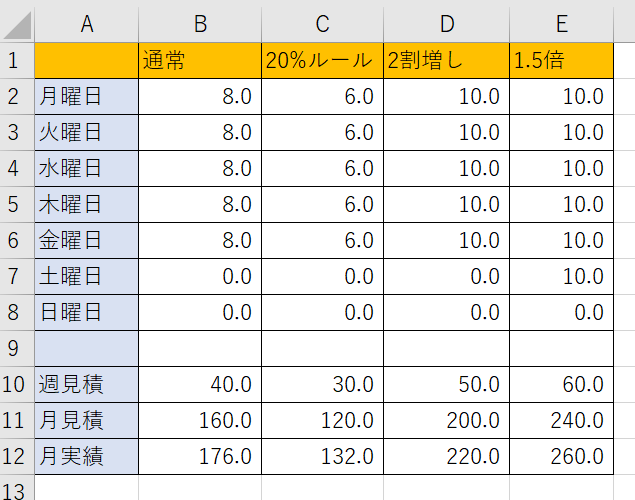
絵文字1文字縛りにするのは、構文解析が楽というのもあるけど、制御文なので使われる「if」や「for」などの単語は、ひとつの単語がひとつの意味を成している(この場合は何らかの制御をするという意味で)と考えられる。例外としては、for … in のように2つの単語でひとつの制御を示すこともあるが「繰り返し処理」という制御の拡張(inが補助的なもの)と考えることもできる。
.NET 6 で利用していた EF Core 6.0 を .NET 7 の EF Core 7.0 にアップデートしたときに「信頼されていない機関によって証明書チェーンが発行されました」のエラーが出てきて SQL Server に接続できないことがあります。これは、開発用に立てたローカルの SQL Server に接続するときに、サーバーの証明書が正しくない(自己証明書を含む)ときに発生するようです。正しくは SQL Server が動いているサーバー証明書をローカルPCにインストールするか、正しいサーバー証明書をいれればいいのですが、本運用ならともかくとして、開発用サーバーに正式な証明書をいれることはありません。
EF Core 6.0 ではサーバー証明書を無視するらしいのですが、EF Core 7.0 できっちりとチェックするようになったための問題のようです。
var SQL = $@"
select
予約.ID,
