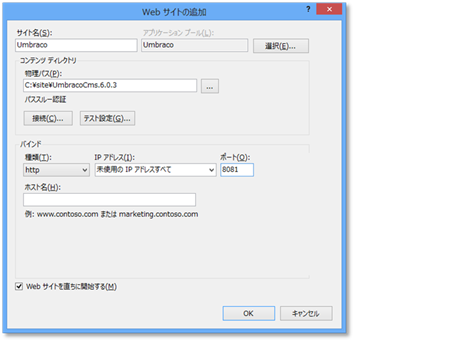
SSDにするとBlukcopyは5倍ぐらい早くなる – Moonmile Solutions Blog の比較として、MySQL では、SSD/HDD はどうなんだろうね?という話です。MySQL の Connector には Bulkcopy っぽいものがないので、ちまちまと insert しています。なので、その分遅くなるので、適当に1000件単位でトランザクション使って commit します。1件ずつ insert するよりは早いのですが、SQL Server よりは SSD 比で 10 倍ぐらい、HDD 比で 2 倍ぐらい遅いです。SSD/HDD で倍数に差がでているのは、SQL Server + SSD がむちゃくちゃ早いからですね。
追記 MySqlBulkLoader というものがあるそうなので、後で試します。




SSD で 65.3秒、HDD で 74.2秒。
| SSD | HDD | |
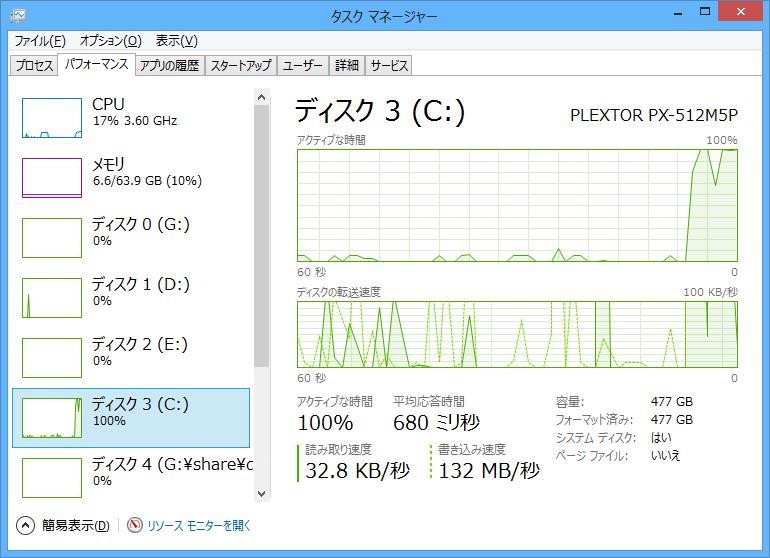
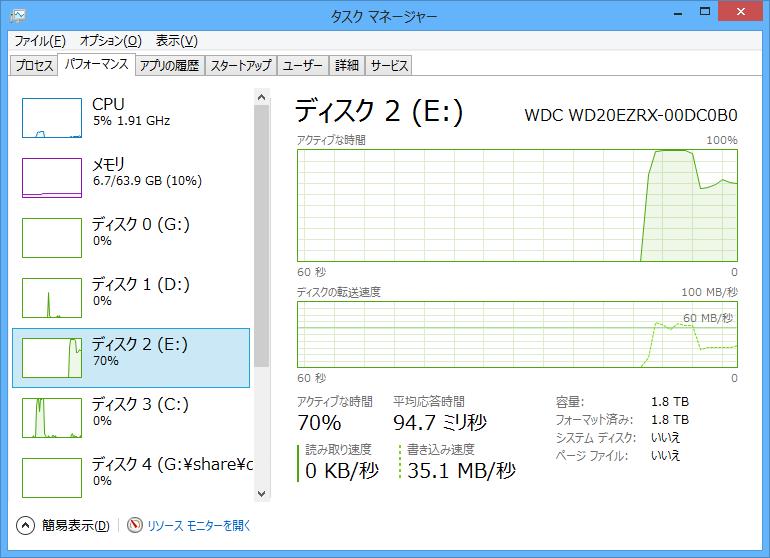
| SQL Server | 7.8 sec | 32.1 sec |
| MySQL | 65.3 sec | 74.2 sec |
ってことで、SQL Server は bulkcopy, MySQL はトランザクション使ったinsert文なので、相互には比較できませんが(今度 SQL Server のほうを insert 文に変えて実験しましょう)、SSDとHDDの比較で言えば、SQL Server のほうが断然効果的…という結論ではなくて、MySQL が SSD の書き込みスピードに追い付いていないってのが遅い原因です。
| 書き込み速度 | SSD | HDD |
| SQL Server | 132 MB/sec | 35.1 MB/sec |
| MySQL | 11.0 MB/sec | 約7 MB/sec |
になるので、SQL Server の HDD 書き込みよりも遅いスピードで SSD に書きにいっちゃってます。この要因は、プログラム側にもあって、
- MySQLにバルクコピーがないので、ちまちま insert してる。
- たぶん、DataTable から CommandParamter に移す時にスピードが遅くなってる。
てな感じでしょうか。でも、まあ、100万件のアクセス生ログを 1分弱で insert できるのは結構よいかなと。以前、mysqldump したのだと30分位かかって気がします(以前とは、メモリもCPUも違うので単純比較はできませんが)。
MySQL のデータファイルを HDD/SSD に振り分ける方法は、漢(オトコ)のコンピュータ道: InnoDBのファイルサイズ管理 にある、innodb_file_per_table の設定と、シンボリックリンク(mklink)を使っています。この方法は別のエントリにまとめます。
以下は、insert 文のところの抜粋です。参考にでも。
async Task GoBlukCopy(string CNSTR)
{
MySqlConnection cn = new MySqlConnection(CNSTR);
MySqlCommand cmd = new MySqlCommand("INSERT INTO logs values ( @dt, @code, @ip, @req, @url )", cn );
cmd.Parameters.Add( new MySqlParameter("@dt", MySqlDbType.String ));
cmd.Parameters.Add( new MySqlParameter("@code", MySqlDbType.String ));
cmd.Parameters.Add( new MySqlParameter("@ip", MySqlDbType.String ));
cmd.Parameters.Add( new MySqlParameter("@req", MySqlDbType.String ));
cmd.Parameters.Add( new MySqlParameter("@url", MySqlDbType.String ));
DateTime start = DateTime.Now;
_completed = false;
_count = 0;
await Task.Factory.StartNew(
() =>
{
cn.Open();
// 1000件ごとにcommit する
MySqlTransaction tr = cn.BeginTransaction();
foreach (DataRow row in _dt.Rows)
{
cmd.Parameters["@dt"].Value = row["dt"];
cmd.Parameters["@code"].Value = row["code"];
cmd.Parameters["@ip"].Value = row["ip"];
cmd.Parameters["@req"].Value = row["req"];
cmd.Parameters["@url"].Value = row["url"];
cmd.ExecuteNonQuery();
_count++;
if (_count % 1000 == 0)
{
tr.Commit();
tr = cn.BeginTransaction();
}
}
tr.Commit();
cn.Clone();
_completed = true;
});
}