OpenCV のテンプレートマッチを使って駒を検出 | Moonmile Solutions Blog
http://www.moonmile.net/blog/archives/2468
の続きです。
先のテンプレートマッチングが遅かった原因は、2 つあって、
- cv::matchTemplate を呼び出して、MaxMin を検索した後に、再び cv::matchTemplate を呼び出しているのが無駄。
- 元画像をそのままマッチング対象にしているので、低解像度にすれば早くなる?
ってところです。
前者の cv::matchTemplate の多重呼び出しは完全にコーディングミスですね。50 個の max を取るのに、いちいち cv::matchTemplate を呼び出す必要はありません。一回だけ呼び出して、その結果の画像を使って 50 個の max を cv::minMaxLoc で取得すれば良いのです、これで結構速くなります。
後者の低解像度化のほうは、以前から考えていて、高解像度のままマッチングをして検出しようとすると、細かい部分に敏感になってしまうという現象が発生します。細かいところというのは、取得画像のノイズであったり、微妙な手振れであったり、教師画像(テンプレートマッチで見つける画像)の違いによってスコアが大きく異なる、という現象です。このために、平滑化が行われることが多いのですが、わざわざ高解像度であるものを平滑化してしてしまうのはどうかなぁ、と思っていたので、実験しています。平滑化を行うのではなく、単純に低解像化します。低解像度にするときは、となりのドットの平均値を取る…ようなことはせず、単純に間引きます。間引いてしまうと、実はノイズに敏感になってしまうという不利が働く可能性があるのですが、そのあたりが高速化を優先して…というか、実際に目から入る情報をそのまま使う、という方針でいきます。
で、ざっと書いたコードがこんな感じ。
#include "stdafx.h"
#include <iostream>
#include "opencv/cv.h"
#include "opencv/highgui.h"
using namespace std;
/// 低解像度クラス
class RowReso
{
private:
cv::Mat *_org_img;
cv::Mat *_reso_img;
cv::Mat *_reso_org;
int _reso ;
int _reso_width ;
int _reso_height ;
public:
RowReso()
{
_org_img = NULL;
_reso_img = NULL;
_reso_org = NULL;
}
~RowReso()
{
if ( _reso_img != NULL ) delete _reso_img;
