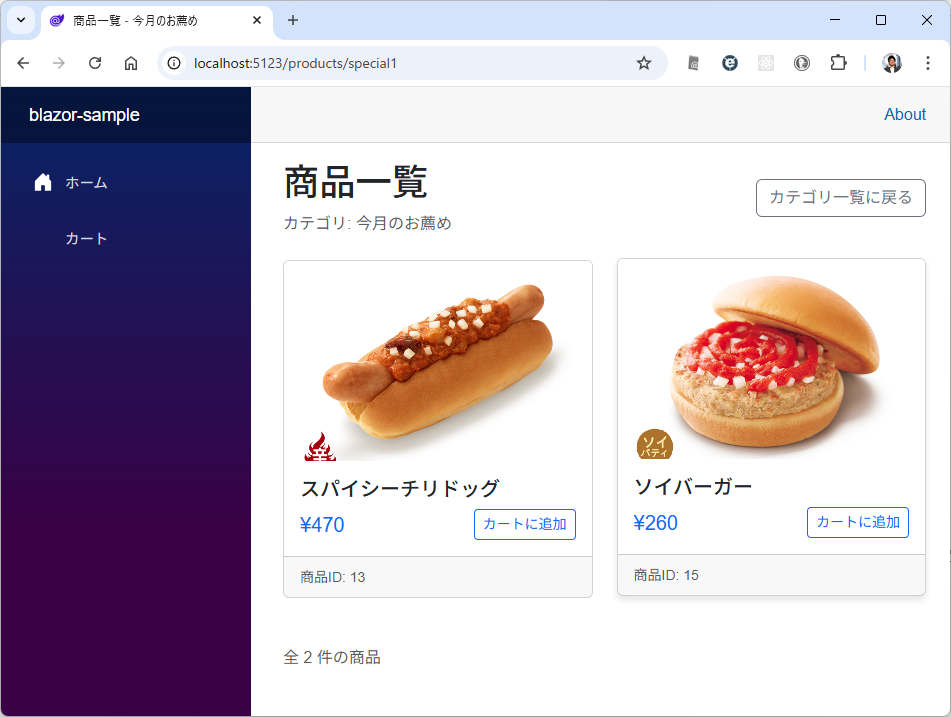
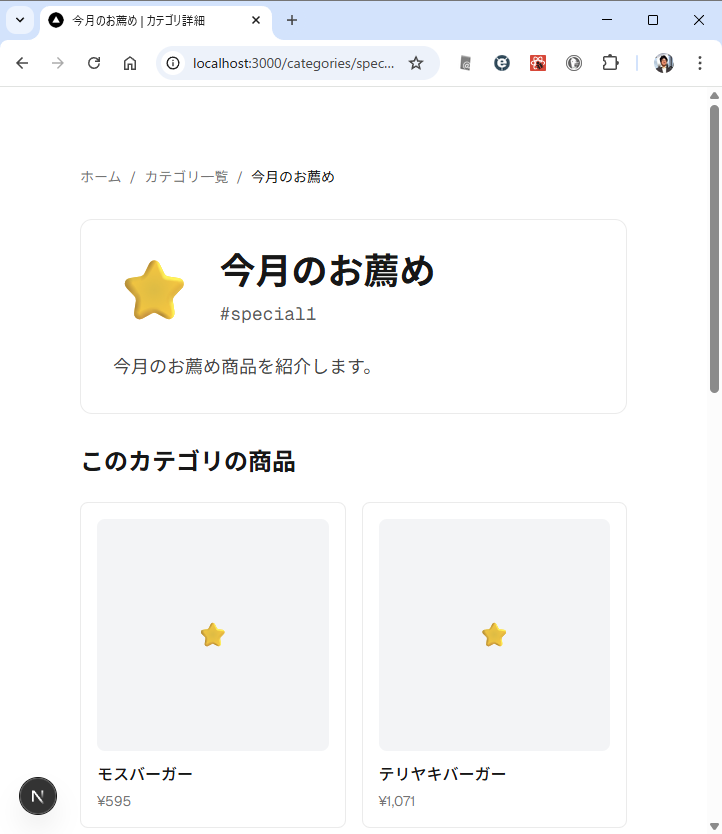
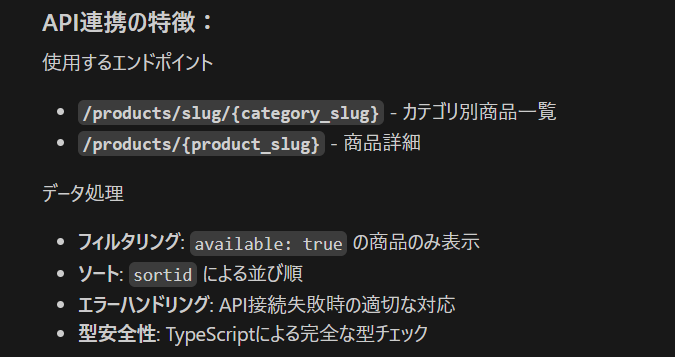
カテゴリ内の商品を表示するときは web api で /products/slug/{category_slug} を使って。 商品を選択したときは、/products/{product} を使って、商品の詳細ページを表示して。
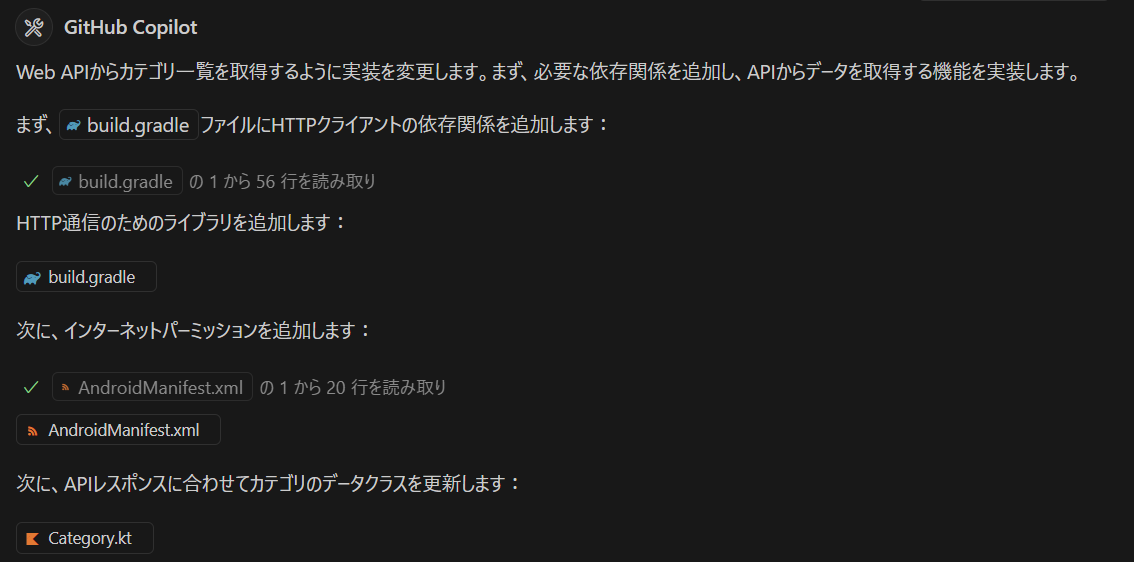
Copilot が作ったページがちょっと違うので、Copilot に直して貰いましょう。そもそも、Copilot あるいは Claude Sonnet の書きやすい形でコードを生成しているので、それ自身が理解しやすいはずです。このあたり
新規で Claude Sonnet を作成して、さらに Claude Sonnet で修正する
人間が書いた既存のコードを Copilot が解析して Claude Sonnet が修正/追加していく
React/Nuxt慣れしていれば、人が単体でももっと素早くできるかもしませんが、これ以上ペースを上げても疲れるだけなので、検証としてはこの程度でいいんじゃないかなと思います。これをもっと早くしたい場合は(例えば100画面同時につくるとか)、先に書いた通り Ruby on Rails 形式で別途共通フォーマットや共通データを作成しておいて、生成AIに量産するツールを作ったもらったほうがよいです。そのあたりの線引きをペアプロ型のプロトタイプ開発に落とし込むか、オートメーションの大量生産型に落とし込むかですね。ブラウザ上で、さっくりと管理画面系ができますのようなキントーンを使った場合は後者のほうがベターだと思います。