参考先
ニコニコインフォ https://blog.nicovideo.jp/niconews/225099.html
当社サービスへのサイバー攻撃に関するFAQ | 株式会社ドワンゴ https://dwango.co.jp/news/5088891233107968/
現在のニコニコ動画には課金もしていないし、あまり見ることもなくなって久しいのですが、ニコニコ動画が始まった当初(ハルヒや、文字ぴったんや、初音ミクや、アイマスの「とかちつくちて」のあたりとか)の頃は結構見ていたので、それのお礼も兼ねて考察しておきます。
というか、半田病院のランサムウェアの件とかIT屋としてはなんとか対処したい案件ではあります。遭遇したくはないが、遭遇してしまったときに被害を最小におさえときたい。
現在、ツイッター(新X)で憶測が走り回っていて、いろなものがリツーイト(新ポスト)されてくるのですが、合っているような合ってないような、合ってないようなものが多いので、ちょっとイライラします。イライラを個人にぶつけるのはアレなので(新型コロナ以来、この手の代理戦争はしない、と決めています)、掃き出し口として自分のブログに残しておきます。この手の方法は、心理学的にも行動経済学的にも「システム1を垂れ流しにしない」こととして有効なので、何か別のものに書きつけておくのは良い方法です。意外と、それだけで気持ちがおさまるので。
犯人像を考える
犯人像を考えるのは捜査のプロファイル手法としての常套手段です。というのが「羊たちの沈黙」という小説にあってですね、当時は流行ったのです。実際にFBIで取り入られている手法なのですが(今はよくわかりません)、犯人像を決めてその動機や知識から実際の犯行の手段を想像し、現実の犯行とあわせてみるという考え方です。こうすると、犯人がかなり絞り込めます。
同じようにサーバー攻撃を考えるときに、犯人が何を求めているのか?を考えます。

一般的にサーバー攻撃は、愉快犯、敵対攻撃、ランサムウェアによる身代金、機密情報の奪取(顧客情報など)に分けられます。愉快犯や敵対攻撃の場合、サーバー攻撃は非常に簡単です。システムダウンが目的なので、DDoS攻撃のような単純なものが使われます。相手のホームページに犯行声明を上げたりするパターンもあります。当初、ニコニコ動画が動かなくなっていたときには、DDoS攻撃かと言われいたものですが、犯行声明などがないので「ランサムウェア」ではないか、と思っていました。
ところが、周知の通りランサムウェアの場合は、相手のファイルを暗号化させて身代金を取って復号化する、という手段が必要になります。目的は「身代金=ビットコインなど」なのですから、相手のシステムをダウンさせてはいけません。まして、今回のように復旧に至ってしまっては、サイバー攻撃をした意味がないのです。

