サーバーレスな Azure Functions の練習がてら、Redmine の API を呼び出してみるテストを晒しておきます。Azure Functions の詳しい説明は、https://docs.microsoft.com/ja-jp/azure/azure-functions/ を参考にしてもらうとして、一番手軽なのは HttpTrigger である。普通の Web API と同じように URL アドレス経由で呼び出して、指定のファンクションを実行する。「ファンクション」とは言っても、F# とか Scala のような「関数型」のファンクションではないのだけど、ある意味「ステートレス」ということでは、AWS の Lambda もファンクションだし、Azure Functions もファンクションなので、「関数」って訳語が付けられているのだが。果たしてこれは、正しいのか?ってのは微妙だ。
ローカルにFunction Appを作る
Function Appは、Azure 上で作って運用するのだけど、実はローカルなPC上でもAzure Functionsを実行できる。
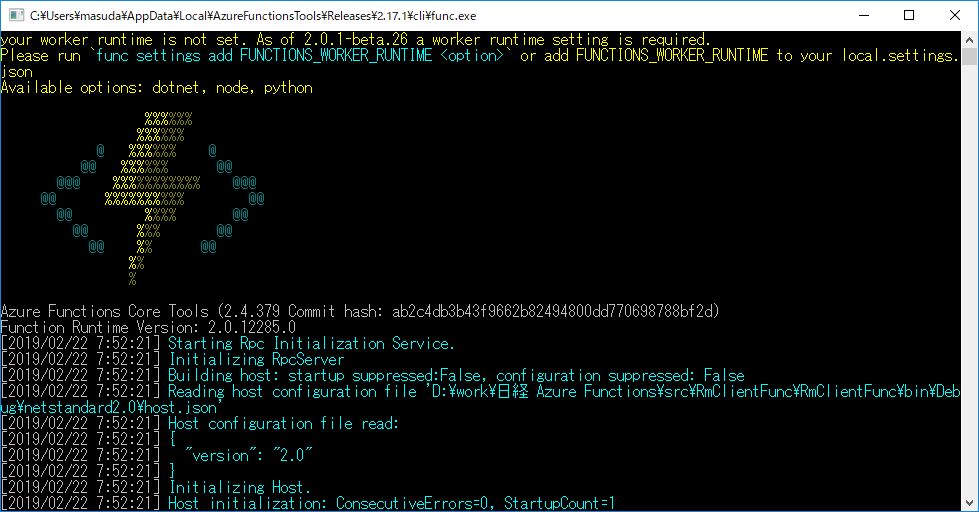
Azure Functions Core Tools のインストール
https://docs.microsoft.com/ja-jp/azure/azure-functions/functions-run-local
をインストールすると、ローカルPCでテスト実行ができるようになる。
実は、このツールは、Visual Studio でAzure Functionsのプロジェクトを作って実行すると、自動でインストールされる。

ちょうど、ASP.NET Core MVC のアプリをテスト実行したときと同じように、.NET Core 上のコマンドが動いてAzure Functionsのエミュレータが起動する。
ファンクションを作る
関数の作り方は非常に簡単だ。ちょうど、ASP.NET MVC の Controller にメソッドを作るようにファンクションを作っていく。ASP.NET MVC の Controller と違うのは、static クラスに static メソッドとして定義されているところだ。
ASP.NET MVC の場合も HTTPプロトコルでステートレスなのだから、意味あいとしは同じと言えば同じなのだが。ひとまず、Azure側からstatic関数として呼び出されることになる。だから「ステートレス」っていのが明確になっている。
public class App
{
public const string ApiKey = "<api_key>"
