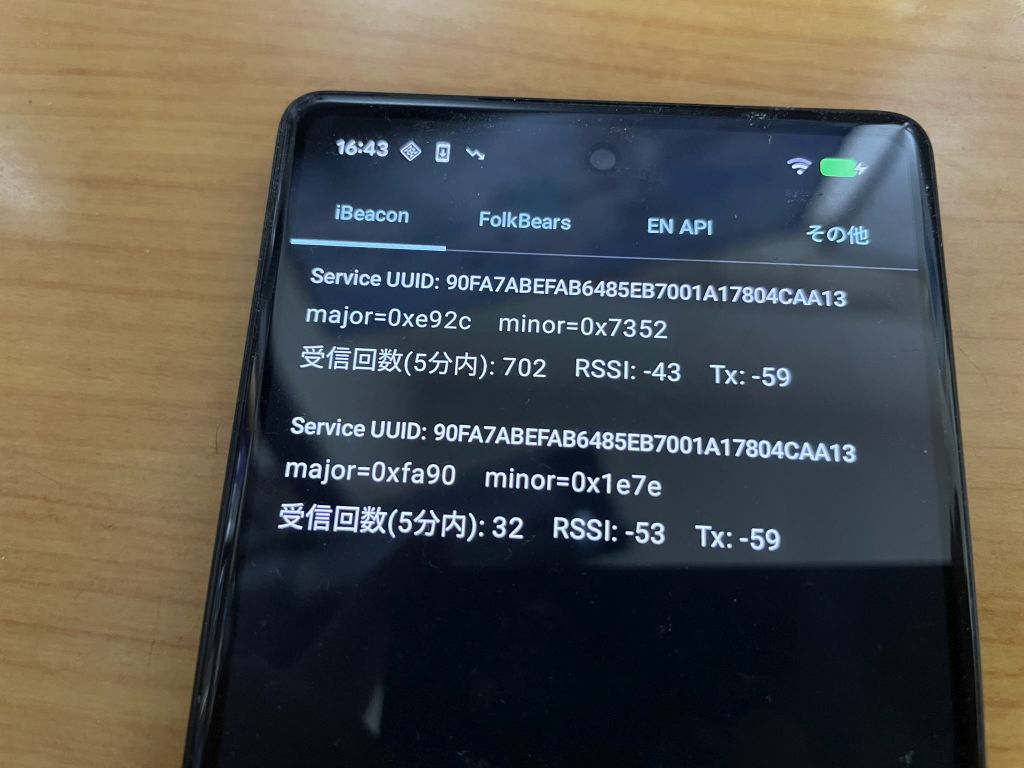
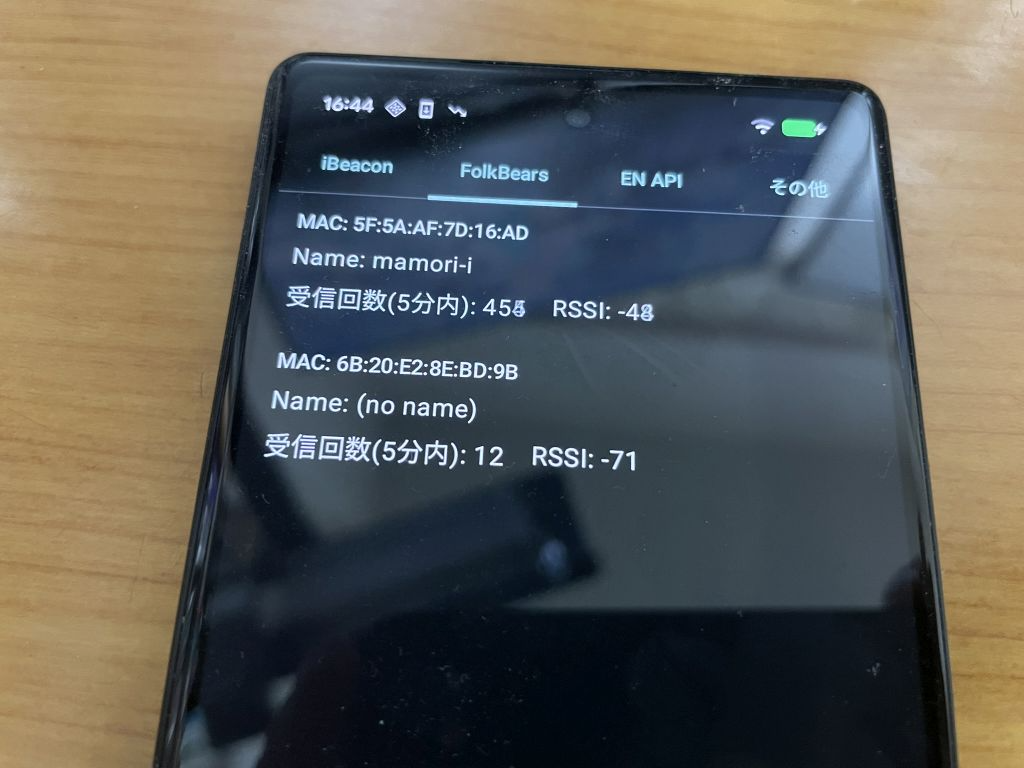
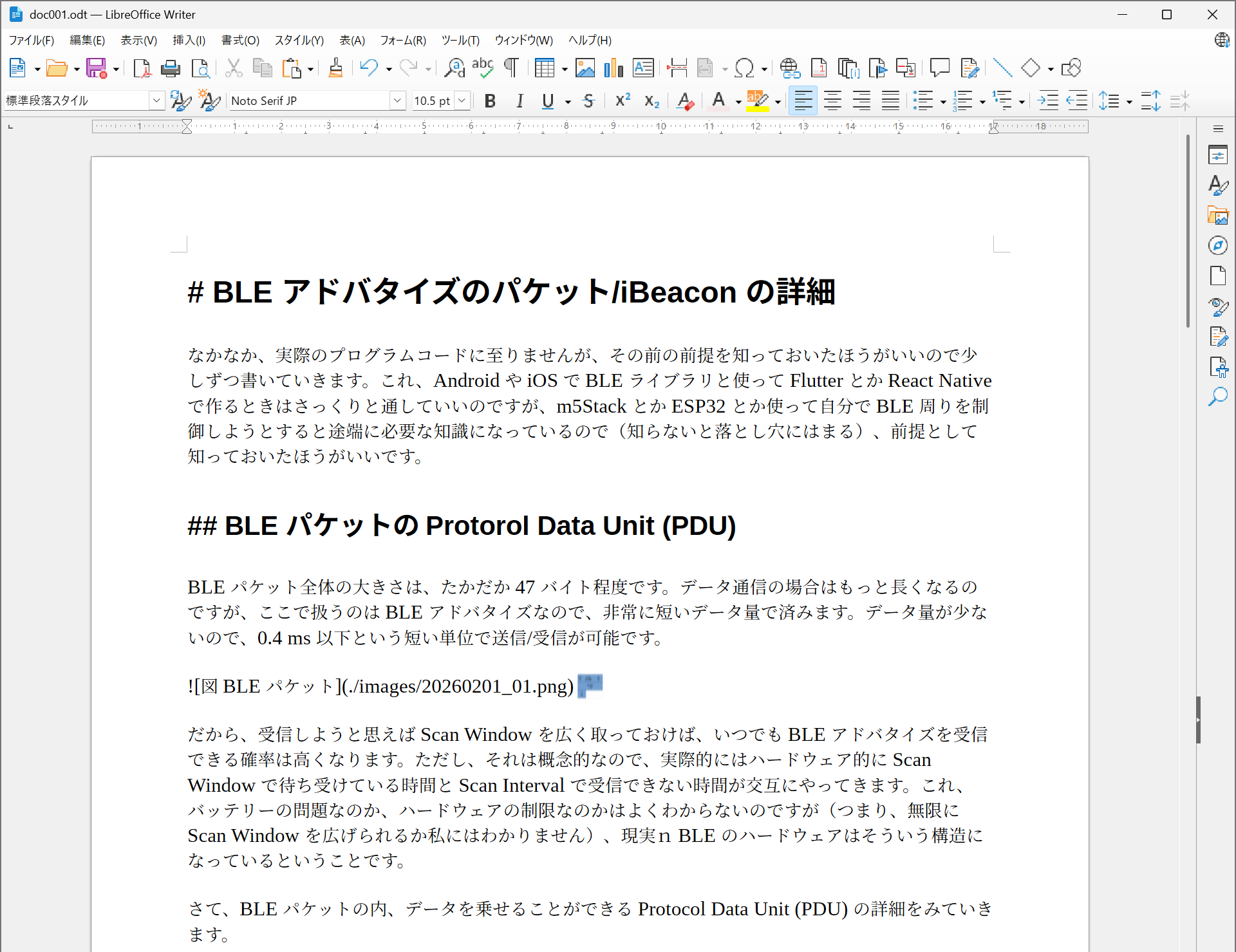
Android で iBeacon/EN API 受信機を作ることができたので、次は iPhone(iOS) で作ってみます。先に書いた通り、Android と iOS では Beacon の受信方法が異なります。さらに、iOS では Scan Window/Scan Interval の細かい動作を指定することができません。
で、Apple 版と Android 版の両方の受信機を作ったときに、どうやら Android のほうが受信頻度がいまいちなんですよね…という確認のために iOS 版を作って比較します。
結論から先に言うと、Android 版のほうは SCAN_MODE_LOW_POWER で動かして省電力化すると、iOS 版と比べて相当受信頻度が落ちます。逆に言えば iOS 版のほうがバッテリーの消耗が激しいということです。このあたりも後に確認したいです。SCAN_MODE_LOW_LATENCY で動かすと、Android 版のほうも受信頻度が上がるのですが、これも iOS 版と比べるとどの位の頻度でいけるのか同程度なのか?ということもいずれ調べていきます。
SwiftUI で作る
FolkBears 本体は従来の storyboard で作ってあるのですが、今は SwiftUI で作るのが楽なので、今回の受信機は SwiftUI で作っていきます。本体 FolkBears も SwiftUI 形式に移行中です。
struct ContentView: View {
var body: some View {
TabView {
IBeaconTabView()
.tabItem { Label("iBeacon", systemImage: "dot.radiowaves.left.and.right") }
FolkBearsTabView()
.tabItem { Label("FolkBears", systemImage: "antenna.radiowaves.left.and.right") }
EnApiTabView()
.tabItem { Label("EN API", systemImage: "waveform.path") }
ManufacturerDataTabView()