角川社内の顧客情報やクレジットカードの情報を抜き出すということも考えられるのですが、その場合でもシステム全体をアウトにする必要はありません。むしろ損です。
社内の機密情報を抜き取りたい(顧客情報を売る、クレジットカード情報をとる、インサイダー取引情報を抜き出す)場合には、できるだけ角川のシステムを生かしておかないといけません。さらに、継続的に情報を抜き出すためには、もっと目につかない形でこっそりとやるのが常套手段です。
情報抜き取りのほうは、これからの調査で、実は5年前ぐらいからやられていた、というパターンも考えられます。で、だいたい抜き取ってしまったので、犯人が遊びで角川のシステムをダウンさせた、とも考えられます。これは、もう少し経ったら解る情報でしょう。
現在のところは、そういう情報がないので、「犯人は、ランサムウェアで身代金をとろうとした」と考えるのが妥当です。
そうなると、システム全体がアウトになった原因はどこにあるのか?ということになります。犯人としてはシステム全体をダウンさせることは望んでいません。むしろ、一部だけを暗号化したかったわけです。そうしないと身代金をとれないですからね。
となると、システム全体に被害が広まってしまったのではカドカワシステムの自責ではないか?と思われるのです。
ネットワーク図を考える
私はカドカワ相手に仕事をしたことがないので、このような想像でネットワーク図を書けるのですが、仕事で関わっている人は書けないですよね。なので、あくまで想像です。先の「ニコニコインフォ」から想像したものです。
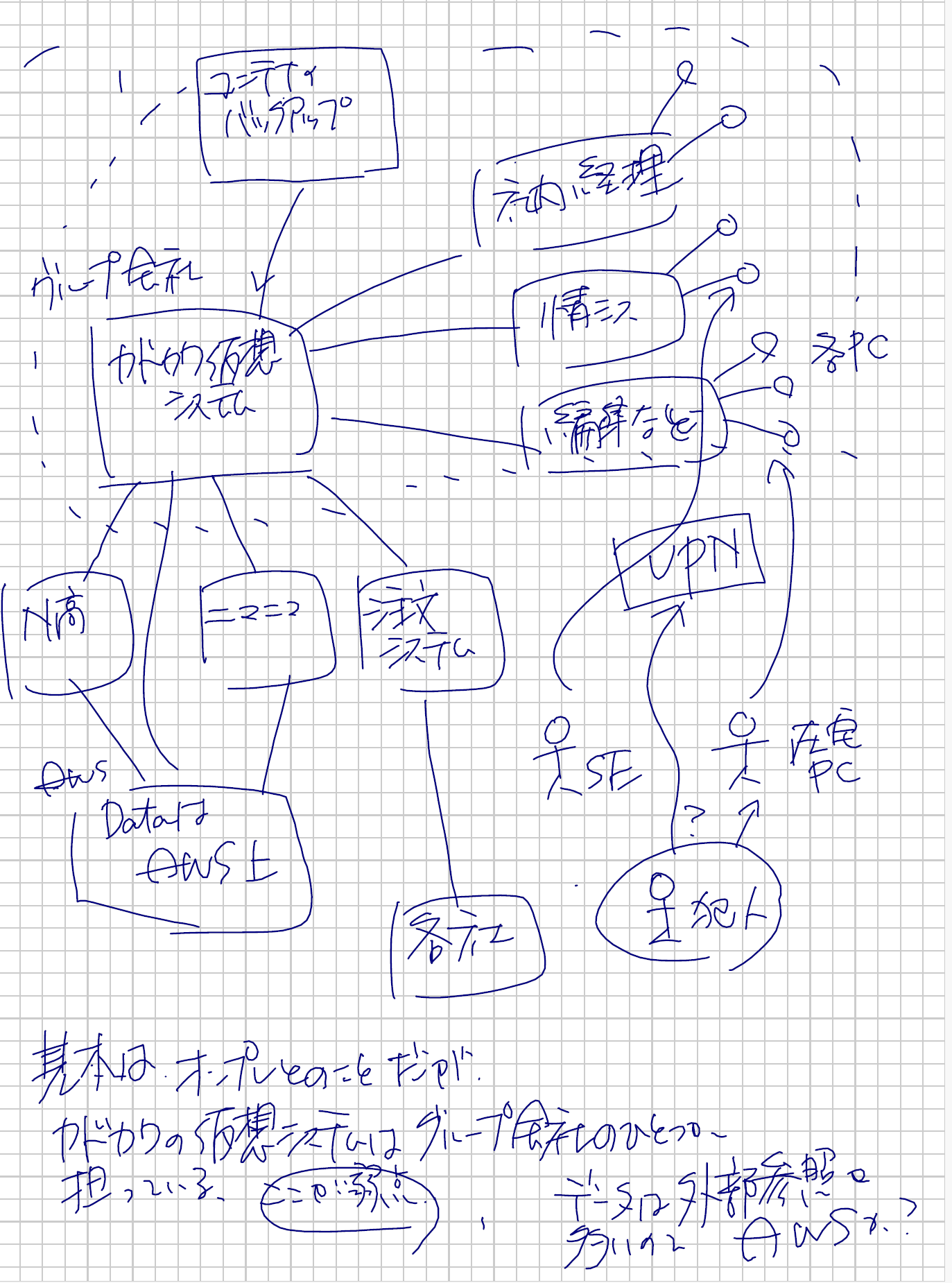
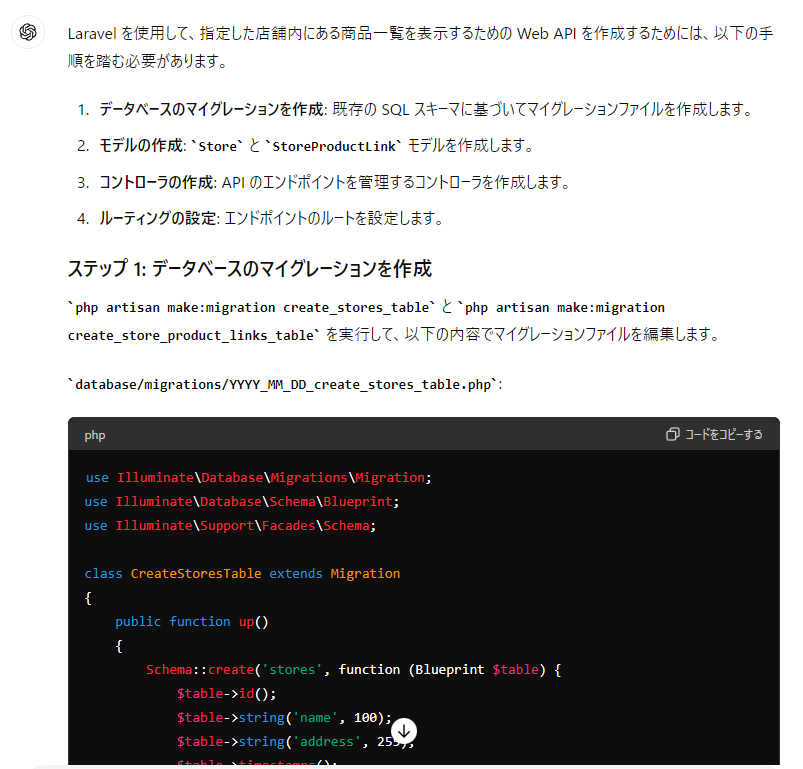
「グループ企業が提供するデータセンター内サーバー間の~」の部分が気になりました。どうも提供している会社は一社(Kadokawa connected)で、その会社が一括してさまざまなカドカワのシステムを担っているような雰囲気です。これは、グループ会社全体での作業の効率化にはなるし、情報のやりとりが素早くできるという大きな利点があるのですが、今回のようにサーバーのひとつがやられると隣接するサーバーもやられてしまう、このとき隣接するサーバーが多いと被害も大きくなってしまいます。おそらく、全社のサーバーがひとつに集まっていた(ひとつのネットワークを共有していた)のが被害が大きくなった要因と考えられます。
侵入経路は内部犯行、外部からのアクセス、社員PCのアクセス等が考えられるのですが、戸田病院の例などを考えるとVPN経由で侵入されるパターンと思われます。実際にこの手のサーバー攻撃でランサムウェアが使われる場合はVPN経由が多いのが常です(どこかで円グラフがあるのですが、40%ぐらいはそれです)。
VPNは別の物理ネットワークを仮想的にひとつのネットワークとしてつなげられるという便利さはあるのですが、ある意味でいったんVPNの仮想ネットワークに侵入されてしまうと同じネットワーク内ということなってしまうので、社内ネットワークが乗っ取られやすい状態になってしまいます。
特に、今回の場合は社内の社員PCよりもサーバーにランサムウェアを仕込まれていることから、社外からアクセスする社員SE(あるいはPC)経由でVPNを奪取されたと考えられます。
あと、VPN経由などでサーバーを起動できるのは結構普通にできるので、別に不思議なものではありません。ポートを叩く方式とソフトウェアを使う方式があります。どちらかの犯人側がスクリプトで動かせばよい(社内の別のサーバーで定期的に)ので、その方式かなと思われます。
犯人側からは想定外がおきた
繰り返しになりますが、私見では「犯人側から想定外だった」と考えています。ある意味で、ニコニコ動画をダウンさせる(最初の6/8に発覚したのがニコニコ動画なので、ニコニコ動画のサーバー狙いじゃないかな)つもりだったのが、カドカワの社内業務システムに広がってしまったという現象でしょう。あるいは、その逆かもしれません。
ターゲットとしては、ニコニコ動画のような結構技術的に復旧可能そうな陣営に手を出すよりも、社内業務のサーバーを暗号化してしまって、ちょっとした身代金で済むと思わせたほうが犯人としては儲かりますからね。

