研究職に話題な DeepResearch ですが、簡易的なものであればさっくりと作れます。というテストです。
「さっくり」とは言いましたが、それなりに OpenAI API の作り方を知っていないとうまくいかないとは思うのですが、まあ、そのあたりも ChatGPT やら Copilot やらを使えばなんとかなります。
ざっと方針を決定する
この手の調査はよくやる話なので、人間がやっていることを AI に任せればokです。
- キーワードを入れて、関連する WEB サイトを探す
- WEB サイトの要約を表示する
の2段階があれば十分でしょう。実際、Google とかでキーワードを入れて一覧を作ってから、ぽちぽちと WEB サイトに飛んで、ページをコピペした後に要約するのはよくやる作業です。実に面倒くさいのですが、AI ならなんとかやってくれます。きっと。
ChatGPT に尋ねる
いきなりコード生成するのもよいのですが、ひとまず概要を伝えてみましょう。第一段階のキーワードにマッチするようなWebサイトを探して貰うコードを作ります。
テーマを指定すると、関連する WEB サイトの一覧を取得するコンソールツールを作って。
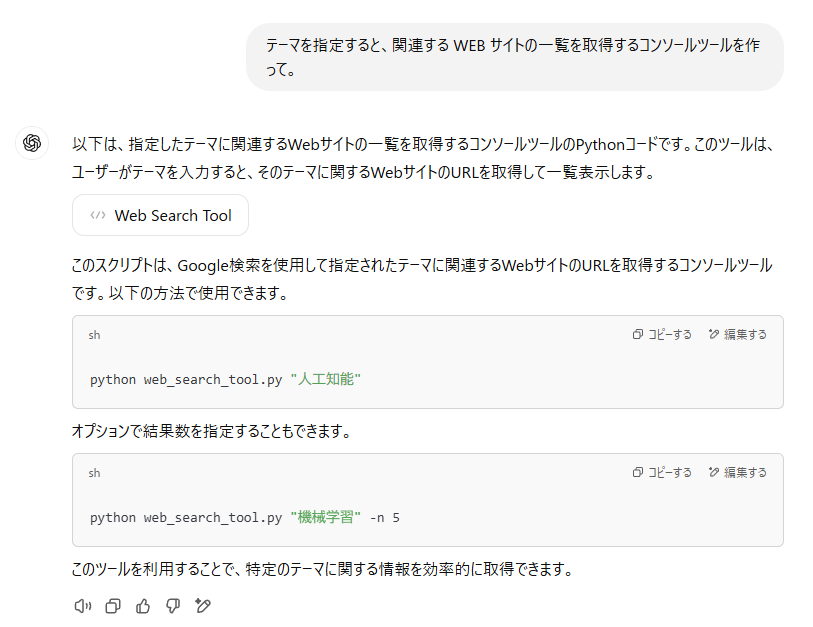
実は、この時点では Google で検索するコードを Python で出してくれます。確かに Google でもいいのですが、ここは OpenAI API を使ってもらいましょう。
openai API を使う書き方に直して。

OpenAI の gpt-4 モデルを使った Python コードに直してくれました。ただ、私の場合は .NET でやりたかったので、C# に書き直して貰います。
C# のコードに直して。
この時点で、かなり動くコードがでてきます。
class Program
{
private static readonly string apiKey = "your_openai_api_key";
static async Task Main(string[] args)
{
if (args.Length == 0)
{
Console.WriteLine("Usage: dotnet run <theme> [-n <number_of_results>]");
return;
}
string theme = args[0];
int numResults = 10;
if (args.Length > 2 && args[1] == "-n" && int.TryParse(args[2], out int parsedNum))
{
numResults = parsedNum;
}
Console.WriteLine($"Searching for: {theme}\n");
var results = await SearchWeb(theme, numResults);
if (results.Count > 0)
{
Console.WriteLine("Related Websites:");
for (int i = 0; i < results.Count; i++)
{
Console.WriteLine($"{i + 1}. {results[i]}");
}
}
else
{
Console.WriteLine("No results found.");
}
}
static async Task<List<string>> SearchWeb(string theme, int numResults)
{
using HttpClient client = new HttpClient();
client.DefaultRequestHeaders.Add("Authorization", $"Bearer {apiKey}");
var requestBody = new
{
model = "gpt-4",
messages = new[]
{
new { role = "system", content = "You are a helpful assistant." },
new { role = "user", content = $"List {numResults} websites related to {theme}." }
}
};
string jsonRequest = JsonSerializer.Serialize(requestBody);
var response = await client.PostAsync(
"https://api.openai.com/v1/chat/completions",
new StringContent(jsonRequest, Encoding.UTF8, "application/json")
);
if (!response.IsSuccessStatusCode)
{
Console.WriteLine("Error: Unable to fetch search results.");
return new List<string>();
}
string responseContent = await response.Content.ReadAsStringAsync();
using JsonDocument doc = JsonDocument.Parse(responseContent);
var content = doc.RootElement.GetProperty("choices")[0].GetProperty("message").GetProperty("content").GetString();
var results = new List<string>(content.Split('\n', StringSplitOptions.RemoveEmptyEntries));
return results;
}
}
プロンプトで「iBeaconのフォーマットについて」で検索させるとこんな感じです。