顧客.会社名,
予約.日付,
部屋.名称 as 会議室,
予約状況.開始時刻 as 開始,
予約状況.終了時刻 as 終了,
顧客sub.部署名 as 部署名,
顧客sub.担当者A as 担当者,
顧客sub.TEL as TEL,
顧客sub.FAX as FAX,
予約.予約 as 状態,
予約.契約日 as 契約日,
予約.確認票最終処理日 as 確認日,
請求.日付 as 請求日,
X.利用料,
isnull(入金.入金額,0) as 入金額,
予約.備考B as 注意事項,
予約.案内名称 as 案内板名称
from
(
select
予約.ID as ID,
cast(ISNULL(sum(予約sub.単価*予約sub.数量),0) as money) as 利用料
from 予約
left join 予約sub on 予約sub.予約ID = 予約.id
where 予約.顧客id = {顧客ID}
group by
予約.ID
) X
inner join 予約 on 予約.id = X.ID
inner join 顧客 on 顧客.ID = 予約.顧客ID
inner join 顧客sub on 顧客sub.ID = 予約.顧客SUBID
left join 請求 on 請求.id = 予約.請NO
left join 入金 on 入金.請求ID = 請求.ID
inner join 部屋 on 部屋.id = 予約.会議室
inner join 予約状況 on 予約状況.予約ID = 予約.ID
order by 予約.日付 desc
";
this.Items = App.ent.Database.SqlQuery<結果>(SQL).ToList();
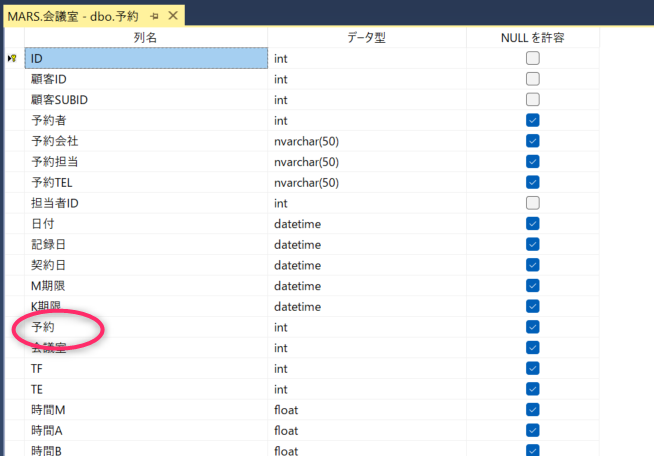
なので、.NET Framework の EF では、以下のように「予約1」という名前が勝手に振られます。
public partial class 予約
{
public int ID { get; set; }
public int 顧客ID { get; set; }
public int 顧客SUBID { get; set; }
public Nullable<int> 予約者 { get; set; }
public string 予約会社 { get; set; }
public string 予約担当 { get; set; }
public string 予約TEL { get; set; }
public int 担当者ID { get; set; }
public Nullable<System.DateTime> 日付 { get; set; }
public Nullable<System.DateTime> 記録日 { get; set; }
public Nullable<System.DateTime> 契約日 { get; set; }
