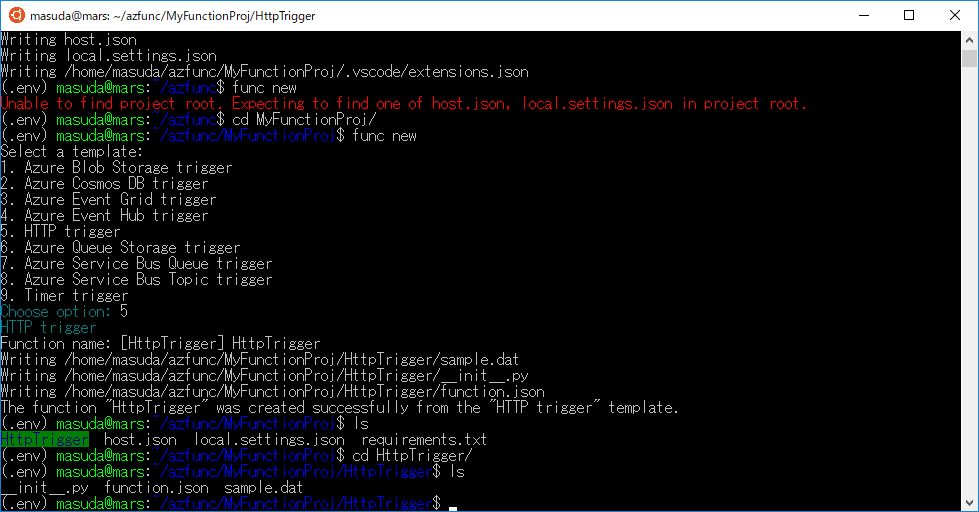
ひとまず、Laravel に慣れるために MVC パターンを直接扱ってみる。先に InfyOm を使って自動作成してみたのだが、エラーが頻発してよくわからん。ので、そういうときは手作業でやってみるに限る。
目的としては、
- wordpress のような既存のデータベースを読み込む
- マスター管理のような CRUD ベースのページを自動作成する
- 場合によっては、CRUD な Web API も自動生成する。
- 場合によっては、クライアントから呼び出すコード(C#, nodejsとか)も生成してしまう。
まずは、xampp で wordpress をインストールして、mysql 部分だけアクセス可能にしておく。
composer でインストール&動作確認
適当なフォルダーを作成して、Laravel をインストール
composer create-project --prefer-dist laravel/laravel blog
データベースの設定
/.env を修正。wordpress のデータベースを読み込ませる。
DB_CONNECTION=mysql
DB_HOST=127.0.0.1
DB_PORT=3306
DB_DATABASE=wordpress
DB_USERNAME=wordpress
DB_PASSWORD=wordpress
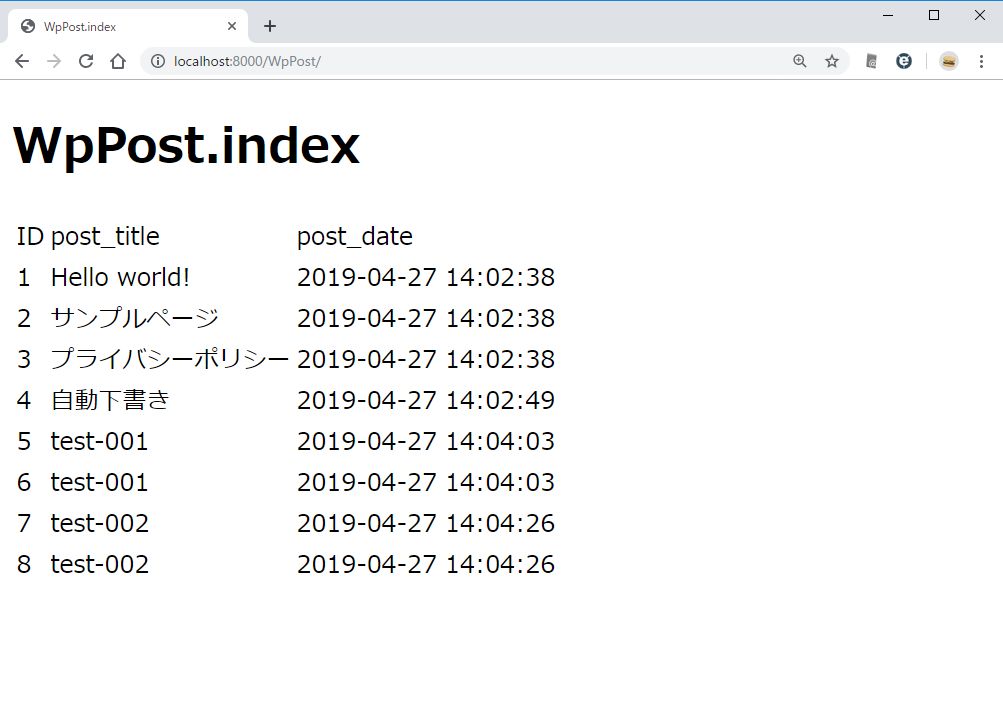
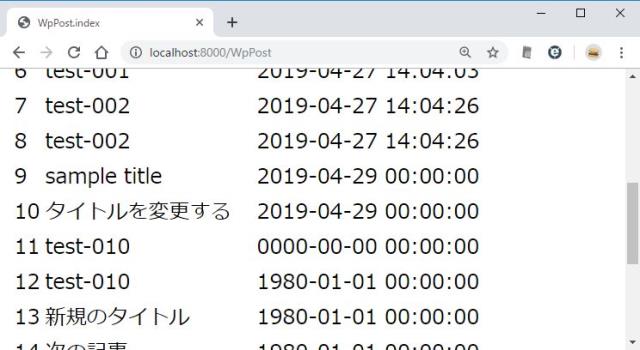
リスト表示を作成
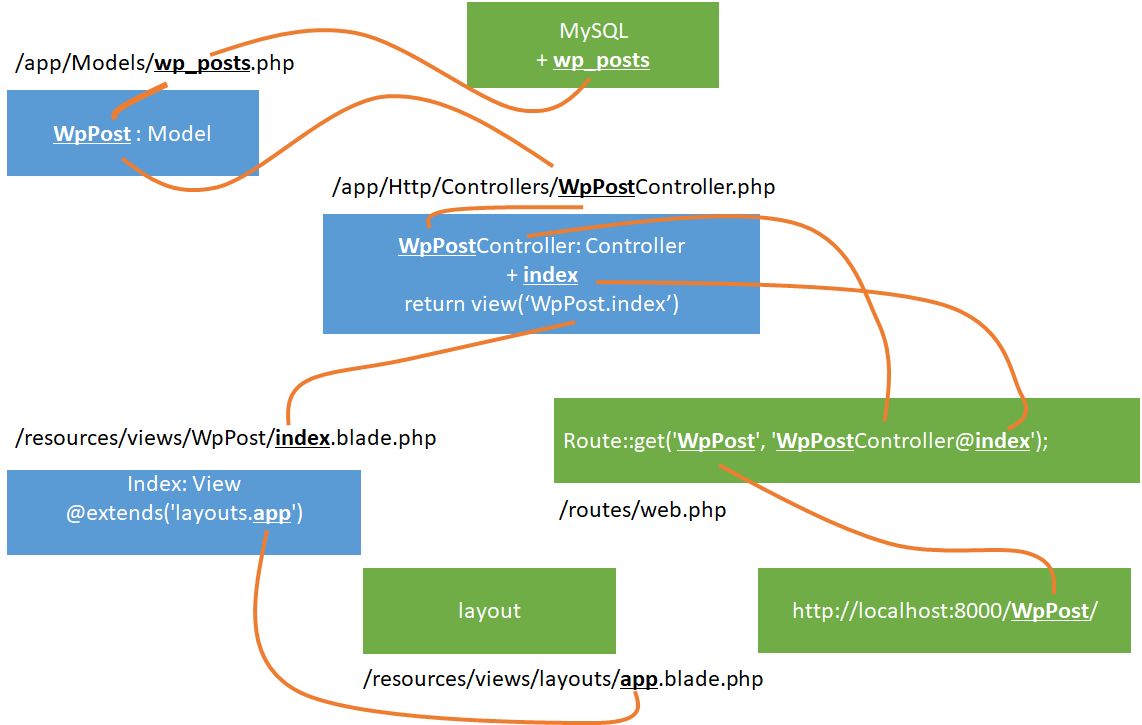
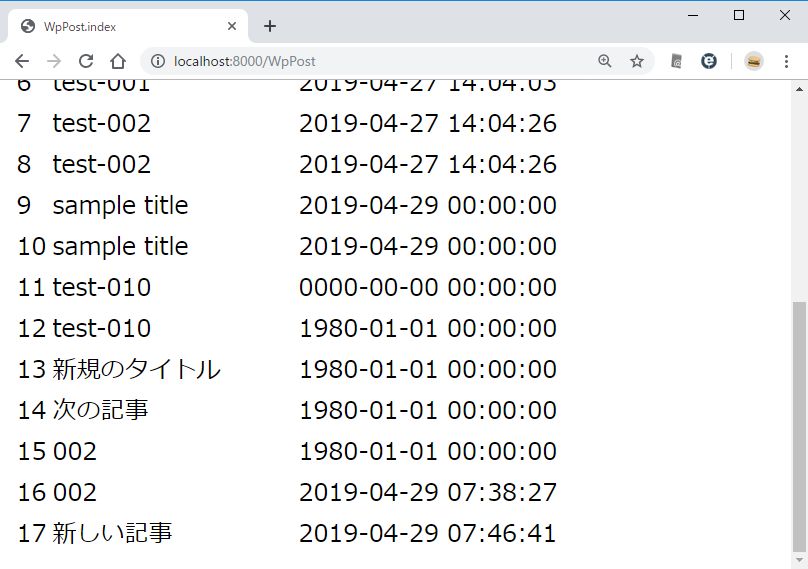
いわゆるトップにアクセスして、一覧を表示させる。http://localhost:8000/WpPost/ にアクセスする。wordpress の記事は wp_posts にあるのだが、これを Model クラスでは WpPost として使う。
Model の作成
Model クラスを作る。対象のテーブル名を記述していないが、この手の MVC パターンの命名規約に
- テーブル名は複数形、モデルクラスは単数形
- モデルクラスは、キャメルパターンが多い
- テーブル名はスネークパターンが多い
- 「_」が単語の区切りになる。
ということで、自動的に WpPost から wp_posts を推測させている。wordpress の場合プレフィックスは「wp_」とは限らないので、このあたりは明示的にテーブル名を指定したほうがよいかも。