if ( _reso_org != NULL ) delete _reso_org;
}
// 初期化
void Initialize( cv::Mat& img, int reso )
{
int width = img.cols / reso;
int height = img.rows / reso;
_org_img = &img ;
_reso_img = new cv::Mat(height, width, CV_MAKETYPE(img.depth(),img.channels()));
_reso = reso ;
_reso_width = width ;
_reso_height = height ;
}
// 低解像度を作成
cv::Mat& Do()
{
for ( int y=0; y<_reso_height; ++y ) {
for ( int x=0; x<_reso_width; ++x ) {
int x1 = (_reso+1)/2 + _reso*x;
int y1 = (_reso+1)/2 + _reso*y;
cv::Vec3b &v = _org_img->at<cv::Vec3b>(y1,x1);
// cout << x << "," << y << endl;
_reso_img->at<cv::Vec3b>(y,x) = v;
}
}
return *_reso_img;
}
// 確認用に元の画像の大きさに戻す
cv::Mat& GetOriginalSize()
{
if ( _reso_org == NULL ) {
_reso_org = new cv::Mat(
_org_img->rows, _org_img->cols,
CV_MAKETYPE(_org_img->depth(),_org_img->channels()));
}
for ( int y=0; y<_reso_height; ++y ) {
for ( int x=0; x<_reso_width; ++x ) {
cv::Vec3b &v = _reso_img->at<cv::Vec3b>(y,x);
for ( int y1=0; y1<_reso; ++y1 ) {
for ( int x1=0; x1<_reso; ++x1 ) {
_reso_org->at<cv::Vec3b>(y*_reso+y1,x*_reso+x1) = v ;
}
}
}
}
return *_reso_org;
}
};
int main2(int argc, char **argv );
int main(int argc, char **argv )
{
if ( argc == 2 ) {
main2( argc, argv );
return 0;
}
cv::VideoCapture cap;
cap.open(0);
