生成AIを使ってコード生成をし始めて半年ぐらい経つわけですが、「いろいろなコード生成が自動的にできるよ!」という話よりも、実際に目の前のコードをどうやって生成していくのか?うまく動くようにAIが生成したコードをどうやって人(=自分)が修正していくのか?がプログラマには当面の課題になります。
まあ、どうやってChatGPTあるいはCopilotを使って、コード書きを促進させるか?という実例ですね。WEB アプリケーションのように巷に情報が溢れているならばまだしも、組み込みのような情報が閉鎖的(でもないのだけど)で少ない場合にはどうするのか?という例でもあります。実際のところ、ブロック崩しとか顔認識AIのような既にコードがある場合にはそれをコピペすれば言い訳で、ほどよく WEB サイトに散らばっているならば大丈夫なんですが、完全に未知なコード(少なくとも自分にとっては「未知」の状態)の場合には、ちょっと困るわけです。
C2340R5でBLEのデバイス名を変更したい
未知の人には完全に未知だと思います。まずは、「C2340R5」ってのが何なのかを調べないといけません。BLEを知っていればいいのだけど、デバイス名は何なのか、ぐらいは知っておいて欲しいものですが、まあ、そこからスタートしましょう。
ちなみに、CC2340R5 ってのは Bluetooth が入っている組み込み用のボードですね。ESP32 が入っている M5Stack 系で Bluetooth/BLE を扱えば結構情報が多いのですが、Texas Insturuments の CC23xx 系のボードだと情報が少ないのです。まあ、フォーラムがあるだけマシなのと、マニュアルが揃っているのでなんとかなりそうではあります。
https://www.ti.com/product/CC2340R5

実は SimpleLink というライブラリが TI から提供されていて、これに結構書いてあります。書いてはあるのですが、じゃあ「BLEのデバイス名を変更する」方法は書いていないのが難点ではあります(ほんとうのところ、書いていないのではなくて、デバイス名を変更する方法がない、ということなのですが)。
SWCU193 User guide | TI.com https://www.ti.com/document-viewer/lit/html/swcu193
初手は素直に聞いてみる
AIに質問をするときに「目的」と「手段」をうまく切り分けないと変な回答が出てくることが多いのですが、ひとまず初手としては素直に聞いてみるのがいちばんです。ぴったりとした答えがでてくればそれでよいし、まあ違ったとしたらそれを踏み台にして探索を続ければいいのです。