public Nullable<System.DateTime> M期限 { get; set; }
public Nullable<System.DateTime> K期限 { get; set; }
public Nullable<int> 予約1 { get; set; }
public Nullable<int> 会議室 { get; set; }
public Nullable<int> TF { get; set; }
public Nullable<int> TE { get; set; }
public partial class 単発アラーム
{
public int ID { get; set; }
public Nullable<System.DateTime> 日時 { get; set; }
public string 対象種別 { get; set; }
public string 対象名 { get; set; }
public string 表示内容 { get; set; }
public System.DateTime CreateAt { get; set; }
public System.DateTime UpdateAt { get; set; }
}
このような自動生成された Entity クラスとは別に、patial で拡張しておきます。
/// <summary>
/// 日時を年月日と時分に分ける拡張
/// </summary>
public partial class 単発アラーム
{
public Nullable<System.DateTime> 日時_年月日
{
get { return this.日時; }
set
{
if ( this.日時.HasValue )
{
DateTime dt = new DateTime(
value.Value.Year,
value.Value.Month,
value.Value.Day,
日時.Value.Hour,
日時.Value.Minute,
0);
this.日時 = dt;
}
}
}
public Nullable<System.DateTime> 日時_時分
{
get { return this.日時; }
set
{
if (this.日時.HasValue)
{
DateTime dt = new DateTime(
日時.Value.Year,
日時.Value.Month,
日時.Value.Day,
value.Value.Hour,
value.Value.Minute,
0);
this.日時 = dt;
}
}
}
}
ここで .NET6 への移植時に問題が発生します。
.NET Framework の EF では、テーブル構造が *.edmx ファイルに分離されているので、拡張した日時_年月日プロパティや日時_時分プロパティは更新時に無視されるのですが、.NET6 の EFCoreでは更新対象がEntityクラスの全プロパティとなるため、この拡張したプロパティを「無視」させるようにしなければなりません。