php artisan make:model Models/WpPost
/app/Models/wp_posts.php が生成される
<?php
namespace App\Models;
use Illuminate\Database\Eloquent\Model;
class WpPost extends Model
{
//
}
Model クラスの中身が空っぽで不安になるが、これで ORM されている。ただし、条件があって、
- プライマリーキーは「id」の int 型である。
- 作成日時に「create_on」を使う。
- 更新日時に「update_on」を使う。
が必要になる。これを満たすテーブルの場合はそのまま使えるし、新規にテーブルを作るときはこの規約に合わせるほうが便利(テーブルの複数形もあわせて)。
ただ、今回は既存の wordpress のテーブルを使うので、この条件が少し違っている。これは後で修正することになる。
Controller の作成
コントローラーは、モデル名 + 「Controller」となる。
php artisan make:controller WpPostController
/app/Http/Controllers/WpPostController.php が生成される
<?php
namespace App\Http\Controllers;
use Illuminate\Http\Request;
class WpPostController extends Controller
{
//
}
これも中身が空っぽで不安になるのだが、ここは手作業で作ることになる。別途、自動生成することもできるのだけど、今回は手動で作ってみる。
リスト表示する index アクションだけ追加する。
<?php
namespace App\Http\Controllers;
use Illuminate\Http\Request;
use App\Models\WpPost;
class WpPostController extends Controller
{
public function index()
{
$items = WpPost::all();
return view('WpPost.index', ['items' => $items]);
}
}
データベースから全件拾ってくる all() を使うのと、ビューに渡すために items で参照できるようにしておく。