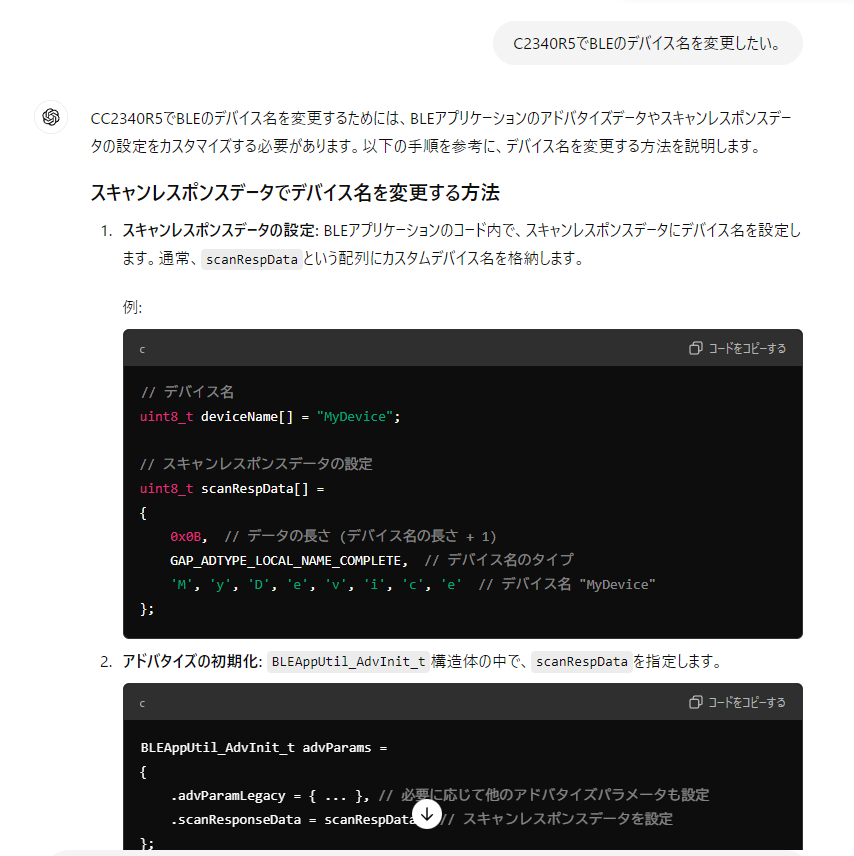
実はですね、この模索を再現しようと思って、初手に「C2340R5でBLEのデバイス名を変更したい」を再び入力したら、正解が出てくるんですよ。実は、SimpleLink のライブラリには動的にデバイス名を変更する API がなくて、BLE のアドバタイズ部分を再起動するしかありません。しかも配信するデバイス名は上記のように直書きになっているので、自前でバイト単位で書き出さなければ(memcpy使うけど)いけないのです。
まあ、このコードを見て「デバイス名が変更できる」と分かるには、その模索がってこそなのですが。
以下は、以前出した間違ったChatGTPの回答を上げておきます。
ChatGPT にマニュアルの PDF を入れる
ChatGPT にはファイルアップロードして、その中を優先的に探索してくれる機能があるので、それを使います。

初期値は英語になっているようですが、次のプロンプトで「日本語で。」というと日本語が主になります。
いろいろと探索する
前回の場合は「simplelink でデバイス名を変更するには?」で質問しています。この手の質問は、初手は漠然とした「目的」を示したほうがよいです。最終的には実装するための「手段」を探すことになるのですが、いきなり手段を示してしまうと、それ以外の手段を探すのが難しくなりがちです(人間の頭的に)。なので、最初は何もわからない振りをして、ChatGPTに尋ね、少し手間がかかりますが掘り込み方式で進めます。
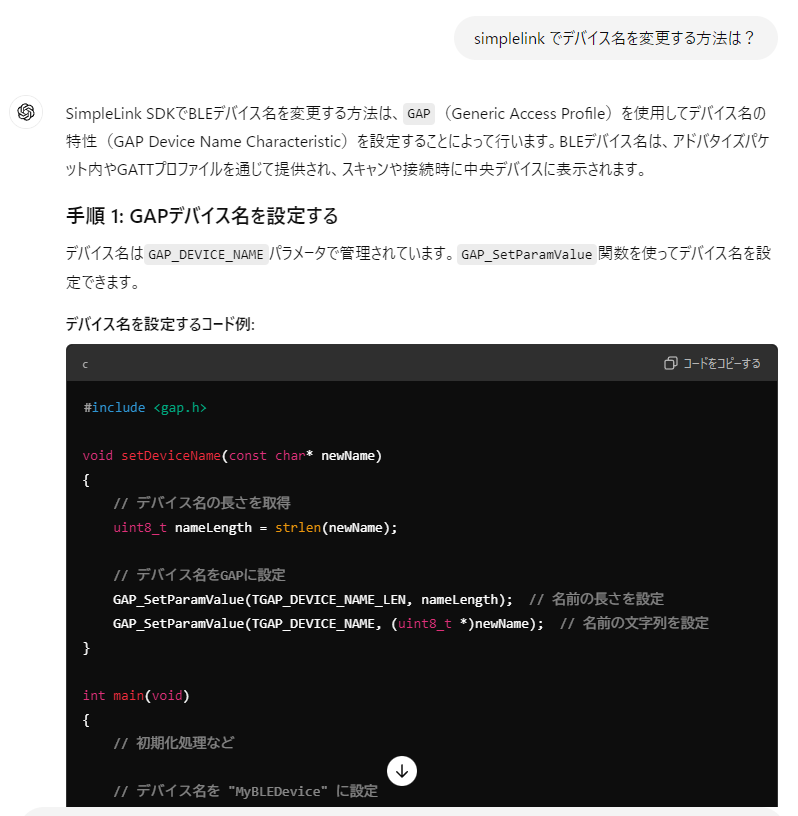
- TGAP_DEVICE_NAME という定義はどこにもない
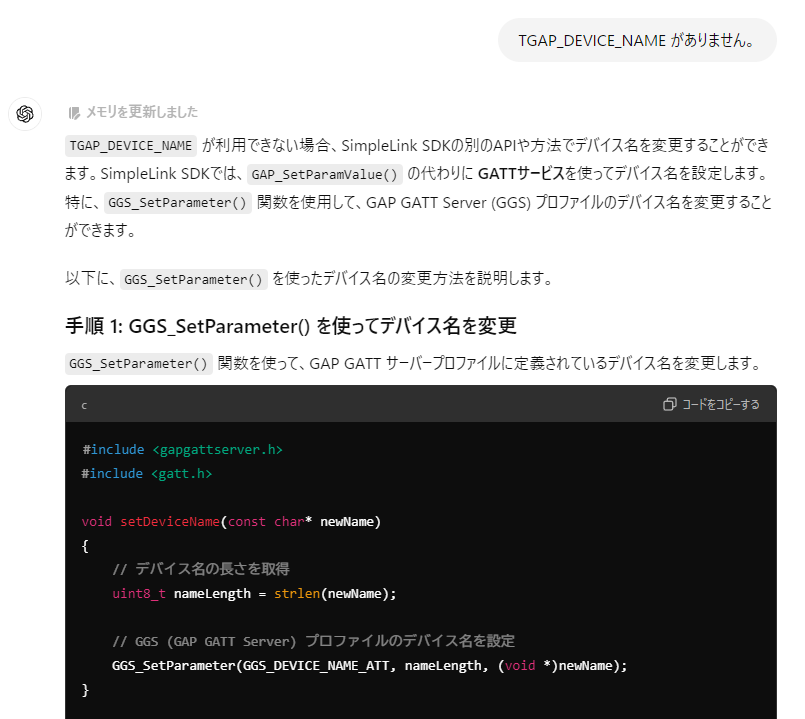
- GGS_DEVICE_NAME_ATT はあるが、デバイス名は変更されない。
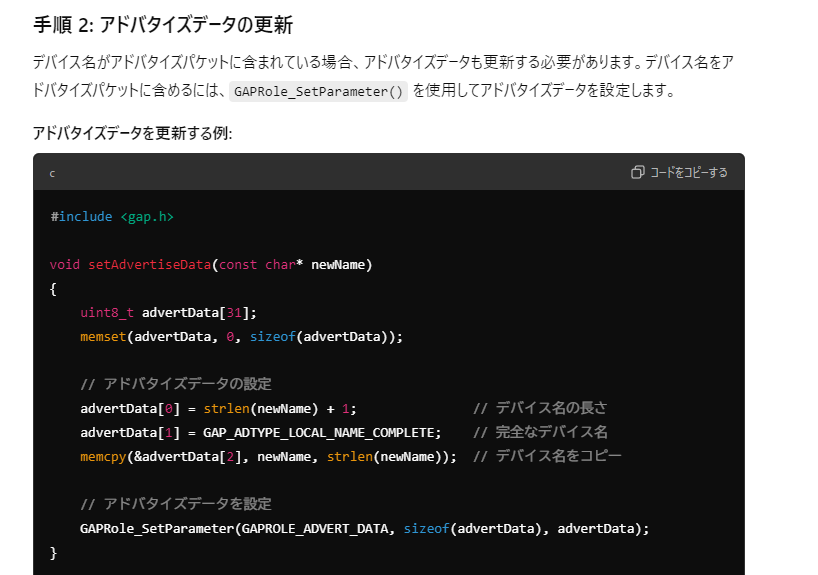
- GAPRole_SetParameter は存在しない。
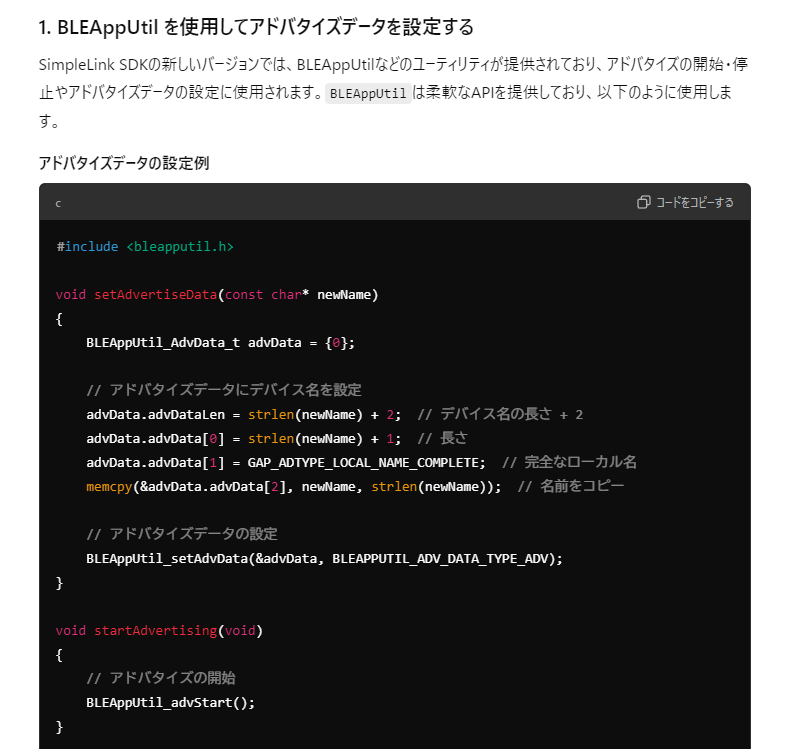
- BLEAppUtil_setAdvData は存在していない。