URLが出てくるので、これをピックアップするためのコードを Copilot に書いて貰いました。
static List<string> ExtractUrls(List<string> results)
{
var urlPattern = new Regex(@"https?://[\w./?=&-]+", RegexOptions.Compiled);
return results.Select(result => urlPattern.Match(result).Value).Where(url => !string.IsNullOrEmpty(url)).ToList();
}

あとは、URL を読み込んで要約を出すわけですが、これも Copilot を使っています。
/// <summary>
/// URLを指定したら内容を要約して返す関数
/// </summary>
/// <param name="url"></param>
/// <returns></returns>
static string Shlink(string url)
{
using HttpClient client = new HttpClient();
client.DefaultRequestHeaders.Add("Authorization", $"Bearer {apiKey}");
var requestBody = new
{
model = "gpt-4",
messages = new[]
{
new { role = "system", content = "You are a helpful assistant." },
new { role = "user", content = $"Summarize the content of the website {url}." }
}
};
string jsonRequest = JsonSerializer.Serialize(requestBody);
var response = client.PostAsync(
"https://api.openai.com/v1/chat/completions",
new StringContent(jsonRequest, Encoding.UTF8, "application/json")
).Result;
if (!response.IsSuccessStatusCode)
{
Console.WriteLine("Error: Unable to fetch search results.");
return "";
}
string responseContent = response.Content.ReadAsStringAsync().Result;
using JsonDocument doc = JsonDocument.Parse(responseContent);
var content = doc.RootElement.GetProperty("choices")[0].GetProperty("message").GetProperty("content").GetString();
return content ?? "none";
}
こんな風に関数を作ってもらって、それを main に組み込みます。関数を作って貰うときは、関数の定義(ここでは、static string Shlink(string url) の部分)を書いたあとに、関数の前にコメントを書くと Copilot が自動補完してくれます。
この操作は、ChatGPTのブラウザ上でやってもいいでしょう。私の場合 Copilot のほうが慣れているので、Visual Studio Code 上でやっています。
表示しているところを何回かに分けて書き直しています。
Console.WriteLine($"Searching for: {theme}\n");
var results = await SearchWeb(theme, numResults);
if (results.Count > 0)
{
Console.WriteLine("Related Websites:");
for (int i = 0; i < results.Count; i++)
{
Console.WriteLine($"{i + 1}. {results[i]}");
}
Console.WriteLine("urls:");
var urls = ExtractUrls(results);
urls.ForEach(url => Console.WriteLine(url));
foreach (var url in urls)
{
var summary = Shlink(url);
Console.WriteLine("--------------------");
Console.WriteLine($"Summary of {url}");
Console.WriteLine("\n");
Console.WriteLine( summary);
}
}
else
{
Console.WriteLine("No results found.");
}
デバッグ動作も兼ねて、区切りを入れたり URL を表示させておきます。
注意)何回か動かすと openai API のリクエスト制限に引っ掛かるらしく TooManyRequests のエラーが返ってきます。いまテストしていたら引っ掛かってしまったので、また明日追記の予定。
こんな感じで、一発でプロンプトを使ってコードを出力するわけではなくて、ChatGPT や Copilot を使いながら何回か出力してコードを組み立てていく例です。コード自体は1時間ちょいぐらいで動くようになります。その後、何回かテストするの1時間ぐらいかかるけど。
実行例


そのままだと、OpenAI の回答が英語になるのですが、プロンプトを追加すれば英語から日本語に翻訳してくれます。
var requestBody = new
{
model = "gpt-4o-mini",
messages = new[]
{
new { role = "system", content = "You are a helpful assistant." },
new { role = "system", content = "応答は日本語に翻訳して" },
new { role = "user", content = $"Summarize the content of the website {url}." }
}
};
日本語訳

iBeacon の場合は企業サイトが多いので直接クローリングができないっぽいです。公開されている技術文書や論文とかだったらいけるんじゃないかな。