public const string BaseUrl = "<redmine_url>";
}
public static class ProjectFunc
{
private static string ApiKey = App.ApiKey;
private static string BaseUrl = App.BaseUrl;
private static HttpClient client = new HttpClient();
private static int _count = 0; // 呼び出しカウンタ
/// <summary>
/// プロジェクトリストを取得
/// </summary>
/// <param name="req"></param>
/// <param name="log"></param>
/// <returns></returns>
[FunctionName("GetProjects")]
public static IActionResult GetList(
[HttpTrigger(AuthorizationLevel.Function, "get", "post", Route = "Project/List")]
HttpRequest req, TraceWriter log)
{
var json = client.GetStringAsync($"{BaseUrl}/projects.json?key={ApiKey}").Result;
_count++;
log.Info($"count: {_count}");
var data = JsonConvert.DeserializeObject<ProjectList>(json);
foreach ( var proj in data.projects )
{
log.Info($"{proj.id}: {proj.name}");
}
return new OkObjectResult(json);
}
[FunctionName("GetProject")]
public static IActionResult Get(
[HttpTrigger(AuthorizationLevel.Function, "get", "post", Route = "Project/Get")]
HttpRequest req, TraceWriter log)
{
string id = req.Query["id"];
var json = client.GetStringAsync($"{BaseUrl}/projects/{id}.json?key={ApiKey}").Result;
var proj = JsonConvert.DeserializeObject<Project>(json);
