内容的には、OpenAI API を Azure を通して使うパターンです。OpenAI API の場合、Python プログラムが多いのですが、この本では全面的に C# で書いています(ちょっとだけ、Python と Node.js があります)。Python の場合、主にコマンドラインと Web アプリが主流となるのですが、C# の場合はデスクトップアプリやスマホアプリ、Azure Fuctions などと組み合わせが可能です。自前のツールから JSON 形式で OpenAI を呼び出してもよいのですが、本書では Azure.AI.OpenAI パッケージを使って通信をしています。
実は、執筆中に Semantic Kernel が発表されてどうしたものかと思っていたのですが、Azure 上のプレイグラウンドである Azure OpenAI Studio のサンプルコードが Azure.AI.OpenAI パッケージを中心として書かれていることと、Azure の各種の機能と組み合わせることも本書の目的のひとつであったので、Azure.AI.OpenAI パッケージを使っています。Azure.AI.OpenAI パッケージ自体がβ版なので、先行きはなんともいえませんが。あと、Azure AI Studio という形で他の AI が使える仕組みもあるのですが、これも OpenAI API に限るために Azure OpenAI Studio のほうを基準に解説しています。最近 OpenAI 以外の生成AI が発表されつつあるので、1年後ぐらいには状況が変わっているかもしれません。
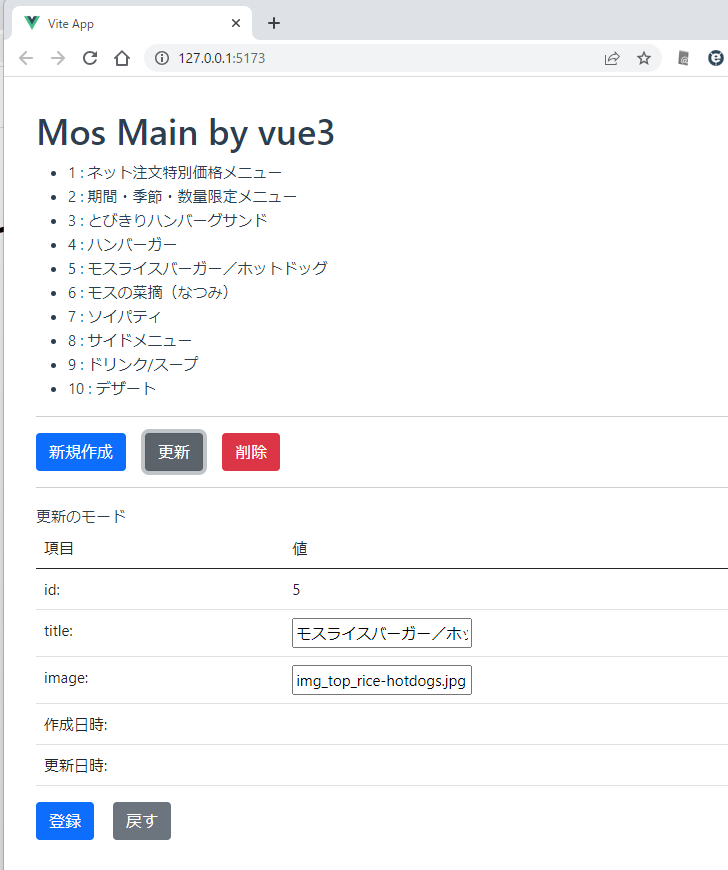
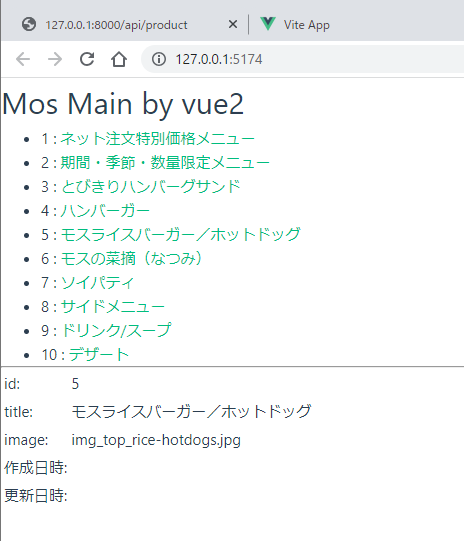
Vue2 の書き方で items, cur のところが、items.value, cur.value を使うところが一番分かりづらいと思う。リアクティブという仕組みを使って画面に値変更を通知するのだが、実は Vue2 では items, cur が仮想 DOM を使って通知されていたものが、Vue3 になってリアクティブという形でむき出しになってしまった形のため、こうなっている。
これは C++ で例外処理が入った頃から思っていたことなのだけど、例外の通知は、誰のためにあるのだろうか?「Good Code ~」や当時の上司には「例外を隠蔽してしまうと、コードのバグが隠蔽されてしまう」ので、例外を隠さないに呼び出し先の関数では例外を呼び出し元に通知するという方針をとることが多い。
要件を満たすかどうかのシステム試験の場合、ウォーターフォール開発の場合は、この時点で不具合が発生してもなんともならないことが多い。そうならないように、適宜スパイラル開発か、アジャイル開発か、マイルストーンを使ったウォーターフォール開発に直す。ちなみに、富士通 Japan の ID 重複の件は、この部分に属する。要件を満たさない設計を作ってしまったか、要件そのものに「時刻を ID とする」と書かれていたか。肥大化する要件定義書を抱えている場合は、後者となることが多い。特に F の場合は。
自動化する単体試験においては、XP のプラクティスのようにテスト駆動をしてもよいし、コーディングをしながらテストをしてもよい。昔のように、コードをビルドしてリリースしなければ画面が動作しないということはないので、画面を動かしながら Web API の動作チェックも可能である。かつ、そのように設計とコーディングの順序を決めておけば、不要な不具合票の取り回しをしなくてもよい。労力が減る。Vue.js とかで画面を作っている場合は、常にエラーが出ない状態でコードを組む方がよい。かつ、その時々で画面の動作を画面設計書などと照らし合わせながらチェックをすれば、過大なテスト項目をこなさなくても済む。