CREATE TABLE RPI (
Id INTEGER NOT NULL CONSTRAINT PK_RPI PRIMARY KEY AUTOINCREMENT,
Key BLOB NULL,
Metadata BLOB NULL,
StartTime TEXT NOT NULL,
EndTime TEXT NOT NULL,
RssiMin INTEGER NOT NULL,
RssiMax INTEGER NOT NULL,
MAC INTEGER NOT NULL
)
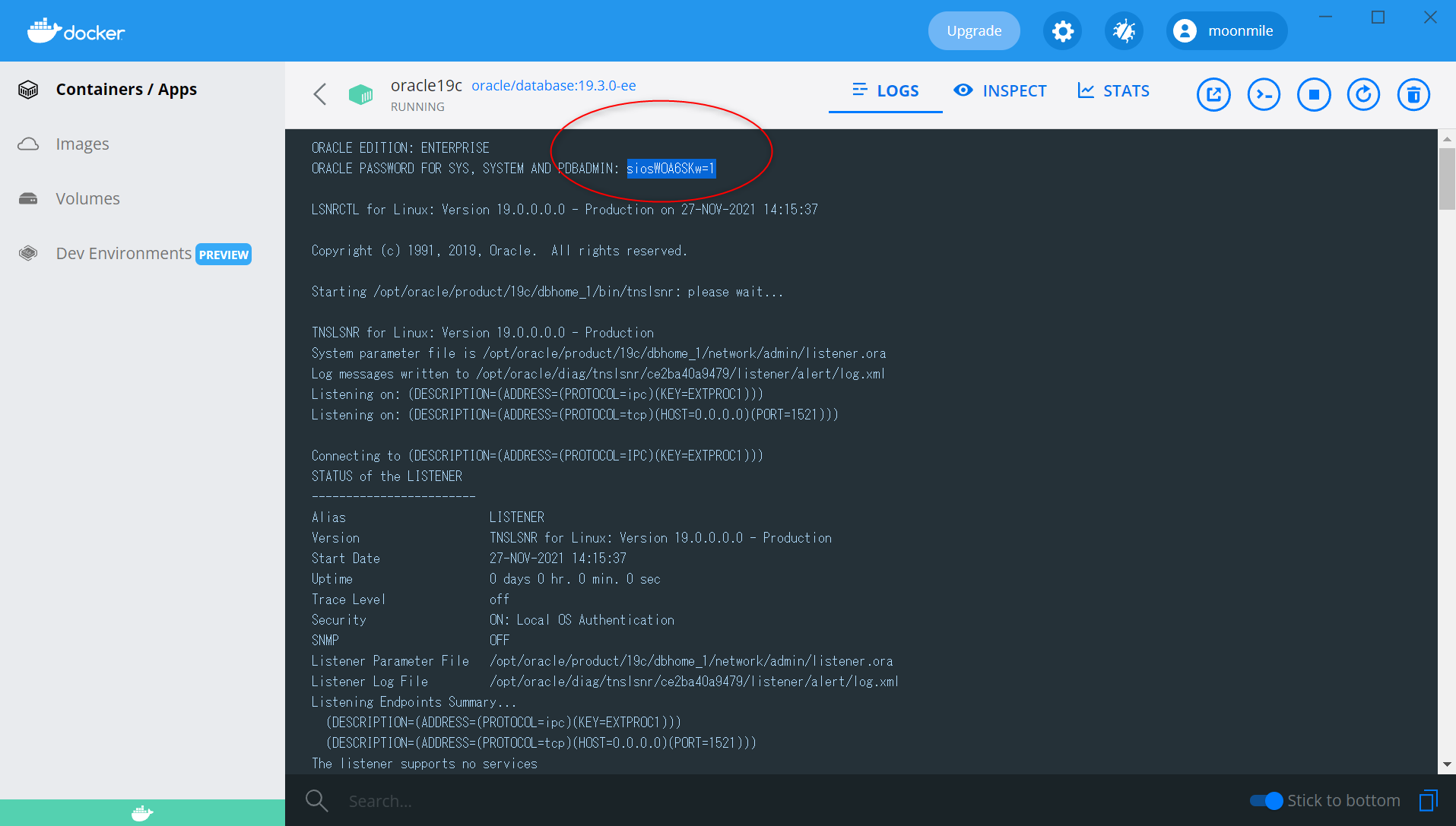
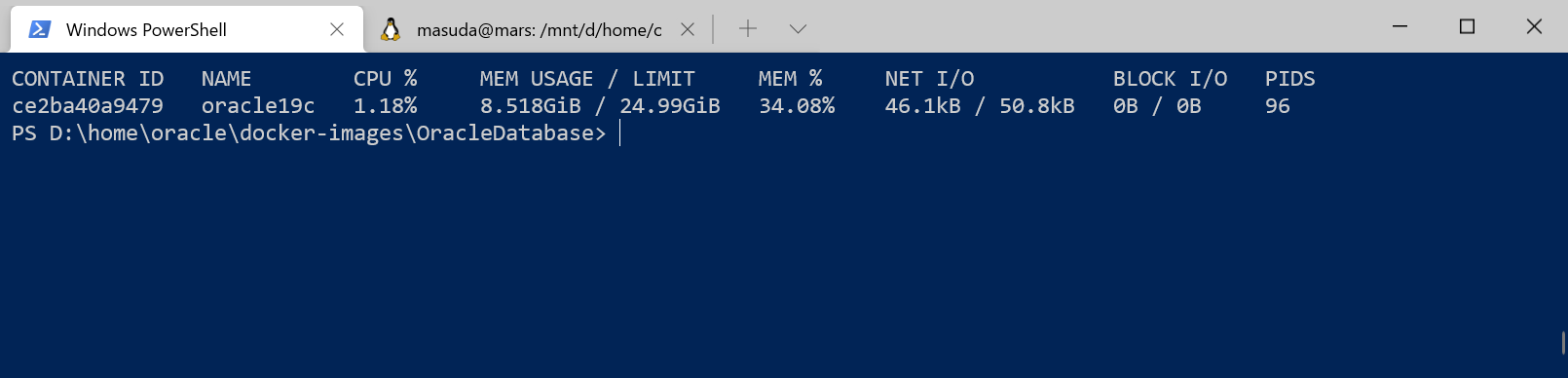
sqlplus sys/siosWOA6SKw=1@localhost:1521/ORCLCDB as sysdba
ログインユーザーと表領域の作成
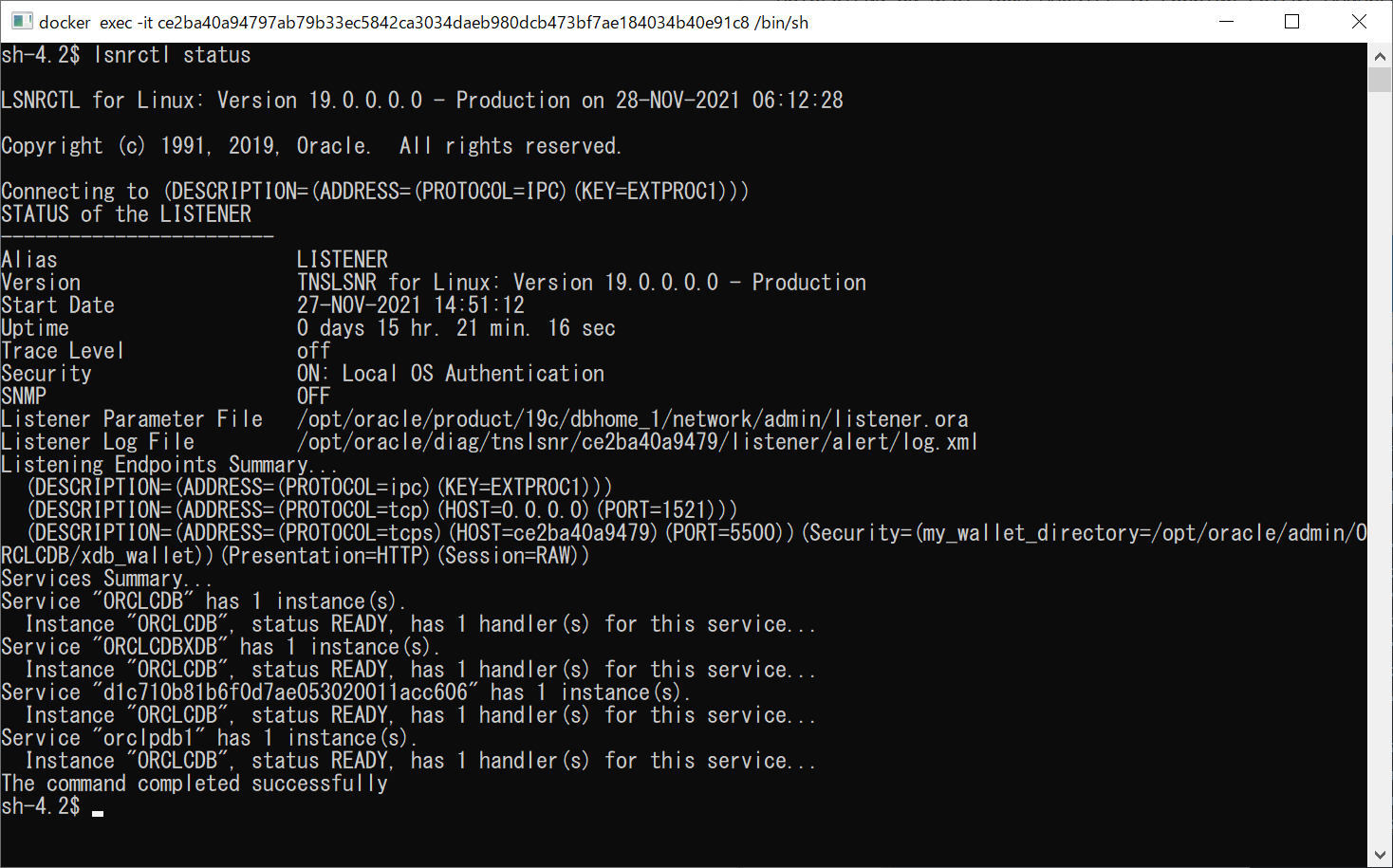
ログインユーザーを作ってためしておきます。
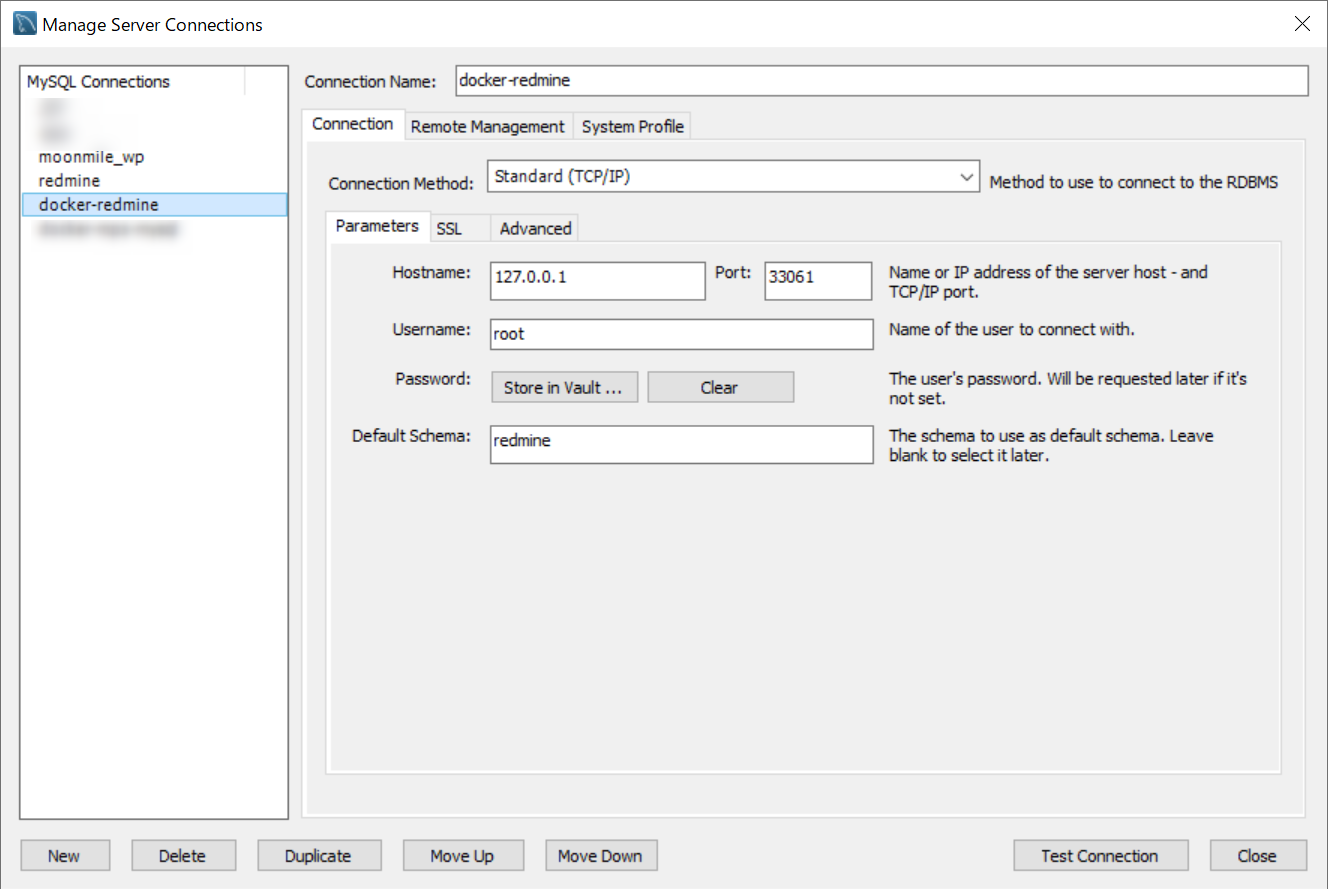
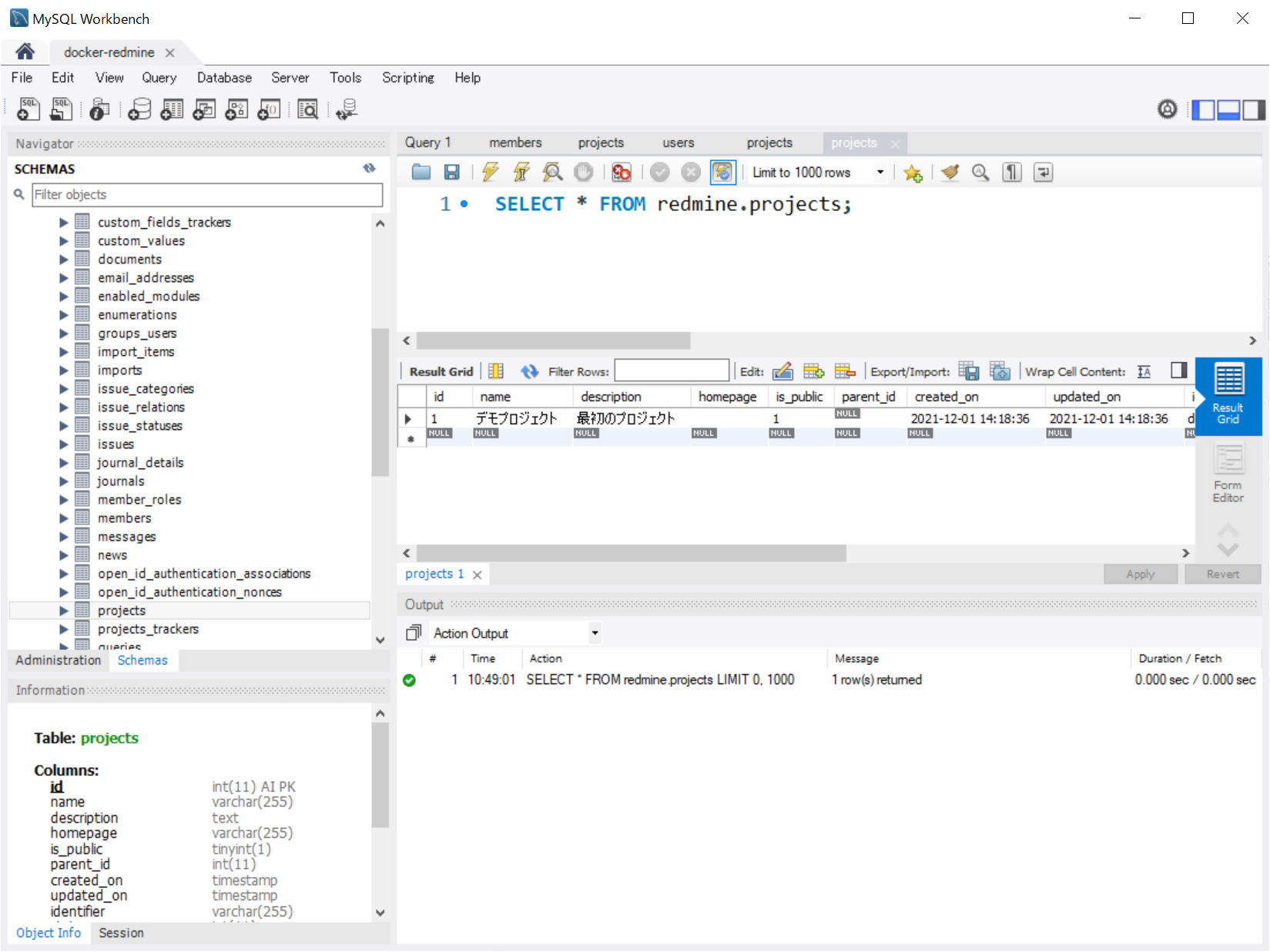
あとで、.NET から接続確認したいので redmine ユーザーを作ります。