.tabItem { Label("Mfr Data", systemImage: "barcode") }
}
}
}
// MARK: - iBeacon
private struct IBeaconTabView: View {
@StateObject private var scanner = BeaconScan()
@State private var detectionLog: [(id: String, beacon: CLBeacon, date: Date)] = []
@State private var summaries: [BeaconSummary] = []
private let windowSeconds: TimeInterval = 5 * 60
var body: some View {
NavigationView {
VStack(alignment: .leading, spacing: 16) {
HStack {
Text("状態: \(scanner.scanningStatus)")
Spacer()
Button(scanner.isScanning ? "停止" : "開始") {
scanner.isScanning ? scanner.stopScanning() : scanner.startScanning()
}
.buttonStyle(.borderedProminent)
}
if summaries.isEmpty {
Text("受信した iBeacon がまだありません")
.foregroundStyle(.secondary)
.frame(maxWidth: .infinity, alignment: .leading)
} else {
List(summaries) { summary in
BeaconRow(summary: summary)
}
.listStyle(.plain)
}
}
.padding()
.navigationTitle("iBeacon")
.onAppear {
scanner.onIBeacon = { beacon, date in
addDetection(beacon, at: date)
}
if !scanner.isScanning { scanner.startScanning() }
}
.onDisappear {
detectionLog.removeAll()