- ASP.NET の EF のように、ent.WpPost.ToList() な感じで取得
- ViewBag( “items” ) = items のようなもの
View を作成する
/resources/views/layouts/app.blade.php を作成する。いわゆる
全ページから参照するテンプレートで、@extends(‘layouts.app’) で参照できるようにする。
<!DOCTYPE html>
<html>
<head>
<title>
@yield('title')
</title>
</head>
<body>
<h1>@yield('title')</h1>
<div class="content-wrapper">
@yield('content')
</div>
</body>
</html>
各ページから入れ込む部分は「@yield()」で書いておく。各ページからは「@section()」で参照する。本来は CSS とか JS とかの読み込みが書いてるのだが、今回はシンプルに書いておく。
一覧表を表示するページはこっち。/resources/views/WpPost/index.blade.php を新規作成する。
@extends('layouts.app')
@section('title','WpPost.index')
@section('content')
<table>
<thead>
<td>ID</td>
<td>post_title</td>
<td>post_date</td>
</thead>
<tbody>
@foreach( $items as $item )
<tr>
<td>{{ $item->ID }}</td>
<td>{{ $item->post_title }}</td>
<td>{{ $item->post_date }}</td>
</tr>
@endforeach
</tbody>
</table>
@endsection
レイアウトのファイルを「@extends(‘layouts.app’)」で参照している。あと、コントローラーから渡された、$items を使ってリスト表示する。
ルート情報を追加
/routes/web.php に追加する
Route::get('WpPost', 'WpPostController@index');
ブラウザから呼び出すと、どこが呼び出されるかを記述する。「http://localhost:8000/WpPost」とすると、WpPostController クラスの index メソッドが呼び出される。
ブラウザで表示する.
