CREATE TABLESPACE REDMINETS DATAFILE
'C:\app\oracle\oradata\ORCL\DATAFILE\REDMINETS.dbf'
SIZE 1G AUTOEXTEND ON NEXT 100M MAXSIZE UNLIMITED;
CREATE USER redmine IDENTIFIED BY redmine
DEFAULT TABLESPACE REDMINETS
TEMPORARY TABLESPACE TEMP
ACCOUNT UNLOCK ;
GRANT UNLIMITED TABLESPACE TO redmine;
GRANT CREATE SESSION TO redmine;
GRANT CONNECT TO redmine;
GRANT RESOURCE TO redmine;
ALTER USER "REDMINE" DEFAULT ROLE ALL;
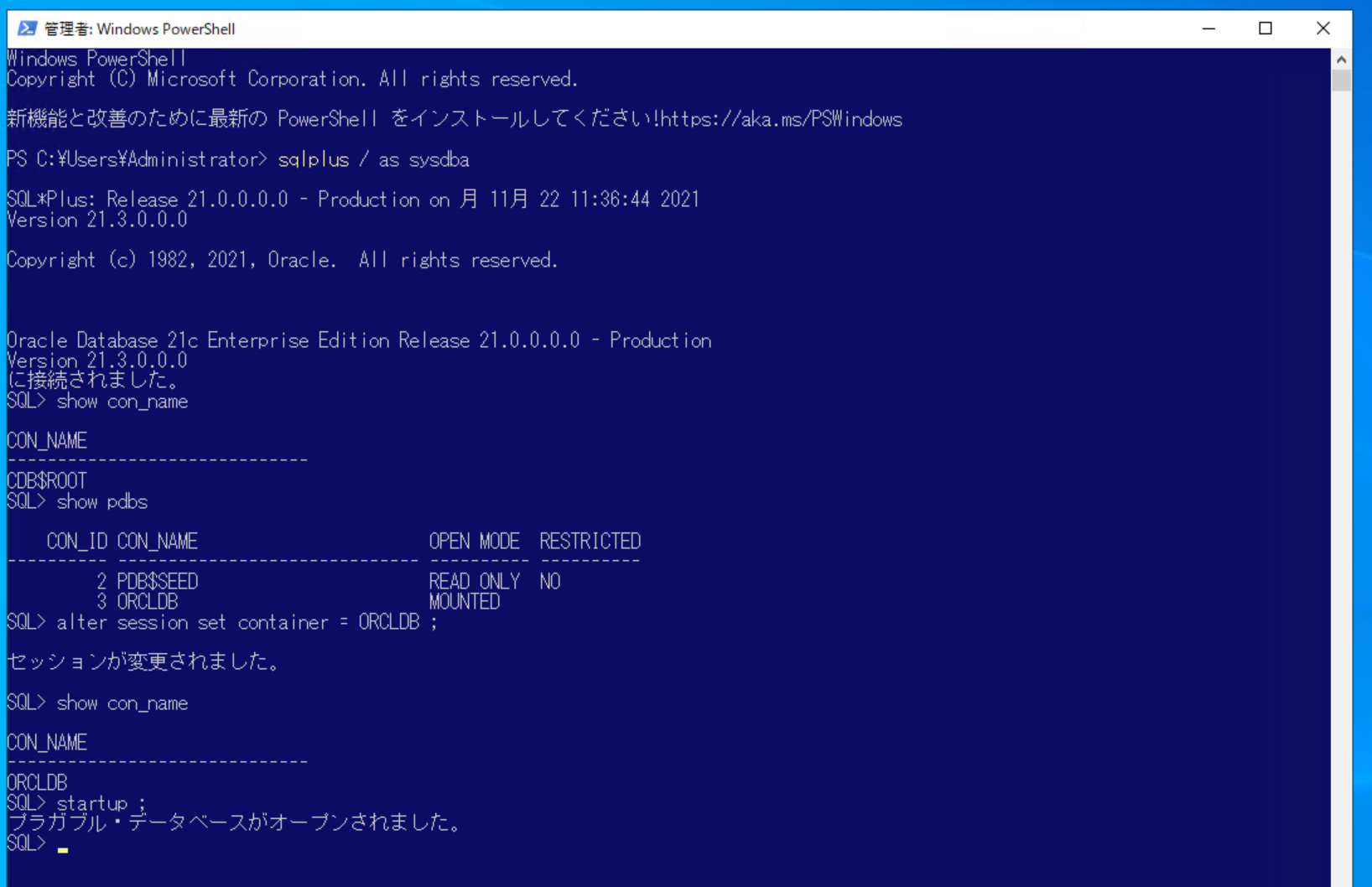
redmine という名前でユーザーを作成しておきます。
表領域 REDMINETS
ユーザー名 redmine(内部では自動的に大文字になるので、正確には REDMINE です)
パスワード redmine
権限が少し過剰ですが、ひとまずこれで Ok です。この使い方は、いまとなっては少しイリーガルなので、プラカブルデータベースを使った方式に直します。
一番手っ取り早いのは、手作業でエンティティクラスを作ることです。エンティティクラスは単純な値クラスなので、プロパティを並べれば ok.