summaries.removeAll()
}
}
}
private func addDetection(_ beacon: CLBeacon, at date: Date) {
let id = "\(beacon.uuid.uuidString)-\(beacon.major.intValue)-\(beacon.minor.intValue)"
detectionLog.append((id: id, beacon: beacon, date: date))
// 5分より古いログを削除
detectionLog = detectionLog.filter { date.timeIntervalSince($0.date) <= windowSeconds }
// 集計
let grouped = Dictionary(grouping: detectionLog, by: { $0.id })
summaries = grouped.values.compactMap { entries in
guard let latest = entries.max(by: { $0.date < $1.date }) else { return nil }
return BeaconSummary(
id: latest.id,
uuid: latest.beacon.uuid,
major: latest.beacon.major.uint16Value,
minor: latest.beacon.minor.uint16Value,
rssi: latest.beacon.rssi,
accuracy: latest.beacon.accuracy,
proximity: latest.beacon.proximity,
count: entries.count
)
}
.sorted { $0.count > $1.count }
}
}
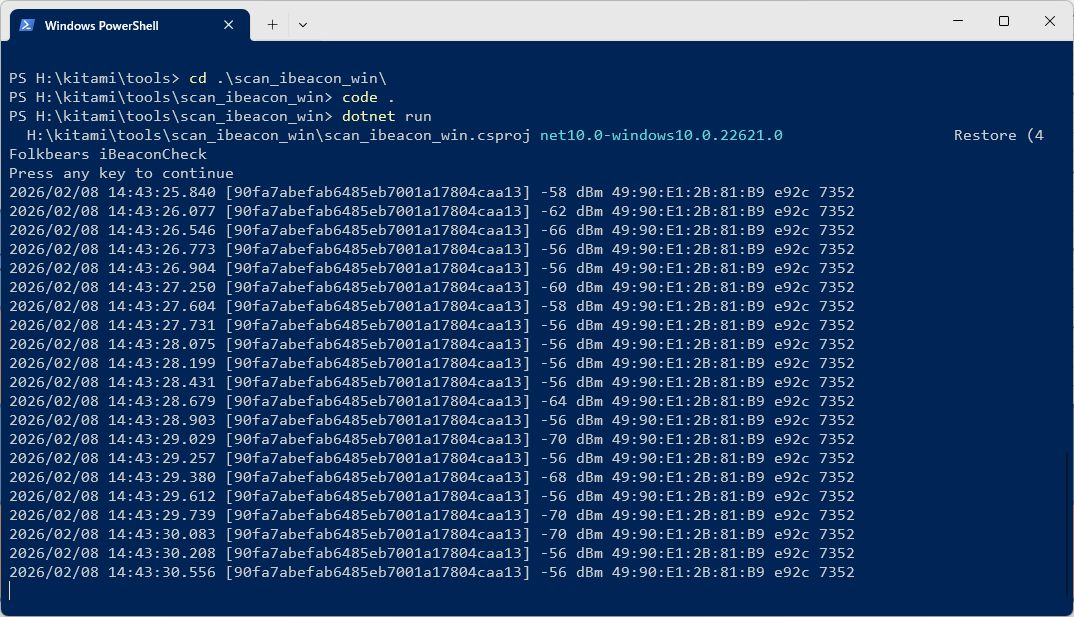
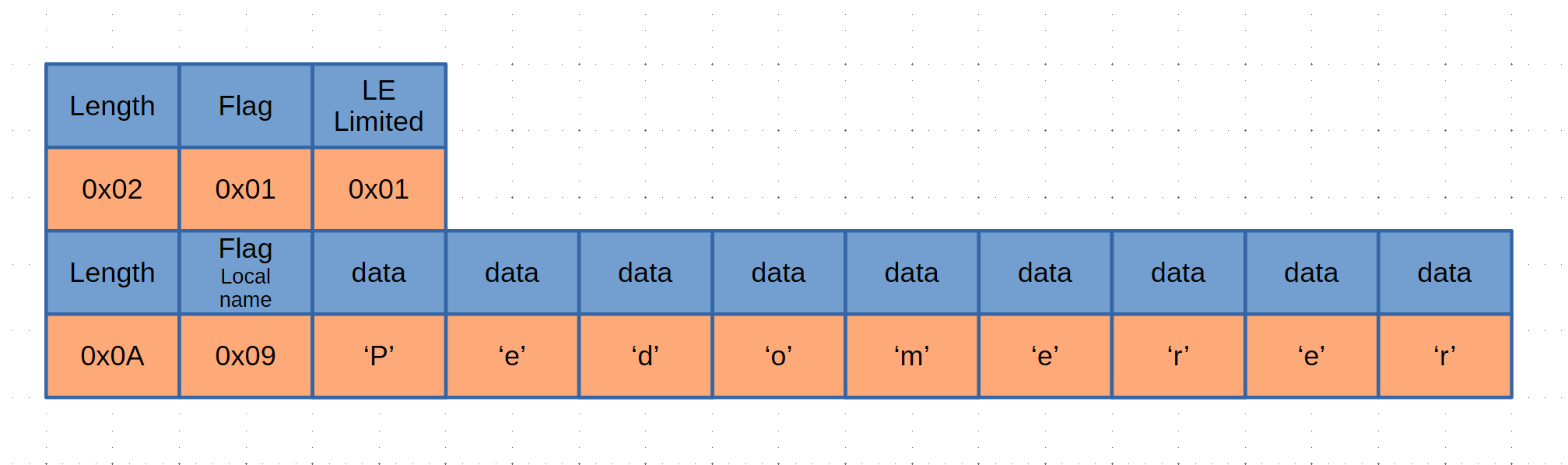
iBeacon を受信する
iOS で iBeacon を使って近接検出する場合には、CLBeaconRegion と CLLocationManager の両方を使います。このあたりの動きは Android と異なるので注意してください。もともと、iBeacon の利用が、店舗などに配置された Beacon を検出する=店内に入ったことを検出するという用途になっているので、Beacon 検出は、ある領域に入った時、あるいは出たときにしかイベントが発生しません。