簡易 HTTP サーバーを動かして、呼び出してみる。
php artisan serve
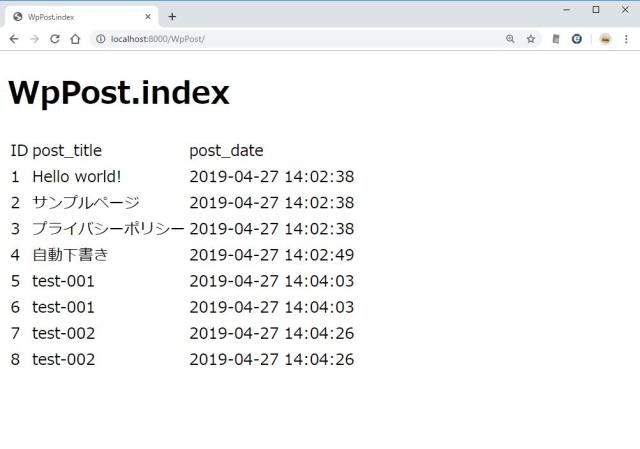
作成順序
MVC パターンを使うと、書き込むコードや設定があちこち散るのが大変なのだけど、手順を作っておくと便利だったりする。
- モデルクラスを作る /app/Models/wp_posts.php
- コントローラーを作る /app/Http/Controllers/WpPostController.php
- アクションを作る WpPostController::index
- ビューを作る /resources/views/WpPost/index.blade.php
- ルート情報を作る /routes/web.php
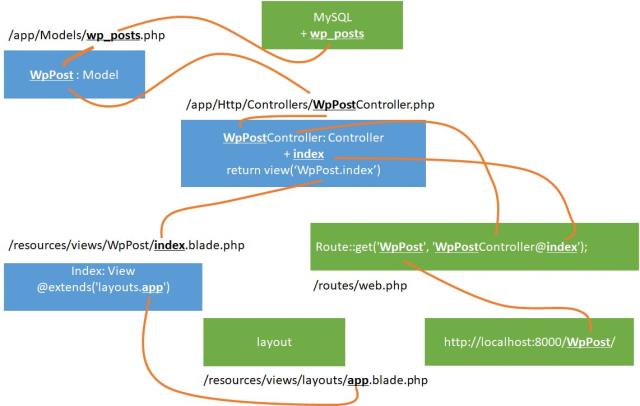
Laravel の場合は、Model -> Controller -> View -> ルート情報(web.php) の順で作っていくとわかりやすい。
詳細表示を作成
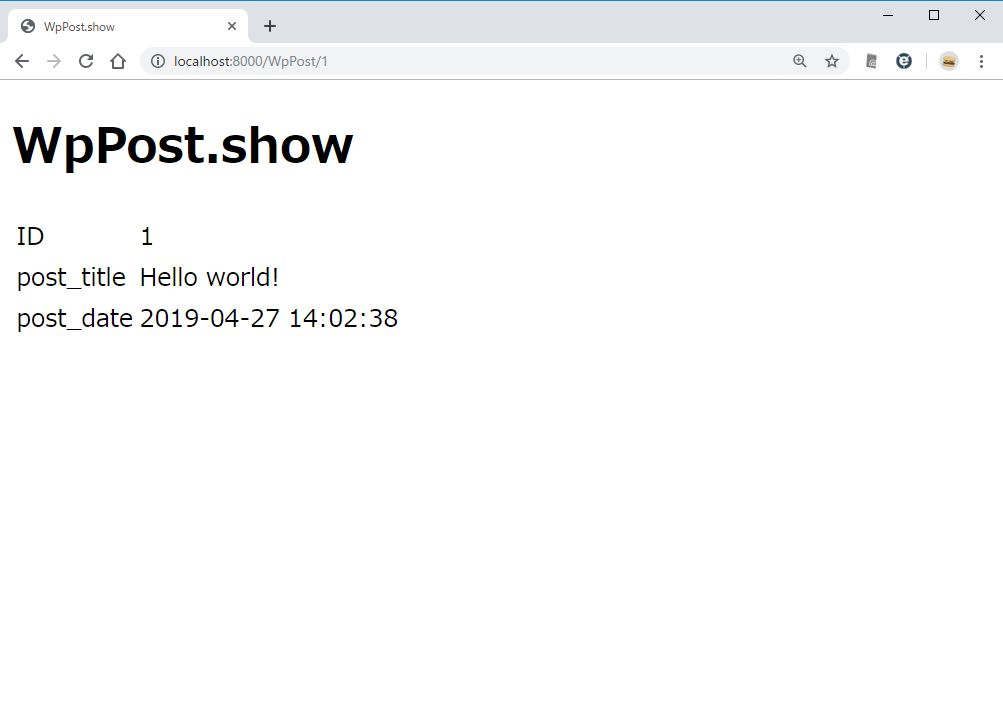
id を指定して詳細表示をするページを作る。http://localhost:8000/WpPost/1 のように ID を指定してページを開く。
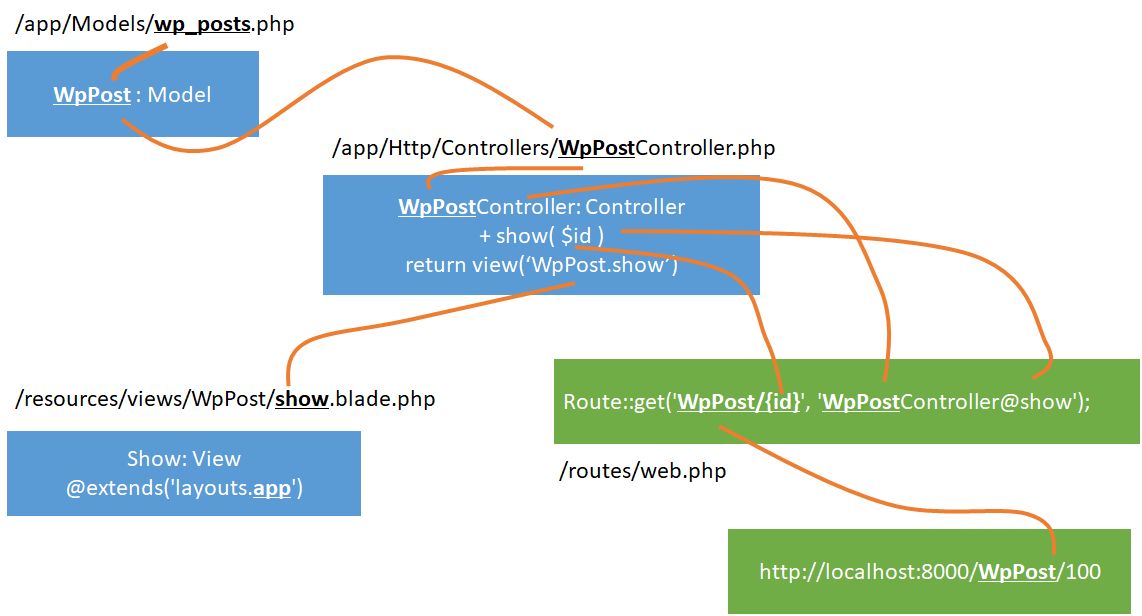
Controller の作成
/app/Http/Controllers/WpPostController.php を編集
<?php
class WpPostController extends Controller
{
...
public function show($id) {
$item = WpPost::find($id);
return view('WpPost.show', ['item' => $item]);
}
}
プライマリ―キーの id での検索は find() を使う。
View を作成する
/resources/views/WpPost/show.blade.php を新規作成する。
@extends('layouts.app')
@section('title','WpPost.show')
@section('content')
<table>
<tr>
<td>ID</td>
<td> {{ $item->ID }}</td>
</tr>
<tr>
<td>post_title</td>
<td> {{ $item->post_title }}</td>
</tr>
<tr>
<td>post_date</td>
<td> {{ $item->post_date }}</td>
</tr>
</table>
@endsection
ルート情報を追加
/routes/web.php に追加する
Route::get('WpPost/{id}', 'WpPostController@show');
ブラウザで表示する.