MySQL Workbench の結果から、ちまちまと C# のクラスを作るか、スキーマを参照しながら手作業で作ります。
CREATE TABLE `projects` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL DEFAULT '',
`description` text,
`homepage` varchar(255) DEFAULT '',
`is_public` tinyint(1) NOT NULL DEFAULT '1',
`parent_id` int DEFAULT NULL,
`created_on` timestamp NULL DEFAULT NULL,
`updated_on` timestamp NULL DEFAULT NULL,
`identifier` varchar(255) DEFAULT NULL,
`status` int NOT NULL DEFAULT '1',
`lft` int DEFAULT NULL,
`rgt` int DEFAULT NULL,
`inherit_members` tinyint(1) NOT NULL DEFAULT '0',
`default_version_id` int DEFAULT NULL,
`default_assigned_to_id` int DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `index_projects_on_lft` (`lft`),
KEY `index_projects_on_rgt` (`rgt`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8 ;
NULL 許可の部分をチェック
tinyint(1) を bool に直す
timestamp を DateTime あるいは DateTimeOffset に直す
主キーに Key 属性をつける
部分を注意すれば比較的簡単に C# のエンティティクラスができます。
public class projects
{
[Key]
public int id { get; set; }
public string name { get; set; } = "";
public string? description { get; set; }
public string? homepage { get; set; }
public bool is_public { get; set; }
public int parent_id { get; set; }
public DateTime created_on { get; set; }
public DateTime updated_on { get; set; }
public string identifier { get; set; } = "";
public bool status { get; set; }
public int? lft { get; set; }
public int? rgt { get; set; }
public int inherit_members { get; set; }
public int? default_version_id { get; set; }
public int? default_assigned_to_id { get; set; }
}
using System.ComponentModel.DataAnnotations.Schema;
[Table("proejcts")]
public class Project
{
...
[Column("is_public")]
public bool IsPublic { get; set; }
...
}
Table 属性と Column 属性をちまちまと指定していけば、
MySQL 側のカラム名を Column で指定
プロパティ名は C# の命名規約に合わせる
ことができます。ちなみに MySQL の設定によってはテーブル名やカラム名の大文字小文字が区別されるため、環境にそろえようとすると(特に Linux上)、この属性は必須になります。
public class DescResult
{
[Key]
public string Field { get; set; }
public string Type { get; set; }
public string Null { get; set; }
public string? Key { get; set; }
public string? Default { get; set; }
public string? Extra { get ; set; }
}
public class RedmineDataContext : DbContext
{
...
public DbSet<DescResult> DescResult => Set<DescResult>();
}
var cnn = context.Database.GetDbConnection() as MySqlConnection;
var result = context.DescResult.FromSqlRaw("DESC projects");
Console.WriteLine("\nDESC projects");
Console.WriteLine("Field Type Null Key Default Extra");
foreach ( var it in result )
{
Console.WriteLine($"{it.Field}\t{it.Type}\t{it.Null}\t{it.Key}\t{it.Default}\t{it.Extra}");
}
public static class DataTableExtenstions
{
/// <summary>
/// DataTable.Rows を指定した List<T>に変換する
/// </summary>
public static List<T> ToList<T>(this DataTable src) where T : new()
{
var items = new List<T>();
var properties = typeof(T).GetProperties();
// TODO: Column 属性があれば、探索するカラム名を変更する
foreach ( DataRow row in src.Rows )
{
var item = new T();
foreach ( var pi in properties )
{
var value = row[pi.Name];
if ( value == System.DBNull.Value )
{
pi.SetValue(item, null);
}
else
{
pi.SetValue(item, row[pi.Name]);
}
}
items.Add(item);
}
return items;
}
}
public partial class T_顧客Sub
{
public int TIDa { get; set; }
public Nullable<int> TID { get; set; }
public string 部署名 { get; set; }
public string TEL { get; set; }
public string FAX { get; set; }
public string 携帯 { get; set; }
[Column("〒")]
public string ZIP { get; set; }
public string 住所1 { get; set; }
public string 住所2 { get; set; }
...