このために、既に Beacon の領域に入っている時にアプリを立ち上げるとイベントが発生しません。あらかじめ、領域外のところでアプリを立ち上げて、Beacon の領域に入らなくてはいけません。
何故、こんな仕様になっているのか不思議ですが、たまに「店内に入る前にアプリを立ち上げて~」というアナウンスがあるのはこのためでしょう。
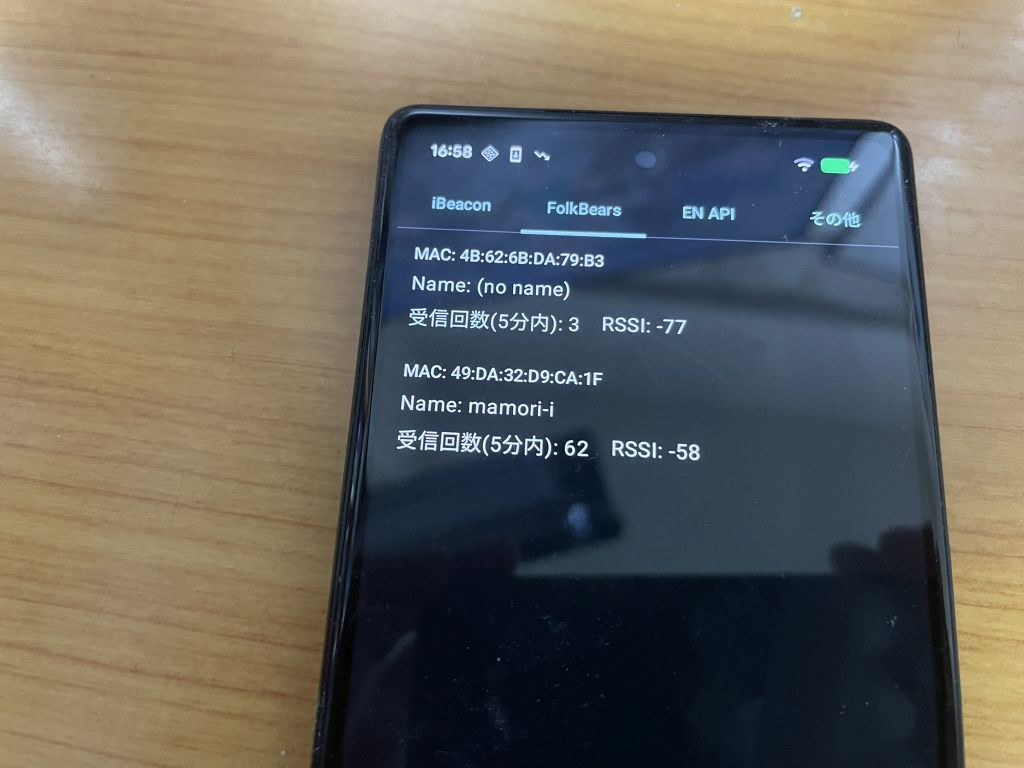
FolkBears の受信機では、Android 版のように連続して Beacon を受信して欲しいので、CLLocationManagerDelegate の locationManager(_ manager: CLLocationManager, didRange beacons: [CLBeacon], satisfying beaconConstraint: CLBeaconIdentityConstraint) を使って、定期的に受信するようにしています。
class BeaconScan: NSObject, ObservableObject {
private var locationManager: CLLocationManager
private var beaconRegion: CLBeaconRegion?
private var beaconConstraint: CLBeaconIdentityConstraint?
/// iBeacon検出時に呼ばれるコールバック(UIで集計するため)
var onIBeacon: ((CLBeacon, Date) -> Void)?
@Published var discoveredBeacons: [CLBeacon] = []
@Published var isScanning = false
@Published var scanningStatus = "停止中"
// デフォルトのiBeacon設定
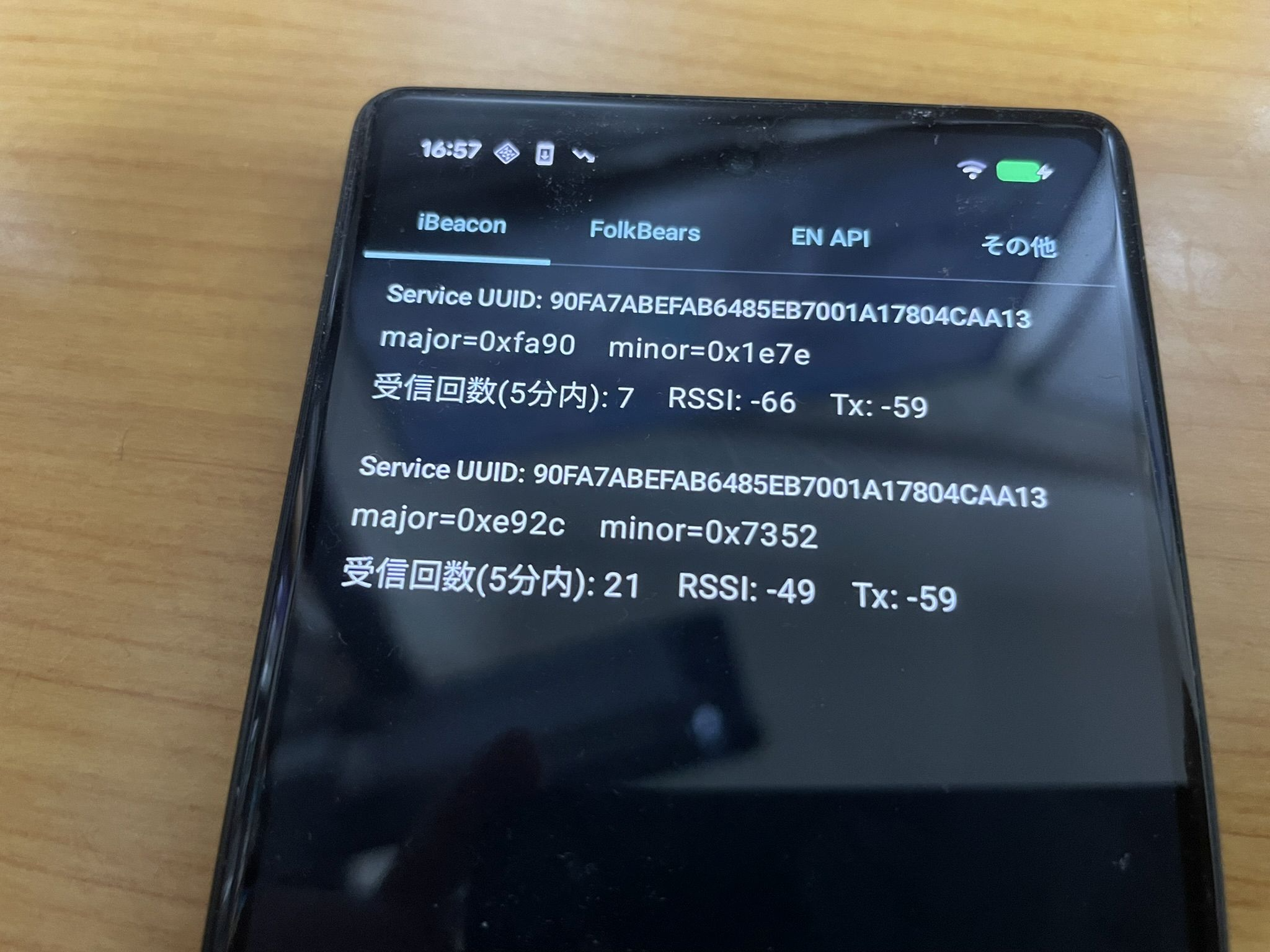
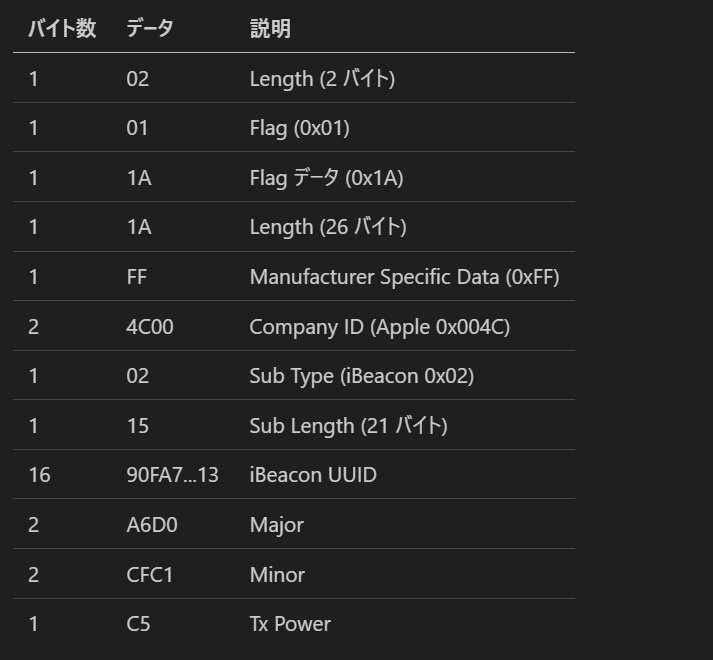
private let defaultUUID = UUID(uuidString: "90FA7ABE-FAB6-485E-B700-1A17804CAA13")!