そんな訳で、なかなか正解に辿り着けません。実は、最初の質問ででてきたscanRespDataの書き換えが正解で、なんとか API 経由で書き換えようとしていたのですが、そんな API は存在しなくて、直接データを書き換えて BLEAppUtil_advStart で BLE のアドバタイズを再起動しないといけないのです。
仕方がないので、初期設定されているアドバタイズデータを書き換える
実は TI のプログラムは Code Composer Studio の *.syscfg というファイルを使っています。これが設定ファイルになっていて、各種設定をコード出力しているのです。Code Composer Studio でデバイス名(ble.deviceName)を書き換えると、うまく書き換わるわけで、そのあたりから更にコードを見ていきます。
最終的には BLEAppUtil_AdvInit_t 構造体があって、ここで初期設定されているのが肝です。コメントを見ると Sysconfig から変換されていることがわかるし、const struct になっているので、実にそれっぽいです。
//! Advertise param, needed for each advertise set, Generate by Sysconfig
const BLEAppUtil_AdvInit_t advSetInitParamsSet_1 =
{
/* Advertise data and length */
.advDataLen = sizeof(advData1),
.advData = advData1,
/* Scan respond data and length */
.scanRespDataLen = sizeof(scanResData1),
.scanRespData = scanResData1,
.advParam = &advParams1
};
まずは、const のままでは書き換えられないのでコードを修正します。
//! Advertise param, needed for each advertise set, Generate by Sysconfig
BLEAppUtil_AdvInit_t advSetInitParamsSet_1 =
{
/* Advertise data and length */
.advDataLen = sizeof(advData1),
.advData = advData1,
/* Scan respond data and length */
.scanRespDataLen = sizeof(scanResData1),
