
Google/Apple の提供する Exposure Notifications では BLE でビーコンを発信しています。内部的には 32 バイトなデータを Advertising/Broadcasting ってことになります。
コード自体は、openCACAO/CacaoBeacon: https://github.com/openCACAO/CacaoBeacon でビーコンの受信&収集コードを公開しています。CacaoBeaconMonitor が Android アプリです。iOS 版はありません。ENs では、ビーコンにある ID を受信するのですが、iOS の場合はこれが OS 側で塞がれているためです。なので、ビーコンのモニタリングとしては Android あるいは Windows を使います。
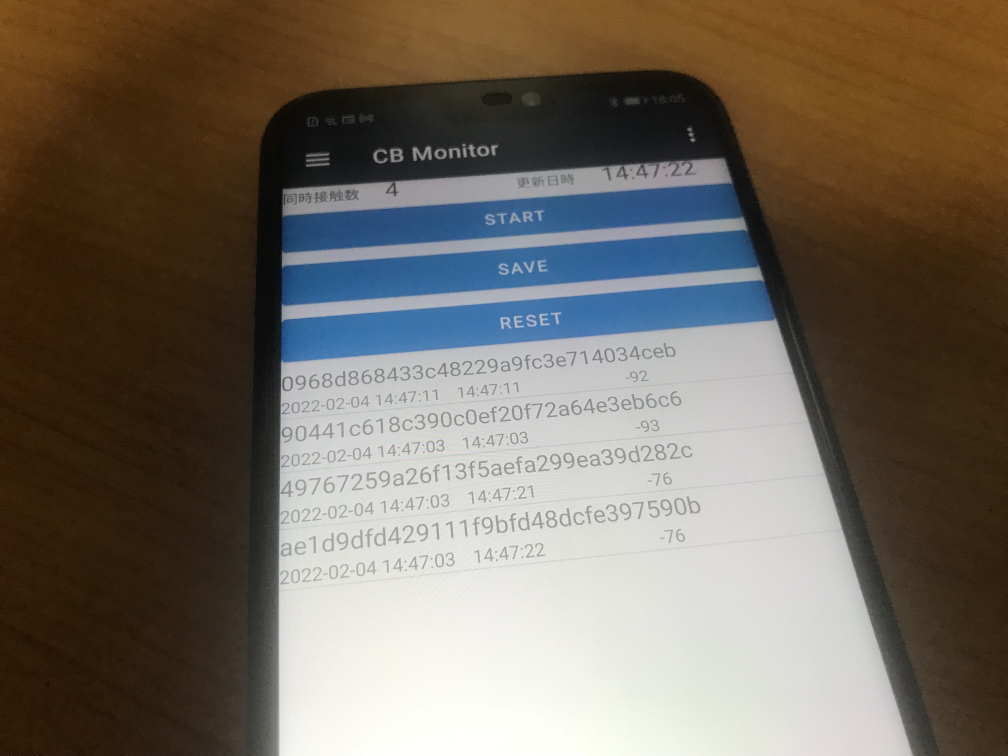
ノートパソコンを持ってうろうろするのは大変なので(定点観測ならばノートPCでも十分ですが)、Android のスマホを使います。
感染が拡大したので蒐集してみる
コード作ったのが4か月前で、去年の秋には東京都の感染者がぐんぐん減っている時期で、実験的なデータがとりずらい状態でした。で、まあ、とりあえず放置状態にしてあったのですが、第6波の勢いは尋常ではなく、現時点で東京都では2万/日をカウントしています。実に去年の秋の1000倍近い数字になってしまったわけですが。
COCOA自体の稼働率は、おそらく人口比で3割を超えています。通勤のような社会人に限っていれば、半分以上はあるっぽいです。 CacaoBeaconMonitor の場合は、COCOA から発信するビーコンを受けて RPI を保持していく Google/Apple の Exposure Notifications のクローンのような動作をさせているので、多分正確に収集ができます。
陽性者とのマッチングは別途、probetek で zip をダウンロードしてきて、SQL Server 上でクエリを書いています。
実測データ
2022年2月3日に、池袋を2時間ほど徘徊したデータ
https://1drv.ms/u/s!AmXmBbuizQkXgrlPo98iECzyoSgy8w?e=nr7QM0
上記から SQLite のデータがダウンロードできます。東武東上線で池袋まで行って、東武デパートで食事をして、帰ってくるまでの2時間のデータになります。
収集データの解説
テーブル構造は、以下の通り
CREATE TABLE RPI (
Id INTEGER NOT NULL CONSTRAINT PK_RPI PRIMARY KEY AUTOINCREMENT,
Key BLOB NULL,
Metadata BLOB NULL,
StartTime TEXT NOT NULL,
EndTime TEXT NOT NULL,
RssiMin INTEGER NOT NULL,
RssiMax INTEGER NOT NULL,
MAC INTEGER NOT NULL
)ビーコンの受信開始(StartTime)と受信終了(EndTime)で接触時間が計測できます。ただし、ビーコンの受信データだけだと、発信のほうが10分で切り替わるので10分以内しか判別できません。別途、陽性者のTEKをダウンロードしてきて、受信したRPIを照合させると10分以上の接触が確認できます。実際の ENs が「接触の可能性あり」で通知しているのはこの部分です。

電波強度(RssiMax)を見ると、どれだけ近接しているかがわかります。私自身 iPhone に COCOA を入れているので、ひとつだけはかなり近いデータになっています。それ以外は、電車やホームでのすれ違い、エスカレーターで並んでいたときと考えられます。データの収集は一瞬でも近づけばデータとして保持されるので、きちんと解析するときは、近接している時間(EndTime – StartTime)と、電波強度(RssiMax)を見るとよいでしょう。
実際に実験をしてみると、バスが通ったり、電車が通過したときでも同時接続数が40程度の爆上がりします。いわゆる一瞬のすれ違いでも計測されるということです。
COCOA が使う ENs の仕組みは完全に公開されているとは言えませんが、おおまかなところはコードで示されています。実際の照合のところは数式でしか示されていないのが残念なところですが、公式で言われている通り、電波強度と近接時間の両方をみて判断して1mと15分以上という値を割り出しています。
TEK データのダウンロード
COCOA を通して陽性登録された TEK のデータを probetek コマンドでダウンロードします。
dotnet run --all2/4時点で、50万件のTEKがあります。TEK は日単位で変わるので、おおむね7で割ると登録数になります。おおむね7万件というところでしょう。このデータは全国なので、2,3割の陽性者が登録している計算になります。実際のところは、厚生労働省のページ https://www.mhlw.go.jp/stf/seisakunitsuite/bunya/cocoa_00138.html で確認ができます。

この TEK データを SQL Server にアップロードします。
dotnet run --update-tekTEK から、その日の 144個(10分単位)の RPI を生成して EXRPI テーブルに挿入しています。
と思ったのですが、データ量が 50万 x 144 で 7200万件になるので尋常ではありません。そのまま動かすとPCのメモリのデータベースもいっぱいになってしまうので、照合の部分は考え直しましょう。
実際の Google/Apple の ENs では C++ でバイナリ照合しているのでメモリは枯渇しません。どうやら照合用のツールを別途作る必要がありそうです。