private let defaultIdentifier = "FolkBearsBeacon"
override init() {
self.locationManager = CLLocationManager()
super.init()
setupLocationManager()
}
private func setupLocationManager() {
locationManager.delegate = self
// iBeaconレンジングには「このAppの使用中」以上が必要。バックグラウンド受信する場合は Always も要求する。
if locationManager.authorizationStatus == .notDetermined {
locationManager.requestWhenInUseAuthorization()
}
}
func startScanning() {
guard !isScanning else { return }
// ビーコンリージョンを作成
beaconRegion = CLBeaconRegion(
uuid: defaultUUID,
identifier: defaultIdentifier
)
beaconConstraint = CLBeaconIdentityConstraint(uuid: defaultUUID)
guard let region = beaconRegion else { return }
// リージョンモニタリング開始
locationManager.startMonitoring(for: region)
// すぐにレンジング開始(既にリージョン内にいる場合 didEnterRegion が来ないことがあるため)
if let constraint = beaconConstraint {
locationManager.startRangingBeacons(satisfying: constraint)
}
isScanning = true
scanningStatus = "スキャン中..."
print("iBeacon スキャン開始")
}
func stopScanning() {
guard isScanning else { return }
if let region = beaconRegion {
locationManager.stopMonitoring(for: region)
}
if let constraint = beaconConstraint {
locationManager.stopRangingBeacons(satisfying: constraint)
}
isScanning = false
scanningStatus = "停止中"
discoveredBeacons.removeAll()
print("iBeacon スキャン停止")
}
}
// MARK: - CLLocationManagerDelegate
extension BeaconScan: CLLocationManagerDelegate {
func locationManager(_ manager: CLLocationManager, didEnterRegion region: CLRegion) {
guard let beaconRegion = region as? CLBeaconRegion else { return }
print("ビーコンリージョンに入りました: \(beaconRegion.identifier)")
// レンジング開始
let constraint = beaconConstraint ?? CLBeaconIdentityConstraint(uuid: beaconRegion.uuid)
beaconConstraint = constraint
locationManager.startRangingBeacons(satisfying: constraint)
}
func locationManager(_ manager: CLLocationManager, didExitRegion region: CLRegion) {
guard let beaconRegion = region as? CLBeaconRegion else { return }
print("ビーコンリージョンから出ました: \(beaconRegion.identifier)")
// レンジング停止
let constraint = beaconConstraint ?? CLBeaconIdentityConstraint(uuid: beaconRegion.uuid)
locationManager.stopRangingBeacons(satisfying: constraint)
}
func locationManager(_ manager: CLLocationManager, didRange beacons: [CLBeacon], satisfying beaconConstraint: CLBeaconIdentityConstraint) {