alter session set container=ORCLPDB1;
create tablespace "redminets" datafile '/opt/oracle/oradata/ORCLCDB/redminets.dbf' size 500M
AUTOEXTEND ON NEXT 100M MAXSIZE 1G LOGGING EXTENT MANAGEMENT
LOCAL SEGMENT SPACE MANAGEMENT AUTO;
create user redmine
identified by redmine
default tablespace "redminets"
account unlock ;
GRANT connect TO "REDMINE";
GRANT CREATE SESSION TO "REDMINE";
GRANT "RESOURCE" TO "REDMINE";
ALTER USER "REDMINE" DEFAULT ROLE ALL;
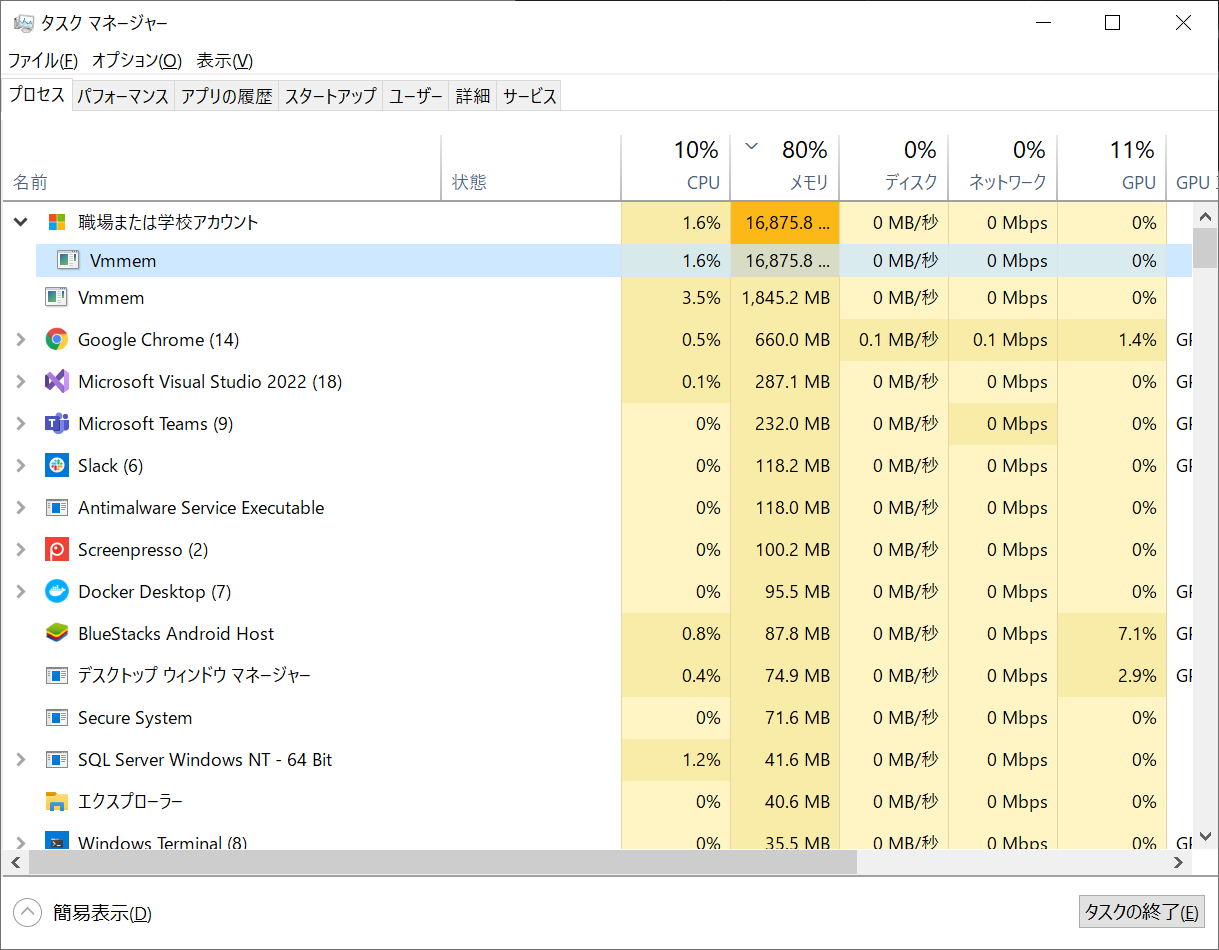
こんなに使われると、ホスト側の Windows が死んでしまうので、.wslconfig で制限をします。この加減がよくわからないのですが、まあ、Hyper-V の仮想環境で Windows Server + Oracle を作ったときと同じくらい喰うのはどうなの?って感じです。環境的には、可搬性があるからいいけど。