http://localhost:8000/WpPost/1
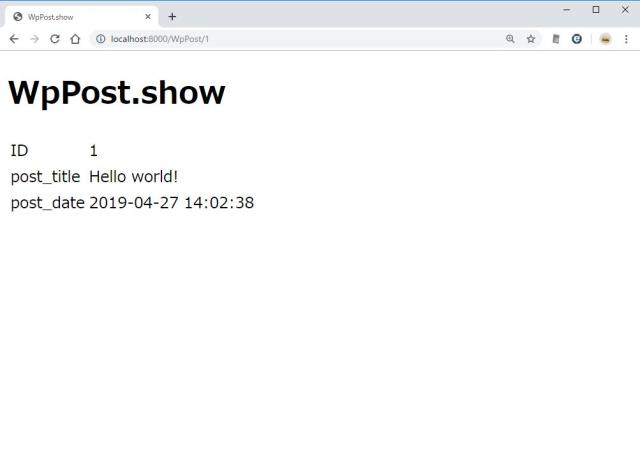
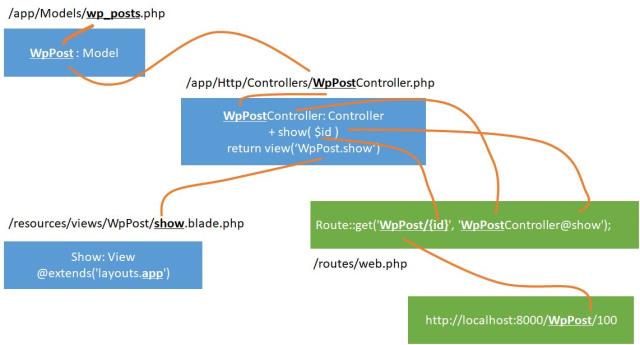
MVC パターンの関係はこうなっている。
Create ページを追加
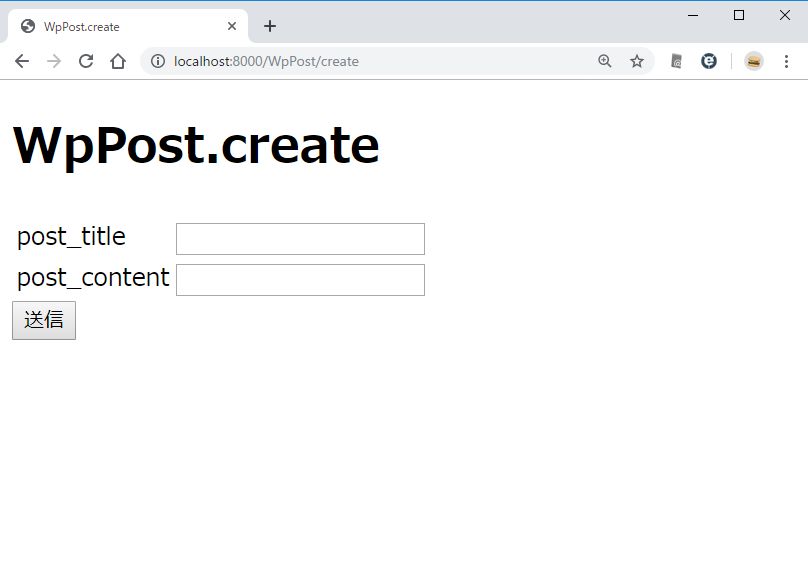
新規作成のページを作る。
- 新規入力をする create
- データを登録する store
に分かれる
Model を修正
/app/Models/wp_posts.php を修正
- ID が自動インクリメントなので除外する
- create_at, update_at を除外する
- デフォルト値を補う
class WpPost extends Model
{
// IDは自動インクリメント
protected $guarded = array('ID');
// 作成日、更新日はなし
const CREATED_AT = null;
const UPDATED_AT = null;
public function __construct() {
// insert 時にデフォルト値を補っておく
$this->post_excerpt = '';
$this->to_ping = '';
$this->pinged = '';
$this->post_content_filtered = '';
}
}
Controller を追加
/app/Http/Controllers/WpPostController.php を編集
class WpPostController extends Controller
{
...
/// 新規作成(入力)
public function create() {
$item = new WpPost();
return view('WpPost.create', ['item' => $item]);
}
/// 新規入力(登録)
public function store( Request $request ) {
$item = new WpPost();
$form = $request->all();
unset($form['_token']);
$item->fill($form);
// 現在時刻を入れておく
$item->post_date = date('Y-m-d H:i:s');
$item->save();
return redirect('/WpPost');
}
}
View を作成する
/resources/views/WpPost/create.blade.php を新規作成する。
@extends('layouts.app')
@section('title','WpPost.create')
@section('content')
<form action="/WpPost/create" method="post" >
{{ csrf_field() }}