.scanRespData = scanResData1,
.advParam = &advParams1
};その後に、appMain 関数の先頭で advDataLen と advData を書き換えます。
// デバイス名の変更
static uint8_t deviceName[] = "BLE-TEST";
uint8_t deviceNameLen = strlen((const char*)deviceName);
static uint8_t scanResData[32];
uint8_t scanResDataLen = 0;
scanResData[0] = strlen((const char*)deviceName) + 1;
scanResData[1] = GAP_ADTYPE_LOCAL_NAME_COMPLETE;
memcpy(&scanResData[2], deviceName, deviceNameLen);
scanResData[2+deviceNameLen] = 0x02;
scanResData[3+deviceNameLen] = GAP_ADTYPE_POWER_LEVEL;
scanResData[4+deviceNameLen] = 0x00;
scanResDataLen = 5 + deviceNameLen;
memcpy( attDeviceName, deviceName, deviceNameLen+1 );
// memcpy( scanResData1 + 2, deviceName, deviceNameLen );
extern BLEAppUtil_AdvInit_t advSetInitParamsSet_1;
advSetInitParamsSet_1.scanRespData = scanResData;
advSetInitParamsSet_1.scanRespDataLen = scanResDataLen;
動的に変更したい場合は、BLEAppUtil_advStop でいったん止めてから BLEAppUtil_advStart すれば OK です。
ChatGPT の回答では、起動時の BLEAppUtil_advStart しか出て来ないのでなかなか正解に辿り着けないのですが、実は「動的に BLE のデバイス名を変えるにはどうすればいいですか?」と質問すると、かなりイイ線までいきます。
void updateDeviceName(const char* newDeviceName)