cap.set( CV_CAP_PROP_FRAME_WIDTH, 640 );
cap.set( CV_CAP_PROP_FRAME_HEIGHT, 480 );
cv::namedWindow("camera", CV_WINDOW_AUTOSIZE|CV_WINDOW_FREERATIO);
cv::namedWindow("reso", CV_WINDOW_AUTOSIZE|CV_WINDOW_FREERATIO);
cv::namedWindow("reso org", CV_WINDOW_AUTOSIZE|CV_WINDOW_FREERATIO);
cv::namedWindow("reso koma", CV_WINDOW_AUTOSIZE|CV_WINDOW_FREERATIO);
char fname[256];
cv::Mat img_koma[7];
for ( int i=0; i<7; i++ ) {
sprintf( fname, "D:\\work\\OpenCV\\src\\mini\\koma%02d.png", i+1 );
img_koma[i] = cv::imread(fname);
}
// 初回だけ読み込む
cv::Mat img;
cap >> img ;
int reso = 3 ;
RowReso Reso, ResoKoma[7];
Reso.Initialize( img, reso );
cv::Mat img_reso_komas[7];
for ( int i=0; i<7; i++ ) {
ResoKoma[i].Initialize( img_koma[i], reso );
// 低解像度の教師画像
img_reso_komas[i] = ResoKoma[i].Do();
}
// 枠線の色
cv::Scalar cols[7];
cols[0] = cv::Scalar(0,0,255);
cols[1] = cv::Scalar(0,255,255);
cols[2] = cv::Scalar(255,0,255);
cols[3] = cv::Scalar(255,0,0);
cols[4] = cv::Scalar(0,255,0);
cols[5] = cv::Scalar(255,255,0);
cols[6] = cv::Scalar(255,255,255);
while ( 1 ) {
cap >> img ;
cv::Mat &img_reso = Reso.Do();
cv::Mat &img_reso_org = Reso.GetOriginalSize();
cv::Mat img_search, img_result ;
img_reso.copyTo( img_search );
for ( int j=0; j<7; j++ ) {