let now = Date()
let validBeacons = beacons.filter { $0.proximity != .unknown }
DispatchQueue.main.async {
self.discoveredBeacons = validBeacons
self.scanningStatus = "検出: \(validBeacons.count)個"
}
for beacon in validBeacons {
let majorHex = String(format: "%04X", beacon.major.uint16Value)
let minorHex = String(format: "%04X", beacon.minor.uint16Value)
print("ビーコン検出 - UUID: \(beacon.uuid), Major: 0x\(majorHex), Minor: 0x\(minorHex), RSSI: \(beacon.rssi), Distance: \(String(format: "%.2f", beacon.accuracy))m")
DispatchQueue.main.async {
self.onIBeacon?(beacon, now)
}
}
}
func locationManager(_ manager: CLLocationManager, didFailWithError error: Error) {
print("Location Manager エラー: \(error.localizedDescription)")
DispatchQueue.main.async {
self.scanningStatus = "エラー"
}
}
func locationManager(_ manager: CLLocationManager, didChangeAuthorization status: CLAuthorizationStatus) {
switch status {
case .authorizedWhenInUse, .authorizedAlways:
print("位置情報の使用が許可されました")
// 権限取得後にスキャン指示が出ていた場合、レンジングを開始しておく
if isScanning {
let constraint = beaconConstraint ?? CLBeaconIdentityConstraint(uuid: defaultUUID)
beaconConstraint = constraint
locationManager.startRangingBeacons(satisfying: constraint)
}
case .denied, .restricted:
print("位置情報の使用が拒否されました")
DispatchQueue.main.async {
self.scanningStatus = "位置情報権限が必要"
}
case .notDetermined:
print("位置情報の権限が未確定")
@unknown default:
break
}
}
}
指定した UUID の iBeacon しか検出できない
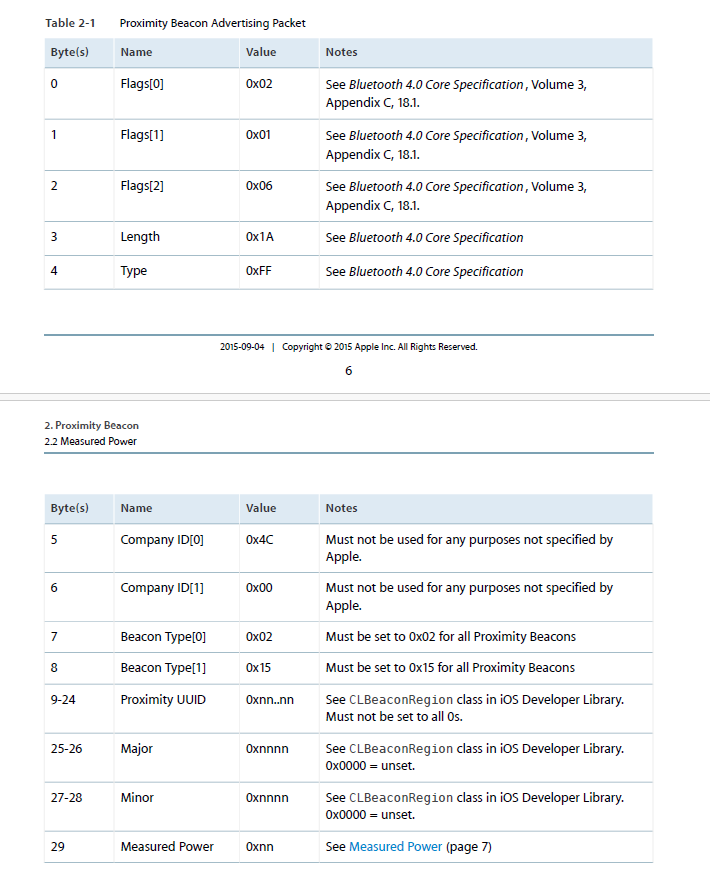
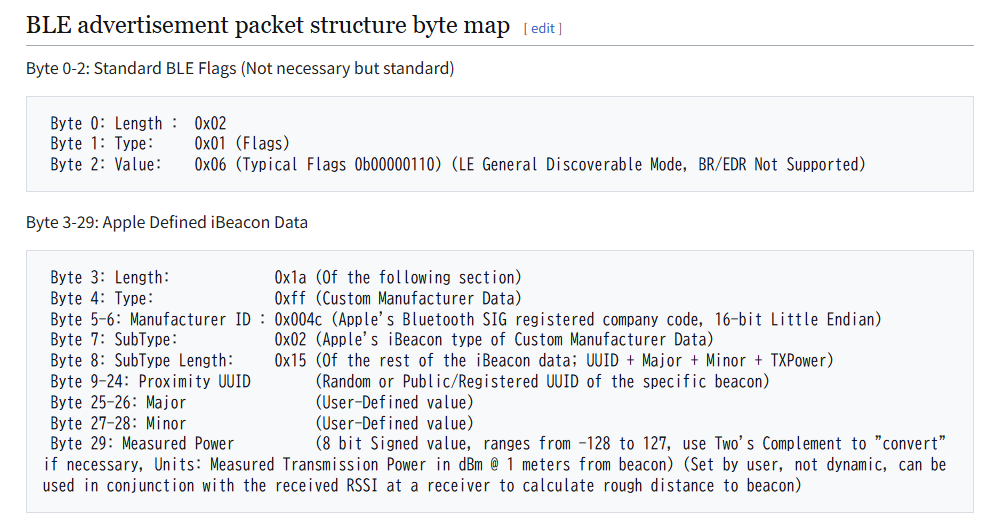
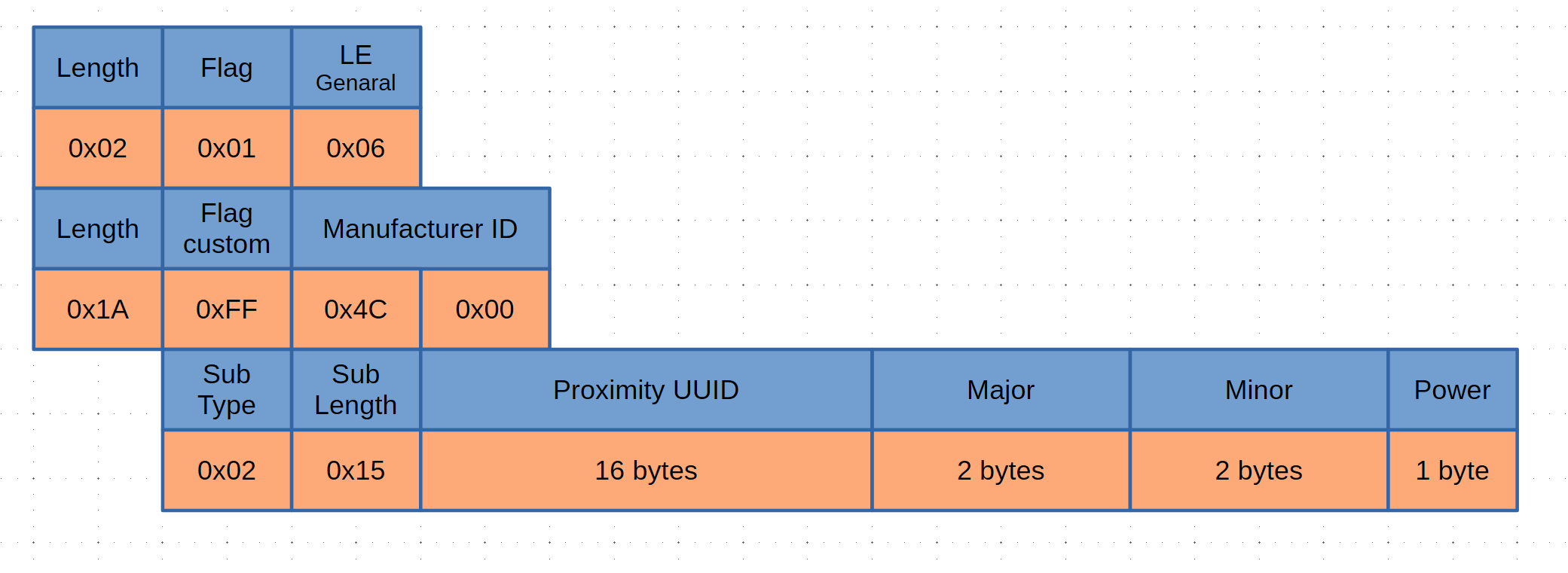
Android 版ではひとまず iBeacon 形式のものを受信してから UUID をチェックすることができましたが、iOS 版では、あらかじめ指定した UUID の iBeacon しか検出できません。確か 10 個程度しか登録できないので、複数の UUID を同時に使うときは、何らかの形で beaconRegion を切り替える必要があります。
func startScanning() {
guard !isScanning else { return }
// ビーコンリージョンを作成
beaconRegion = CLBeaconRegion(
uuid: defaultUUID,
identifier: defaultIdentifier
)
beaconConstraint = CLBeaconIdentityConstraint(uuid: defaultUUID)
guard let region = beaconRegion else { return }
// リージョンモニタリング開始
locationManager.startMonitoring(for: region)
// すぐにレンジング開始(既にリージョン内にいる場合 didEnterRegion が来ないことがあるため)
if let constraint = beaconConstraint {
locationManager.startRangingBeacons(satisfying: constraint)
}
isScanning = true
scanningStatus = "スキャン中..."