<table>
<tr>
<td>post_title</td>
<td><input type="text" name="post_title" value="{{ $item->post_title }}" /></td>
</tr>
<tr>
<td>post_content</td>
<td><input type="text" name="post_content" value="{{ $item->post_content }}" /></td>
</tr>
</table>
<input type="submit" />
</form>
@endsection
ルート情報を追加
/routes/web.php に追加する
- create と store は、show の前に入れる
Route::get('WpPost', 'WpPostController@index');
Route::get('WpPost/create', 'WpPostController@create');
Route::post('WpPost/create', 'WpPostController@store');
Route::get('WpPost/{id}', 'WpPostController@show');
ブラウザで表示する.
http://localhost:8000/WpPost/create
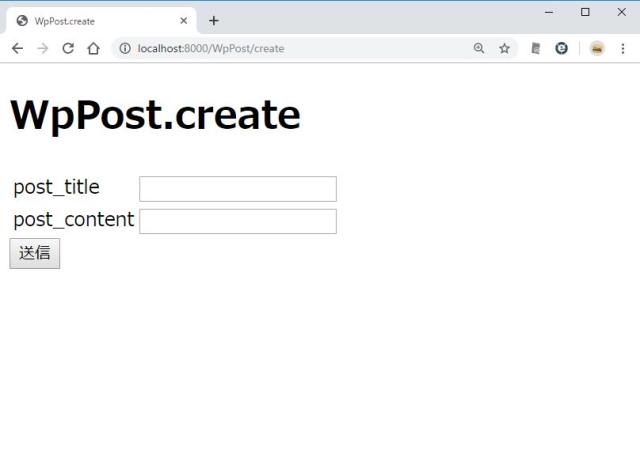
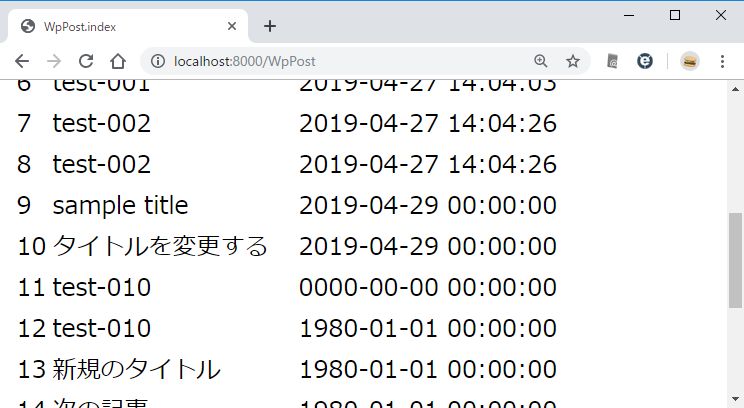
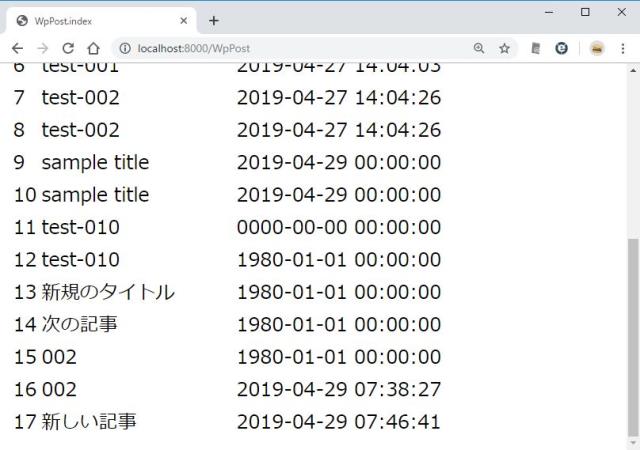
エラーがなければ、一覧へ戻る
編集画面を作る
の2つのアクションの分かれる
Model の修正
/app/Models/wp_posts.php を修正
- プライマリ―キーが 「id」以外の時は $primaryKey で設定
class WpPost extends Model
{
// IDは自動インクリメントなので除外
public $incrementing = true ;
protected $guarded = array('ID');
// プライマリーキー名を変更
protected $primaryKey = 'ID';
// 作成日、更新日はなし
const CREATED_AT = null;
const UPDATED_AT = null;
public function __construct() {
// insert 時にデフォルト値を補っておく
$this->post_excerpt = '';
$this->to_ping = '';
$this->pinged = '';
$this->post_content_filtered = '';
}
}
Controller を作る
/app/Http/Controllers/WpPostController.php を編集