cv::Mat &img_reso_koma = img_reso_komas[j];
// テンプレートマッチング
cv::matchTemplate(img_search, img_reso_koma, img_result, CV_TM_CCOEFF_NORMED);
// 50 個検出する
for ( int i=0; i<50; i++ ) {
// 最大のスコアの場所を探す
cv::Point max_pt;
double maxVal;
cv::minMaxLoc(img_result, NULL, &maxVal, NULL, &max_pt);
// 一定スコア以下の場合は処理終了
if ( maxVal < 0.5 ) break;
cv::Rect roi_rect(0, 0, img_reso_koma.cols, img_reso_koma.rows);
roi_rect.x = max_pt.x ;
roi_rect.y = max_pt.y ;
cv::Rect roi_rect_org( roi_rect.x * reso , roi_rect.y * reso ,
img_reso_koma.cols*reso, img_reso_koma.rows*reso );
// std::cout << i << ":(" << max_pt.x << ", " << max_pt.y << "), score=" << maxVal << std::endl;
// 探索結果の場所に矩形を描画
cv::rectangle(img_reso_org, roi_rect_org, cols[i], 3);
// cv::rectangle(img_search, roi_rect, cv::Scalar(0,0,0), CV_FILLED);
// 検出済みは 0.0 で塗りつぶし
for ( int y=0; y<img_reso_koma.rows; y++ ) {
for ( int x=0; x<img_reso_koma.cols; x++ ) {
int xx = max_pt.x + x - img_reso_koma.cols/2;
int yy = max_pt.y + y - img_reso_koma.rows/2;
if ( 0 <= xx && xx < img_result.cols-1 ) {
if ( 0 <= yy && yy < img_result.rows-1 ) {
img_result.at<int>(yy,xx) = 0;
}
}
}
}
// koma.push_back( roi_rect );
}
}
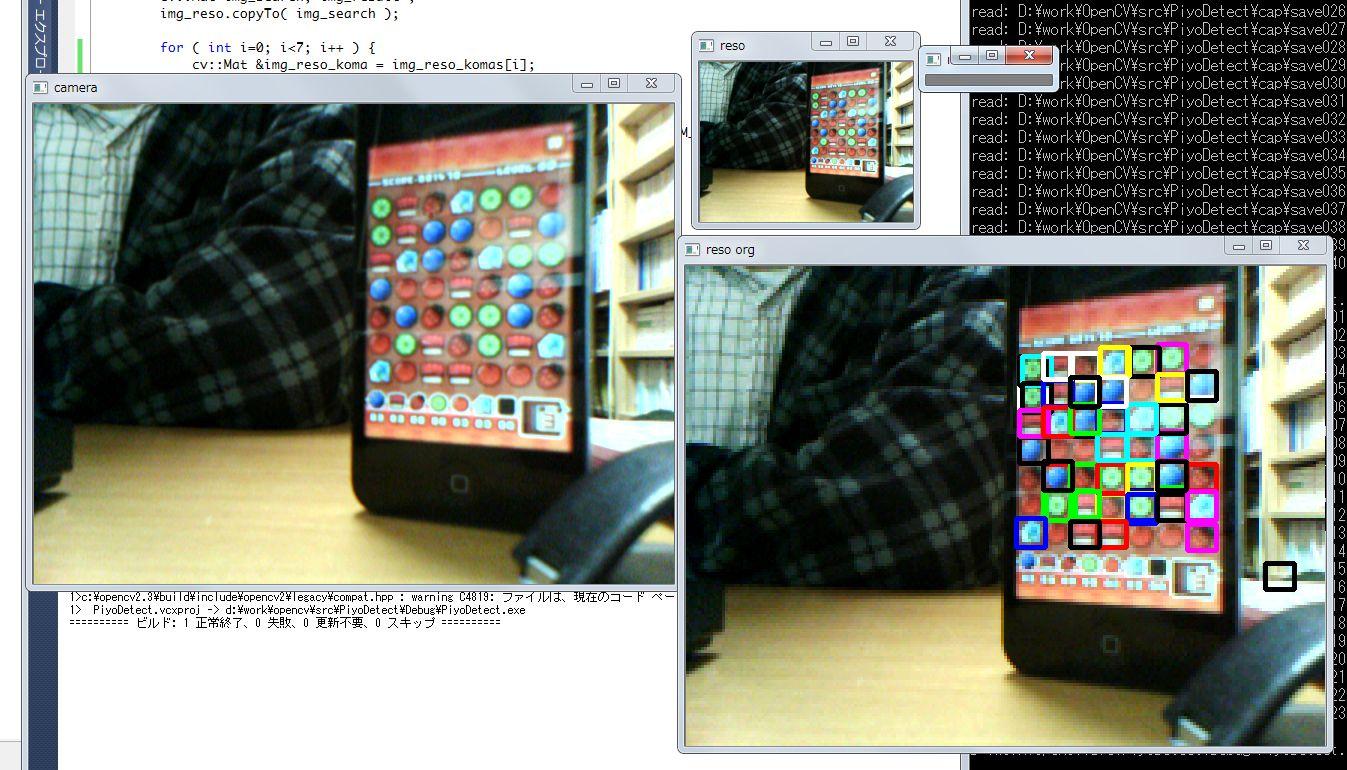
cv::imshow("camera", img );