print("iBeacon スキャン開始")
}
現在、固定の UUID しか受信できないので、アプリから複数 UUID を指定できるといいでしょう。通常は、UUID を固定にしておいて major と minor で識別することが多いです。
major と minor を ID として使う
CLLocationManagerDelegate#locationManager で受け取ったときに、CLBeacon の major と minor を取り出すことができます。FolkBears では、major と minor をワンセットにして TempUserID として使っています。
func locationManager(_ manager: CLLocationManager, didRange beacons: [CLBeacon], satisfying beaconConstraint: CLBeaconIdentityConstraint) {
let now = Date()
let validBeacons = beacons.filter { $0.proximity != .unknown }
DispatchQueue.main.async {
self.discoveredBeacons = validBeacons
self.scanningStatus = "検出: \(validBeacons.count)個"
}
for beacon in validBeacons {
let majorHex = String(format: "%04X", beacon.major.uint16Value)
let minorHex = String(format: "%04X", beacon.minor.uint16Value)
print("ビーコン検出 - UUID: \(beacon.uuid), Major: 0x\(majorHex), Minor: 0x\(minorHex), RSSI: \(beacon.rssi), Distance: \(String(format: "%.2f", beacon.accuracy))m")
DispatchQueue.main.async {
self.onIBeacon?(beacon, now)
}
}
}
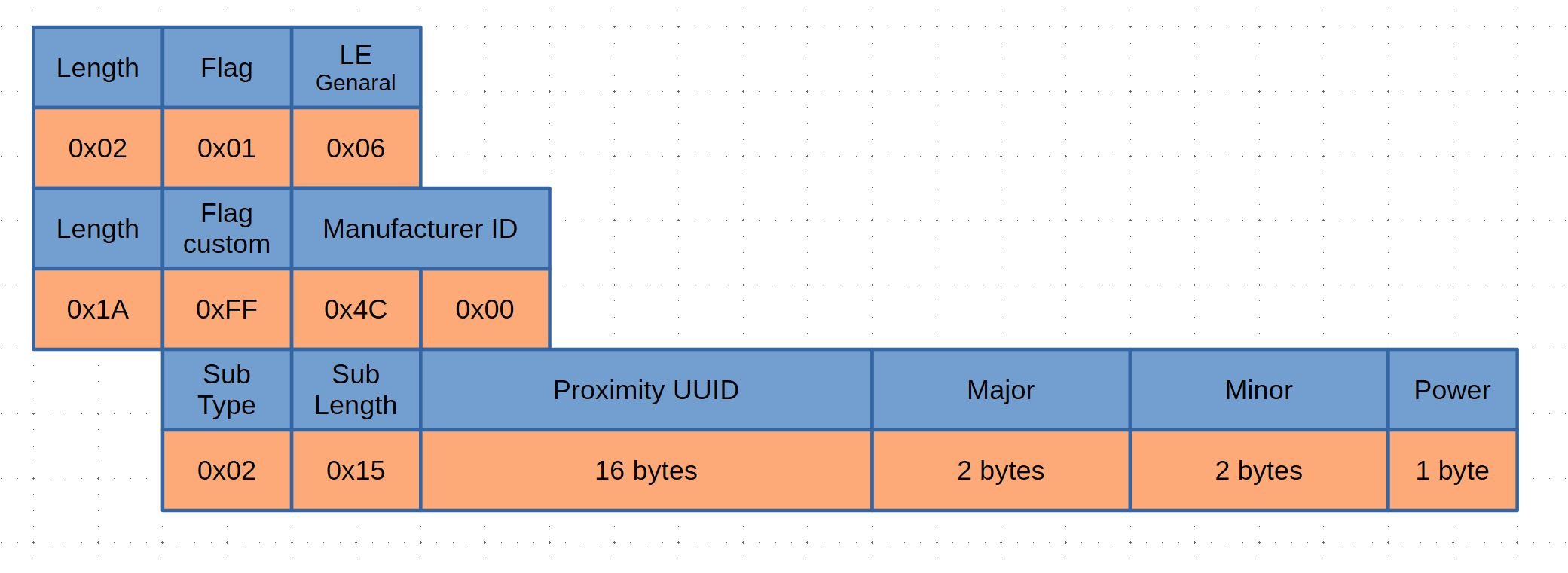
EN API 形式を受信する
COCOA で使っていた EN API 形式の受信機も iOS 版を作っていきます。つまりは、16 bit Service UUID を指定して受信するパターンです。CBCentralManager を使います。
これ、ずっと勘違いしていたのですが、iOS で 16 bit Service UUID は受信できますね。現在 EN API の 0xFD6F は塞がれたままなのですが、別の 16 bit Service UUID を送ると iOS で受信ができます。他の UUID とぶつからないように実験的に 0xFF00 を使うと受信できることが確認できます。
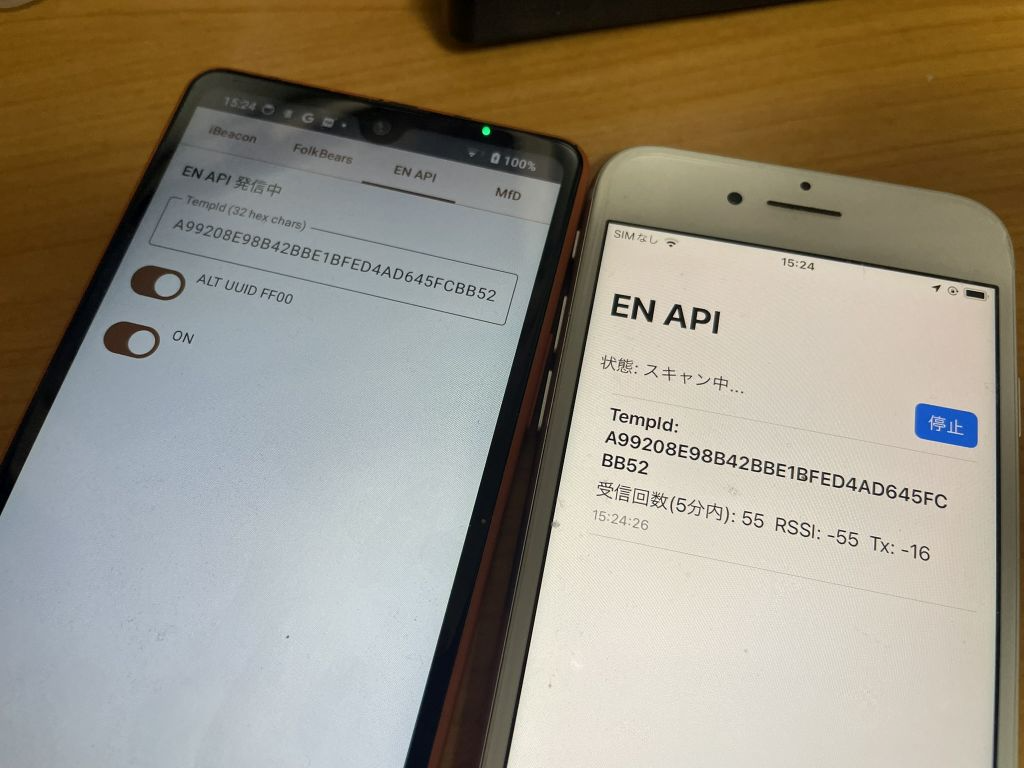
ちなみに iOS は 16 bit Service UUID で発信ができません。接触確認アプリの場合は受発信が必要なのでこのパターンは使えないのですが、何らかのデバイスで発信(m5stack など)したものを、iOS で受信することは十分可能です。なので、入場確認とかにこの方式が使えます。勿論、Bluetooth SIG で 16 bit Service UUID が必須になりますが…まあ、実験的にということで。
final class ENSimScan: NSObject, ObservableObject {
/// 受信時のコールバック(UI側で集計する想定)
var onReadTraceData: ((TraceData) -> Void)?
@Published var isScanning = false
@Published var scanningStatus = "停止中"
private var centralManager: CBCentralManager!
// ENSim (Exposure Notification Simulator) サービス UUID
private let serviceUUID = CBUUID(string: "0000FD6F-0000-1000-8000-00805F9B34FB")
private let serviceDataUUID = CBUUID(string: "0000FD6F-0000-1000-8000-00805F9B34FB")
private let serviceUUIDalt = CBUUID(string: "0000FF00-0000-1000-8000-00805F9B34FB")
private let serviceDataUUIDalt = CBUUID(string: "00000001-0000-1000-8000-00805F9B34FB")
override init() {
super.init()
setupCentralManager()
}
private func setupCentralManager() {
centralManager = CBCentralManager(delegate: self, queue: nil)
}
func startScan() {
guard centralManager.state == .poweredOn else {
print("ENSimScan: Bluetooth未準備のため開始できません state=\(centralManager.state.rawValue)")