class WpPostController extends Controller
{
...
/// 更新(入力)
public function edit($id) {
$item = WpPost::find($id);
return view('WpPost.edit', ['item' => $item]);
}
/// 更新(コミット)
public function update(Request $request) {
$item = new WpPost();
$form = $request->all();
$id = $form['ID'];
unset($form['_token']);
$item = WpPost::find($id);
$item->fill($form);
// 更新日時を入れておく
$item->post_modified = date('Y-m-d H:i:s');
$item->save();
// 一覧へ戻る
return redirect('/WpPost');
}
}
View を作成する
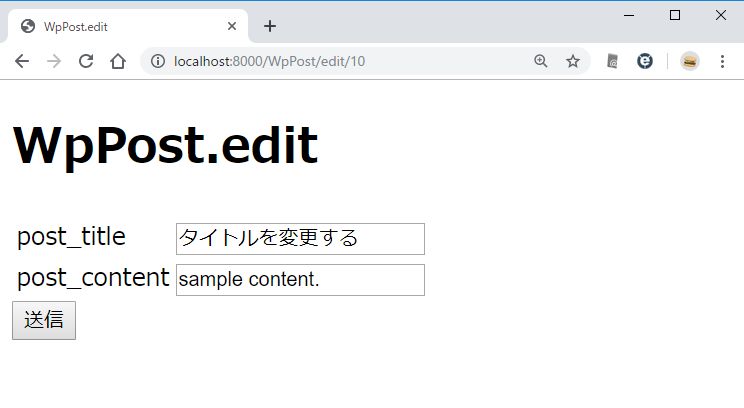
/resources/views/WpPost/edit.blade.php を新規作成する。
@extends('layouts.app')
@section('title','WpPost.edit')
@section('content')
<form action="/WpPost/edit" method="post" >
{{ csrf_field() }}
<input type="hidden" name="ID" value="{{ $item->ID }}" />
<table>
<tr>
<td>post_title</td>
<td><input type="text" name="post_title" value="{{ $item->post_title }}" /></td>
</tr>
<tr>
<td>post_content</td>
<td><input type="text" name="post_content" value="{{ $item->post_content }}" /></td>
</tr>
</table>
<input type="submit" />
</form>
@endsection
ルート情報を追加
/routes/web.php に追加する
- create と update は、show の前に入れる
- update のほうに、id が含められないので、form から取得する
Route::get('WpPost/edit/{id}', 'WpPostController@edit');
Route::post('WpPost/edit', 'WpPostController@update');
Route::get('WpPost/{id}', 'WpPostController@show');
ブラウザで表示する.