{
// 新しいデバイス名を格納(長さチェックを含む)
size_t nameLen = strlen(newDeviceName);
if (nameLen > MAX_DEVICE_NAME_LEN)
{
nameLen = MAX_DEVICE_NAME_LEN;
}
strncpy(deviceName, newDeviceName, nameLen);
// スキャンレスポンスデータを更新
uint8_t scanRespData[] =
{
nameLen + 1, // データ長
GAP_ADTYPE_LOCAL_NAME_COMPLETE, // デバイス名のタイプ
// デバイス名データ
};
// デバイス名をコピー(新しい名前で上書き)
memcpy(&scanRespData[2], deviceName, nameLen);
// BLEアドバタイズ設定を更新
BLEAppUtil_AdvInit_t advParams = {
.advParamLegacy = { ... }, // 他のパラメータを設定
.scanResponseData = scanRespData, // 更新されたスキャンレスポンスデータをセット
};
// 既存のアドバタイズを停止
BLEAppUtil_advStop();
// 新しいアドバタイズを開始
BLEAppUtil_advStart();
}
BLEAppUtil_AdvInit_t advParams が何処で使われているのか?(実際には BLEAppUtil_advStart の中身なんですが)、というのが不明なのでこのコードではうまくいかないのですが、先に説明した const struct BLEAppUtil_AdvInit_t までたどり着いています。
AI でコード出力をする場合、マニュアルにないコードは探せません。逆に言えば、マニュアルにあるコードならば結構な確率で探し出してくれます。数々の回答のコード(間違ってはいるけれども)もかつてのコードかもしれないし、うまく類推しているコードでしょう。
AI でコード出力と言うと「5分でなんとか」方式が多いので、あっという間に作れる雰囲気がありますが、実際のところはかなり違います。まあ、それでも何も分からないところがから、最初の下調べをしてくれてマニュアルからなんとなく導き出してくれるところは便利ですね。当然のことながら、コンパイルも含めて動作確認は人の手でやらないと無理なので、そのあたりで動作確認は必須なところです。