cv::imshow("reso", img_reso);
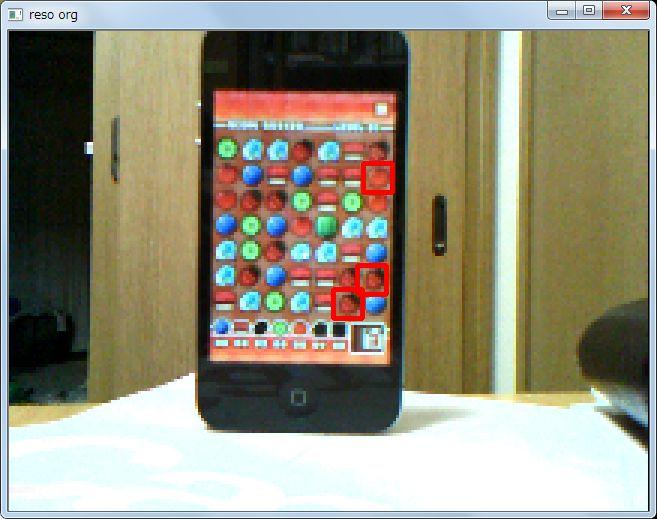
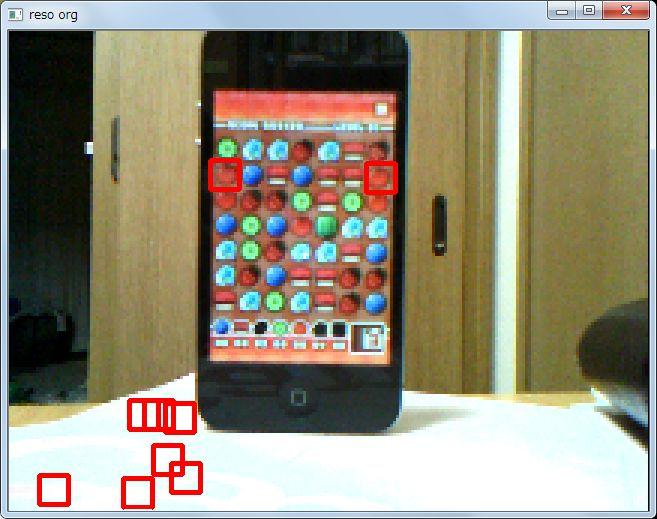
cv::imshow("reso org", img_reso_org);
char ch = cv::waitKey(30);
if ( ch == 27 ) break;
}
return 0;
}
RowReso クラスは、単純に cv:Mat の中身を間引きしているだけです。
低解像化する率は「3」という奇数を取ります。中央の点をサンプリングしたかったためなのですが、本当は左上の点でもよいのかもしれません。これは後で実験します。
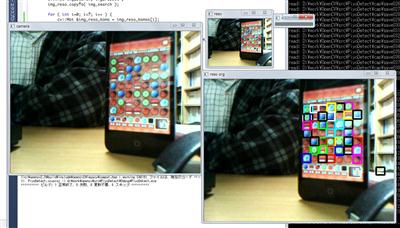
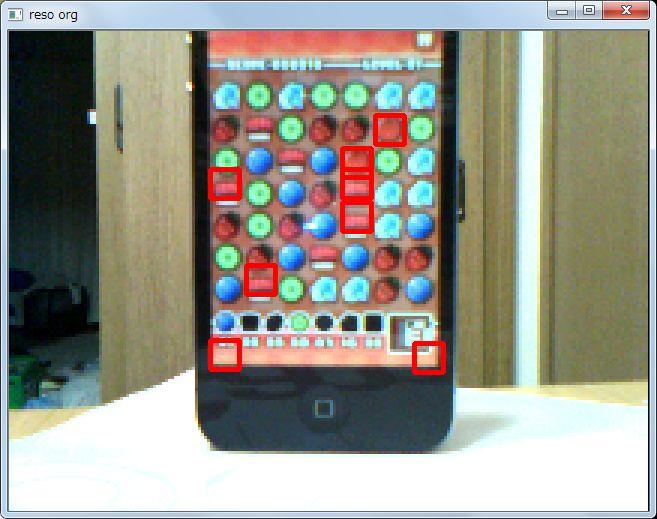
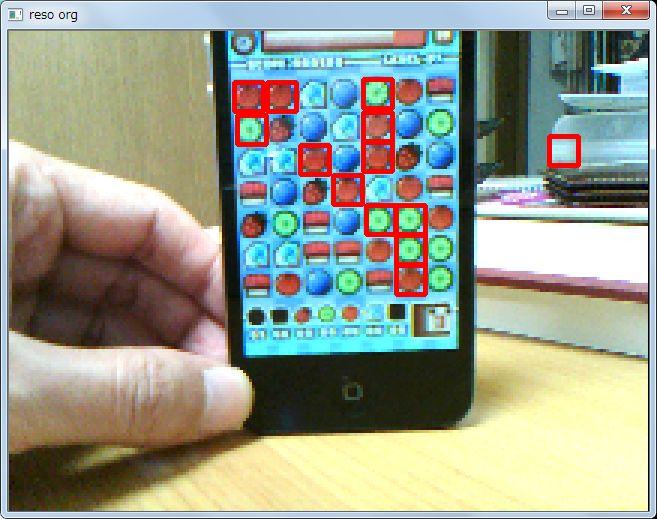
多少、カクカクとしますが、ほどよくマッチングができています。
7 つの駒を、低解像度の画素数(640×480 の 1/3 なので、210×160 = 34000)で検索するので、24 万回のマッチングの計算をしています。低解像度にしたので、9 倍ほど早くなっているはずです。教師画像も 1/3 サイズになっているので、マッチング自体の速度アップも寄与していると思います。
で、検出の精度はどうかというと、良いような悪いような、という感じですね。右のほうに黒の枠がでているので、ここで誤検出しています。また、ところどこ抜けがでているので、検出できない駒もあります。これは 0.5 の足切りになってしまった箇所です。
加えて、実際に実行してみると分かるのですが、検出の色がちかちかと変わります。検出している駒のマッチングで、複数マッチしているものがあるわけです。
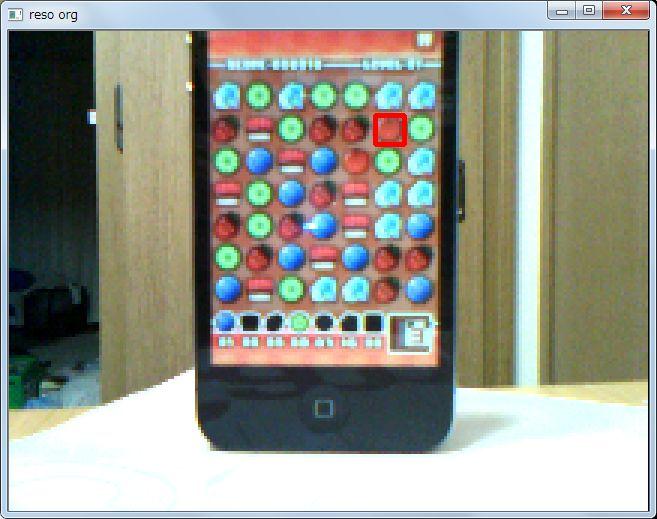
このあたりの誤検出は想定のうちで、低解像度によっておおまかな駒の位置がわかったら、高解像度のほうで駒の検出をやり直します。このあたり、人間の目でも、アクションパズルをする場合、大まかに色か形で目で追って、その後でじっと凝視して本当にそれが認識した駒とあっているかどうか?を確認するという認識手順になる…と思うのでそれに準じます。
あと、テンプレートマッチの回数自体は、初回のみ(あるいはパズルが一旦消えた、あるいは iPhone が大きく動いた)ときに必要で、続くフレームのほうでは、先に認識した駒の位置から類推をさせることで、マッチングの範囲を極端に減らすことが可能です。低解像の駒は 10×10 程度なので、これに 2 倍の幅を持たせて 20×20 x 盤面7×7 = 2万回 のマッチングで良くなるはずです。
ってな訳で後日。