被害拡大を防ぐには
カドカワ本体としてもN高などの緊急性の高いもの(一般層からのパッシングが高いもの)は早めに復旧したいところです。幸いにもN高のシステムは復旧が早く(バックアップあるいは再構築手順がうまくなされていた?)現状では支障がなさそうです。
ただし、できることならば、社内業務がやられてしまっても、N高やニコニコ動画には影響がないようにネットワークを組んでおくのがベストと思われます。

一般的には古い対策ではありますが、物理的にネットワークを分ける手段が考えれます。もともと、カドカワの各社グループは別のネットワークだったわけですから、相互をあまり使わない形でネットワークを組むことも考えられます。が、確かカドカワのシステムをAWSに乗せ換えるなどの処置が進めていたため( AWSコスト最適化ガイドブック https://www.hanmoto.com/bd/isbn/9784046053558)このあたりが、社内の仮想化の部分とAWSの仮想化の部分で密接になってしまったのかもしれません。社内の仮想システムの攻撃(おそらくランサムウェアによる社内仮想化ファイルの暗号化)は、犯人にとっては想定外と思われます。メンテナンスシステムの利便性を考えて、ネットワークを共通化する(あるいは管理者IDの共通化?)したことによる弊害ではないかと考えられます。
官庁絡みではありますが、この手のバックアップを守る手段としては、
- 物理的にHDDを抜いてしまってバックアップを守る
- 定期的に磁気テープに出力する
- 相互に関係ない部署(特に財務系、社内業務、B2Cシステム)ではネットワークを切り離す
という手段が取られます。
SE(システムエンジニア)的にもプログラマ的にも今回のサイバー攻撃は、ちゃんと考察したおいてほうがいいかな、と思って記録に残しておきます。もちろん、ニコニコ動画の復旧を応援しながらでもあり、ここまでは私の想像でしかないのですが。
補足ですが、以下のようにプライベートクラウド(社内の仮想システム)の場合はアウトで、パブリッククラウド(おそらくAWSのこと)の運用には影響がなかったということなので、「AWSのほうが安全だった」という結果になっていますね。たまに、ツイッターで逆の意見が多い(プライベートクラウドのほうが安全)という話がでているので、注意してください。

追記 2024/06/23
NewsPicks のスクープが載った模様。ほぼ、これが正解でしょう。既に身代金を払っていて、更に追加を要求されて広がっている、という最悪な状態。これでは KADOKAWA 側を擁護できない…
追記 2024/07/04
追加で身代金を払ったのか定かではないが、流出サイトからは削除された模様。
このツイートの参考先も真偽は明らかではないが、記録のため。