アリスはプラダがお好き | Moonmile Solutions Blog
http://www.moonmile.net/blog/article/alice-plada
アリプラシリーズの第24弾めは、イテレーターの話…というか、とある林檎な国では for がなくなって for in だけになってしまったものだから、いやいや、配列とコレクションがごっちゃになってないか?と思って作ろうと思ったのだけど、横道に逸れてイテレーターになってしまったという訳。
最近のプログラム言語ではコレクションの全ての要素に対して何かやるときは、foreach を使う訳ですが(林檎の国では for in ですね)、これはコレクションの中身のすべてのアクセスするというだけで、特に順序は決まっていません。まあ、実装上は最初の要素からアクセスするんだけど、Javascript のように実はとびとびだったり、そもそもコレクションと配列の違いってそういう「順序性」のところにあります。順序が保証されていないってことですね。順序が保証されないってことは、逆順ってのもないわけで、すべての要素に1回ずつアクセスするってだけです。実際のところは、各プログラム言語のスペックによるのだろうけど、配列とコレクションの違いってのはそういうところにある。
なので、コレクションを foreach で探索したときに、ひとつ前の要素とあわせて何かする(たとえばフィボナッチ関数)というような他の要素をアクセスして順序が問題になる場合は、再帰関数を使ったりするのだが、まあ、それの例っぽいものを示しておこう。
こんな感じに、Bag クラスと Cat クラスを作ってみる。鞄の中には猫か鞄を入れられる。鞄の中には鞄が入るので、実は無限に鞄が入るとい不思議な Bag クラスになっている。いや、これは DOM と一緒で XNode がそれの仕組みなっているので、一般的なツリー構造のアプローチになっている。
class IObject { }
class Cat : IObject
{
public string Name { get; set; }
public Cat( string name ) {
Name = name;
}
}
class Bag : IObject
{
public List<IObject> Items { get; set; }
public Bag () {
this.Items = new List<IObject>();
}
public Bag Add( params IObject[] items )
{
foreach ( var it in items ) { this.Items.Add(it); }
return this;
}
// 猫だけ取り出す
public IEnumerable<Cat> GetCats()
{
foreach (var it in this.Items)
{
if (it is Cat)
{
yield return it as Cat;
}
if (it is Bag)
{
foreach (var ii in (it as Bag).GetCats())
{
yield return ii;
}
}
}
}
}
Bag クラスには、猫だけを取りだすための GetCats メソッドがあって、イテレーターを返すようにしてある。yield return を使って、入れ子になった Bag の中も探索できるようにしている。
Add メソッドは、子要素(Bag か Cat)を追加できるようにしてあって、これは XElement と同じ仕組みになっている。
猫のみ取り出す
Bag prada = new Bag().Add(
new Cat("mike"),
new Bag().Add(
new Cat("hop"),
new Cat("step"),
new Cat("jump")),
new Cat("kuro"),
new Cat("shiro")
);
// 猫のみ取り出す
foreach ( var it in prada.GetCats() )
{
Console.WriteLine("cat: " + it.Name);
}
prada の鞄に、猫と鞄を入れるんだけど、これを実行すると GetCats メソッドで綺麗に猫だけを取り出せる。
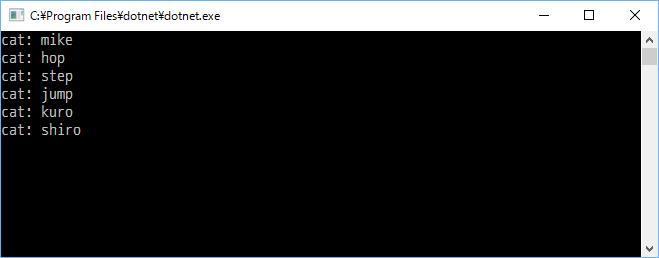
これでアリスは満足ですよね。
結果を見るとわかるんですが、鞄の中身を取り出す順番は実装依存なので、どういう順番で猫が出てくるのかは分かりません。けれども、ひとつの要素を1回ずつアクセスして取り出しています。
無限に猫を取り出す
さて、Bag クラスを見ると、Bag クラス自身を入れ子にしているので、実は自分自身を要素に加えることができる。そう、循環参照というやつだ。
// 無限バックを作る
Bag infbag = new Bag().Add(new Cat("Cheshire"));
infbag.Add(infbag);
// 無限に猫を取り出せる
foreach (var it in infbag.GetCats())
{
Console.WriteLine("cat: " + it.Name);
}
バッグ infbag を作って、自分の鞄に追加するという無限バッグを完成させる。でもって、これも GetCats メソッドで取り出すとどうなるか?アリスは、無限にチェシャ猫を取り出すことができるのだろうか?
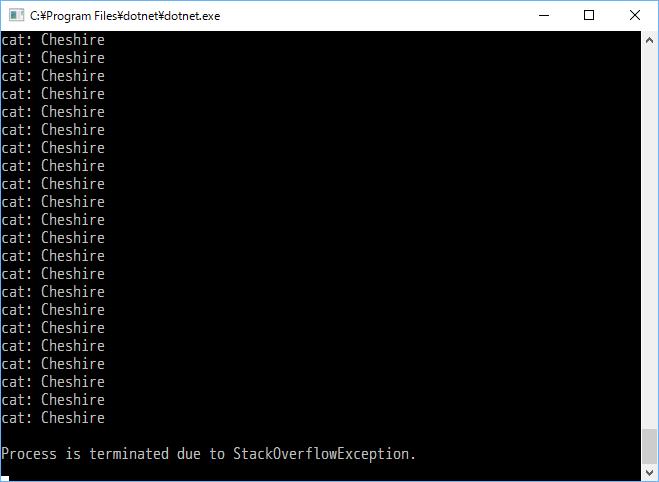
一見、無限に取り出せるように見えるけど、GetCats メソッド内で入れ子になっているからスタックオーバーフローになっちゃんですよね~、ちゃんちゃん。
サンプルコード
サンプルコードはこちら
https://1drv.ms/u/s!AmXmBbuizQkXgf0CI2eEOEnAdsI-_w