log.Info($"{proj.id}: {proj.name}");
return new OkObjectResult(json);
}
}
HttpTrigger は URLアドレス経由で呼び出されるので、URLはFunction Appで使われる API KEY を含めて、
https://sample-azfunc-dotnet.azurewebsites.net/api/HttpTrigger1?code=xxxxxxxx
な形で呼び出されるのだが、ここではローカルのテスト環境なのでcodeを省略して、
http://localhost:7071/api/Project/List
のように呼び出すことができる。
実は、呼び出すときの関数名は FunctionName 属性で設定するのだけど、この属性でフォルダーを掘ることができない。引数についている HttpTrigger.Route にフォルダー付きの呼び出しを付けられるので、これを使うと Project/List とか Project/Get?id=100 のような Web API っぽい形に変えられる。
Redmine の JSON をクラスにする
Redmine を API で呼び出すと、JSON形式あるいはXML形式で受け取ることができる。以前は、これを手作業でクラスに直していた(コンバーターも手で作ってた)のだが、Visual Studio で「編集」→「形式を選択して貼り付け」を使うと、元のJSON形式のデータから、
C#のクラスに直すことができる。
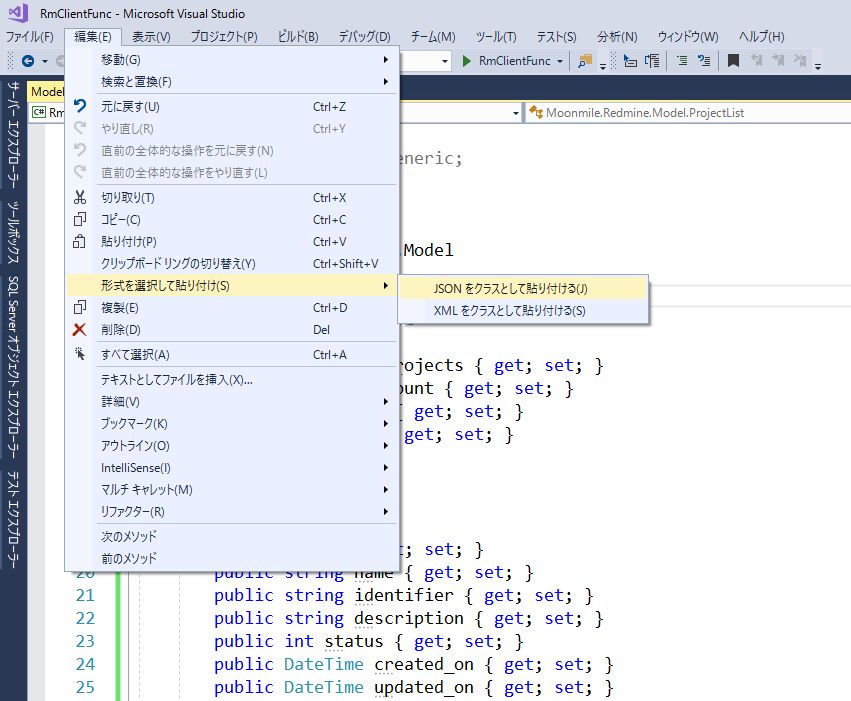
ルートのノードが「Rootobject」となるので、適宜「ProjectList」とか「ProjectItem」とかに直してやる。
これと、JsonConvert.DeserializeObject メソッドを組み合わせると、JSON形式のデータを一気にクラスに直せる。
実行してみる
Visual Studio 上でデバッグ実行をして、
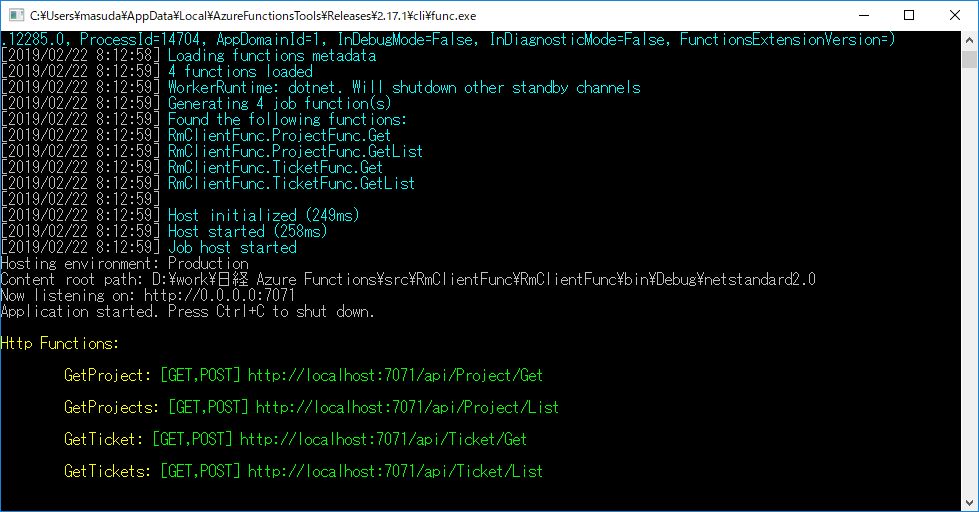
ブラウザから、http://localhost:7071/api/Project/List を実行すると、別途 Redmine が動いているサーバーに接続して、JSON形式で受け取ることができる。
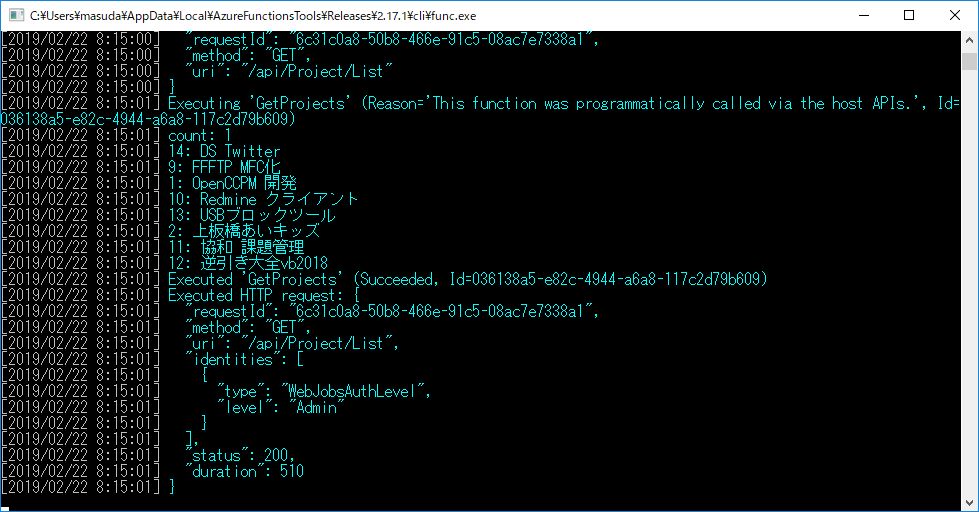
各種 WEB API の呼び出し形式がまちまちだったりするので、こんな風にFunction Appを使って、統一的にアクセスできるようにコンバートすると GUI 側の変更が楽になるのではないかな、と試作&思索しているところ。