}
ここまでできあがると、通常の EF Core と同じように ACCESS にアクセスができます。あまり無茶をすると ACCESS ファイルが壊れそうな気がするのですが、まあ SELECT だけならば大丈夫でしょう。
付属するデータは、LINQ の場合は Include を使って取ってきてもよいのですが、外部キーの記述が結構面倒(標準にあっていないとうまくいかないことが多い)ので、あとから手作業でとってきています。多少検索スピードは落ちますが、ツール的にはこれで十分でしょう。まじめに作るときは SQL Server 等にデータを移行&カラム名を連携しやすいように直します。
public static class DataTableExtenstions
{
public static DataTable AsDataTable<T>(this DbSet<T> src) where T : class
{
return DataTableExtenstions.AsDataTable(src.Local);
}
public static DataTable AsDataTable<T>(this IEnumerable<T> src) where T : class
{
var properties = typeof(T).GetProperties();
var dest = new DataTable();
// テーブルレイアウトの作成
foreach (var prop in properties)
{
DataColumn dc = new DataColumn();
dc.ColumnName = prop.Name;
if (prop.PropertyType.IsGenericType &&
prop.PropertyType.GetGenericTypeDefinition() == typeof(Nullable<>))
{
dc.DataType = Nullable.GetUnderlyingType(prop.PropertyType);
dc.AllowDBNull = true;
} else
{
dc.DataType = prop.PropertyType;
}
dest.Columns.Add(dc);
}
// 値の投げ込み
foreach (var item in src)
{
var row = dest.NewRow();
foreach (var prop in properties)
{
var itemValue = prop.GetValue(item, new object[] { });
row[prop.Name] = itemValue ?? System.DBNull.Value;
}
dest.Rows.Add(row);
}
return dest;
}
}
データを投入するときに null から System.DBNull.Value にしておきます。
private void blukSave<T>(string tablename, IEnumerable<T> items, bool keepid = true ) where T : class
{
var cnstr = toEnt.Database.GetDbConnection().ConnectionString;
SqlBulkCopy bc;
if (keepid == true)
{
bc = new SqlBulkCopy(cnstr, SqlBulkCopyOptions.KeepIdentity);
}
else
{
bc = new SqlBulkCopy(cnstr);
}
bc.DestinationTableName = tablename;
var dt = items.AsDataTable();
bc.WriteToServer(dt);
}
確か、以前の BulkCopy は ID をインクリメントしなかったような気がするのですが、現在の SqlBulkCopy は ID を挿入時にインクリメントしてしまいます。大量データを投入するときは、ID はあらかじめ振ってあることが多い(他のデータから移行するため)ので、INSERT 時に ID の値が変わらないようにします。
オプションで SqlBulkCopyOptions.KeepIdentity をつけておきます。
実際の使い方はこんな感じ。予約テーブルは実は ACCESS から移行するデータなので大量に Nullable が入っています。いったん List にため込んでから、BlukCopy を行うので一時的にため込まれる List のメモリ量が心配ですが、まあ、大丈夫でしょう。最初の DropTable 関数は、内部で TRUNCATE TABLE を呼び出しています。
public bool To予約()
{
DropTable("予約");
var lst = new List<予約>();
foreach (var it in fromEnt.T_予約)
{
var t = new 予約();
t.ID = it.KID;
t.顧客ID = it.TID.Value;
t.顧客SUBID = it.TIDa ?? 0;
t.予約者 = it.予約者;
...
t.UpdateAt = DateTime.Now;
lst.Add(t);
}
this.blukSave("予約", lst);
return true;
}
かねてから、接触確認API(Exposure Notifications API)は自作しないとあかんな、と思っていたのでおもむろに自作してみることにします。要は、接触確認アプリのテストがしにくい(EN API が有効な保健省アカウントしかできない)ので、一般サイドから見ると「きちんと動いているかどうかわからない」のが問題ですね。これは、COCOA 自体から EN API を触るときも同様で、去年の6月当初から検証しにくい環境であることができになっています。
で、EN API については内部的な細かい動作はさておき、仕様は Apple/Google の共同文書ということで公開されています。
たぶん、こんな風に ListView を使ったはず。ボタンをクリックしたときに Web API を呼び出すのはこんな感じ。
private async void clickGroup(object sender, EventArgs e)
{
var cl = new HttpClient();
var url = new Uri("http://192.168.1.28:5000/api/areagroup");
var json = await cl.GetStringAsync(url);
var js = new JsonSerializer();
var items = JsonConvert.DeserializeObject<List<AreaGroup>>(json);
this.lv.ItemsSource = items;
}
Web API 自体はローカルな dotnet で動かしているので、IP アドレスはローカルコンピュータのものになっている。Android エミュレータから呼び出すことになるので localhost ではなく、IP アドレスになっている。
さて、実はこれを動かすと次のようなエラーになる。
System.Net.WebException: 'Cleartext HTTP traffic to 192.168.1.28 not permitted'
さて、Xamarin.Forms で動くようになったので、これを Visual Studio 2022 の MAUI のほうにコピーする。
XAML のほうは、そのままコピーで ok.