return
}
guard !isScanning else { return }
centralManager.scanForPeripherals(
// withServices: [serviceUUID, serviceUUIDalt],
// FD6F を入れるとガードが掛かるので、外す
withServices: [serviceUUIDalt],
options: [CBCentralManagerScanOptionAllowDuplicatesKey: true]
)
isScanning = true
scanningStatus = "スキャン中..."
print("ENSimScan: スキャン開始")
}
func stopScan() {
guard isScanning else { return }
centralManager.stopScan()
isScanning = false
scanningStatus = "停止中"
print("ENSimScan: スキャン停止")
}
private func handleScanResult(peripheral: CBPeripheral, advertisementData: [String: Any], rssi: NSNumber) {
// サービスデータから tempId を取得(FD6F優先、FF00や派生UUIDも許容)
guard let serviceData = advertisementData[CBAdvertisementDataServiceDataKey] as? [CBUUID: Data] else { return }
let data = serviceData[serviceDataUUID]
?? serviceData[serviceUUID] // 一部デバイスはサービスUUIDでそのまま入る場合がある
?? serviceData[serviceUUIDalt] // 代替サービスUUID
?? serviceData[serviceDataUUIDalt] // 代替サービスデータUUID
guard let payload = data, !payload.isEmpty else { return }
let tempId = payload.map { String(format: "%02X", $0) }.joined()
let trace = TraceData(
timestamp: Date(),
tempId: tempId,
rssi: rssi.doubleValue,
txPower: (advertisementData[CBAdvertisementDataTxPowerLevelKey] as? NSNumber)?.doubleValue
)
print("ENSim 検出: \(peripheral.identifier.uuidString) tempId: \(tempId) rssi: \(rssi)")
onReadTraceData?(trace)
}
}
// MARK: - CBCentralManagerDelegate
extension ENSimScan: CBCentralManagerDelegate {
func centralManagerDidUpdateState(_ central: CBCentralManager) {
switch central.state {
case .poweredOn:
print("ENSimScan: Bluetooth On")
case .unauthorized:
print("ENSimScan: Bluetooth unauthorized")
case .unsupported:
print("ENSimScan: Bluetooth unsupported")
case .poweredOff:
print("ENSimScan: Bluetooth Off")
default:
break
}
}
func centralManager(_ central: CBCentralManager, didDiscover peripheral: CBPeripheral, advertisementData: [String: Any], rssi RSSI: NSNumber) {
handleScanResult(peripheral: peripheral, advertisementData: advertisementData, rssi: RSSI)
}
}
ここでは FD6F と FF00 の両方を受信するようにしたいところですが、scanForPeripherals で FD6F を指定すると FF00 のほうもガードが掛かって排除されてしまいます(苦笑)。なので、FF00 のほうだけ指定します。このガードの仕方はどうかと思うのですが、まあ、いいでしょう。
CBCentralManager のほうも BeaconRegion と同様に、フィルターする UUID の指定が必要になります。つまりは、受信するときのホワイトリストが必要になるわけです。どの程度の BLE デバイスのレベルでフィルターがかかっているかわかりませんが、アプリへのイベントは Android のようにすべてのイベントが飛んでくるわけではありません。
ちょっと長くなったので GATT 形式と Manufacturer Data 形式の受信機の解説は次回にします。
参考先
https://github.com/FolkBearsGroup/ble-tools/tree/master/folkbears-monitor-ios