コードのほうはこんな感じ。
using System;
using System.ComponentModel.DataAnnotations;
using System.ComponentModel.DataAnnotations.Schema;
using Microsoft.Maui.Controls;
using System.Net.Http;
using System.Net.Http.Json;
using System.Collections.Generic;
namespace HelloWebApi
{
public partial class MainPage : ContentPage
{
public MainPage()
{
InitializeComponent();
}
private async void clickGroup(object sender, EventArgs e)
{
var httpHandler = new HttpClientHandler { ServerCertificateCustomValidationCallback = (o, cert, chain, errors) => true };
var cl = new HttpClient(httpHandler);
var url = new Uri("https://192.168.1.28:5001/api/areagroup");
var items = await cl.GetFromJsonAsync<List<AreaGroup>>(url);
this.lv.ItemsSource = items;
}
}
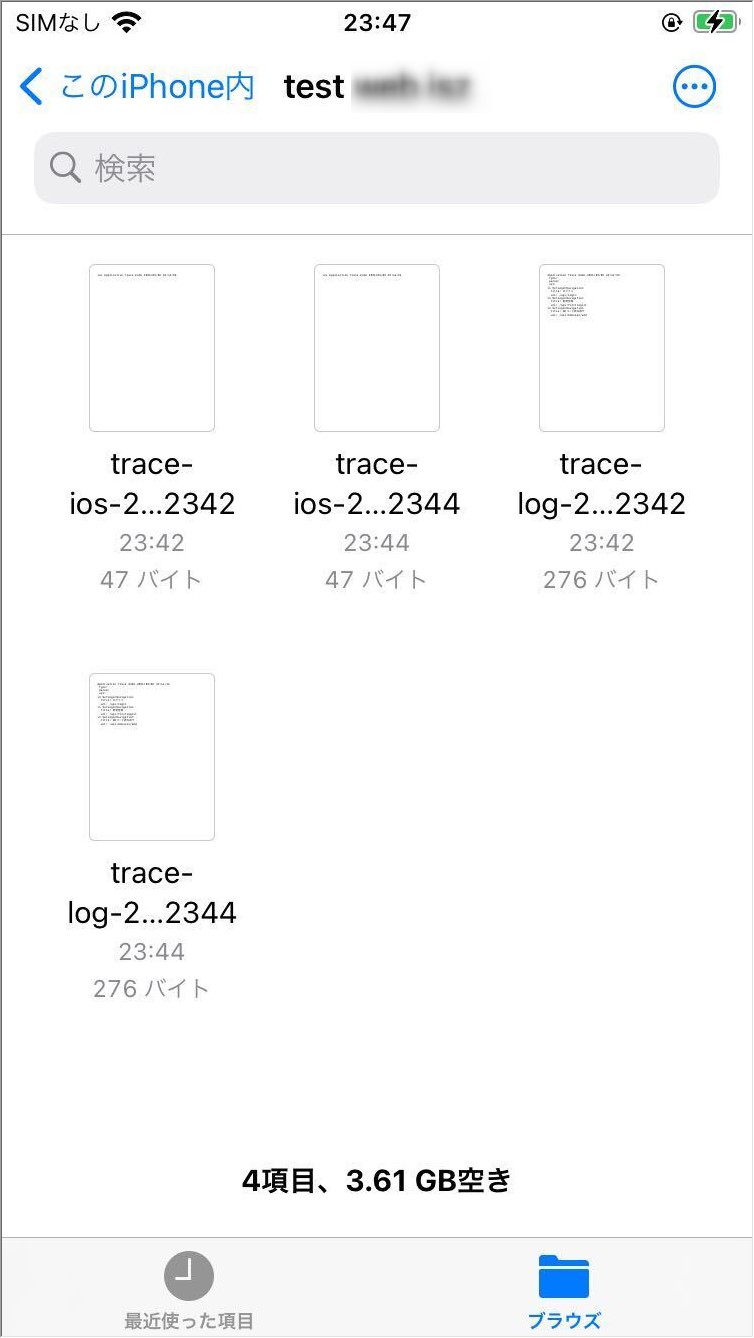
var dir = Environment.GetFolderPath(Environment.SpecialFolder.MyDocuments);
var filename = Path.Combine(dir, $"log-{DateTime.Now.ToString("yyyyMMdd-HHmm")}.txt");
var tw = System.IO.File.OpenWrite(filename);
var tr1 = new TextWriterTraceListener(tw);
System.Diagnostics.Trace.AutoFlush = true;
System.Diagnostics.Trace.Listeners.Add(tr1);
var contextRef = new WeakReference<Context>(this);
contextRef.TryGetTarget(outvar c);
var dir = c.GetExternalFilesDir(null).AbsolutePath;
var filename = Path.Combine(dir, $"droid-{DateTime.Now.ToString("yyyyMMdd-HHmm")}.txt");
var tw = System.IO.File.OpenWrite(filename);
this.tr1 = new TextWriterTraceListener(tw);
DroidTrace.AutoFlush = true;
DroidTrace.Listeners.Add(tr1);
DroidTrace.WriteLine("ios Application Trace mode " + DateTime.Now.ToString());
var dir = Environment.GetFolderPath(Environment.SpecialFolder.MyDocuments);
if ( Device.RuntimePlatform == Device.Android )
{
// Android の場合は決め打ちにする
dir = "/storage/emulated/0/Android/data/<バンドル名>/files";
}
var filename = Path.Combine(dir, $"log-{DateTime.Now.ToString("yyyyMMdd-HHmm")}.txt");
var tw = System.IO.File.OpenWrite(filename);
var tr1 = new TextWriterTraceListener(tw);
System.Diagnostics.Trace.AutoFlush = true;
System.Diagnostics.Trace.Listeners.Add(tr1);
お手軽なデバッグ出力ではありますが、常に Visual Studio から起動しないといけないのはいささか面倒です。特に、スマホのアプリの場合は、スマホ単体でアプリを起動することが多く、テスト作業をするにしても Visual Studio から常に立ち上げるのは難しいでしょう。ブレークポイントを置いて何らかのチェックをしたい場合はもあるでしょうが、一連の動きをデバッグ出力としてファイルに保存しておくのがよいでしょう。
var tw = System.IO.File.OpenWrite(filename);
var tr1 = new TextWriterTraceListener(tw);
System.Diagnostics.Trace.AutoFlush = true;
System.Diagnostics.Trace.Listeners.Add(tr1);
var dir = Environment.GetFolderPath(Environment.SpecialFolder.MyDocuments);
var filename = Path.Combine(dir, $"log-{DateTime.Now.ToString("yyyyMMdd-HHmm")}.txt");
publicclassIosTrace
{
staticIosTrace()
{
Listeners = new List<TraceListener>();
}
publicstatic List<TraceListener> Listeners { get; }
publicstaticbool AutoFlush { get; set; } = true;
publicstaticvoidWriteLine(string message)
{
foreach ( var it in Listeners)
{
it.WriteLine(message);
if ( AutoFlush == true ) it.Flush();
}
}
}
もとの System.Diagnostics.Trace と同じ様に Listeners コレクションに TextWriterTraceListener オブジェクトを追加すれば ok です。ファイル名は、Xamarin.Forms の共通プロジェクトで作ったものとは別にしておきます。
var dir = Environment.GetFolderPath(Environment.SpecialFolder.MyDocuments);
var filename = Path.Combine(dir, $"ios-{DateTime.Now.ToString("yyyyMMdd-HHmm")}.txt");
var tw = System.IO.File.OpenWrite(filename);
var tr1 = new TextWriterTraceListener(tw);
IosTrace.AutoFlush = true;
IosTrace.Listeners.Add(tr1);
というのがシステム構成になっていると思います。静的 HTML を作るツールはいくつかあるのでしょうが(wordpress でも作れる)、問題となるのはシステム的なスピードよりも、移行対象となるページの多さです。最終的にどの位のページ数になったのかは不明ですが、要件段階で 2000ページ以上あることが明言されています。
ともあれ、全体的には静的 HTML にしてあるので、体感的に表示が早くなっています。
実は、データベースを適切に配置させて、あまり入れ子にならないビュー専用の WordPress っぽいものを作るのと、静的 HTML 生成を動的に行えば似た感じのスピードは出せるので、静的 HTML にこだわる必要はないのですが、ここは「要件」なので仕方がない。
気象情報、緊急情報がトップページにあるので、災害時に20万人にリロードされるのは、トップページになります。いちばん重いのは jQuery 位で、初回に画像読みに少し時間が掛かるぐらいですね。災害時のメッセージ(現在では「12時間以内に配信した情報はありません。」になっているところ)は、Web API を呼び出して jQuery で埋め込んでいるようです。