http://localhost:8000/WpPost/create
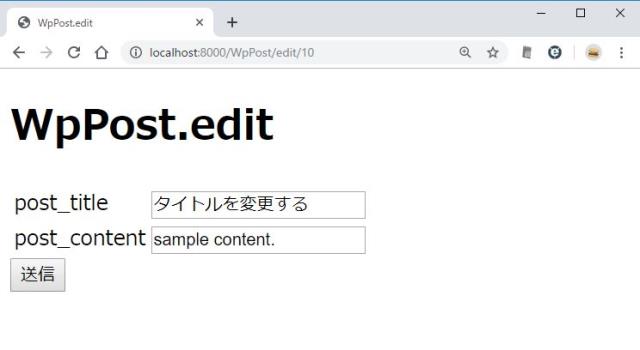
エラーがなければ、一覧へ戻る
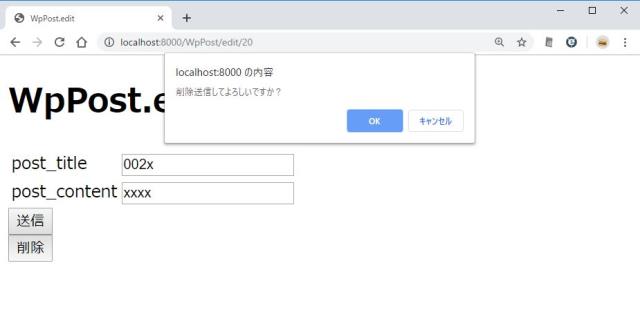
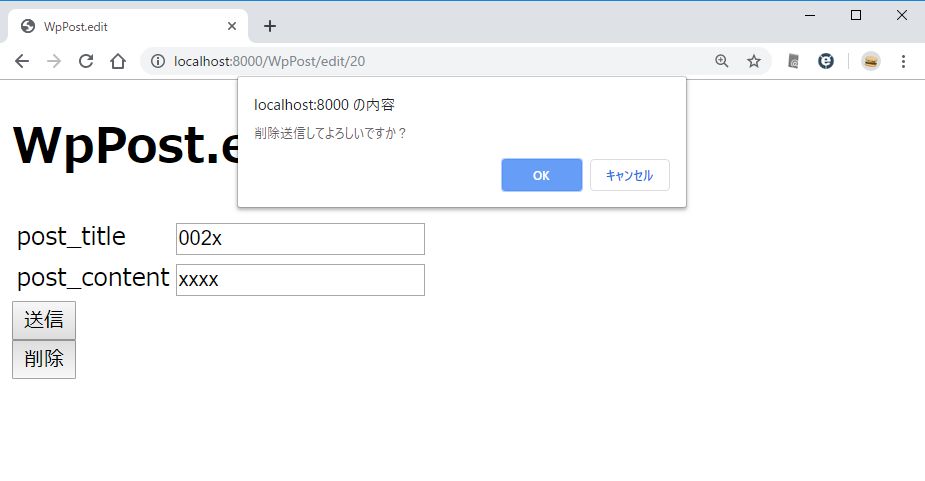
アイテムを削除する
- 更新画面に「削除」ボタンを追加する
- 削除処理をする
の2つのアクションの分かれる
Controller を作る
/app/Http/Controllers/WpPostController.php を編集
class WpPostController extends Controller
{
...
/// 削除
public function destroy( Request $request ) {
$form = $request->all();
$id = $form['ID'];
WpPost::find($id)->delete();
// 一覧へ戻る
return redirect('/WpPost');
}
}
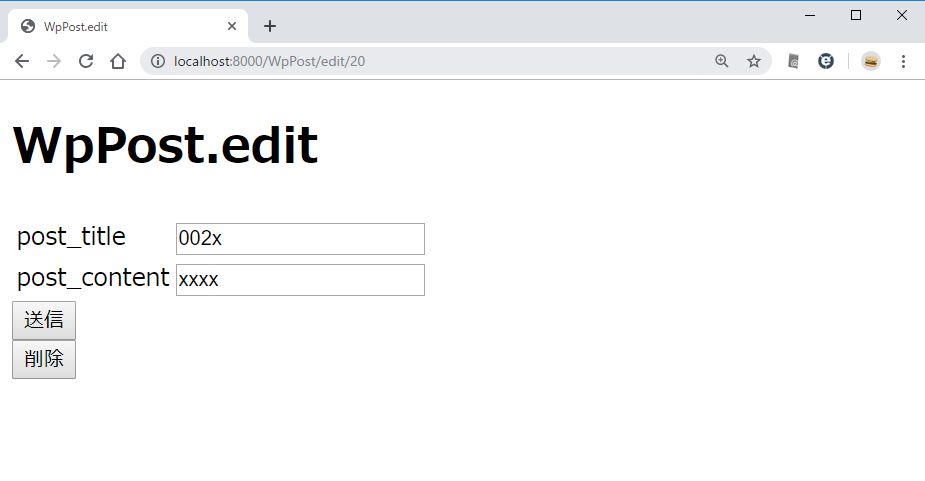
View を編集する
/resources/views/WpPost/edit.blade.php に追記する
下のほうに「削除」ボタンを付ける。
@extends('layouts.app')
@section('title','WpPost.edit')
@section('content')
<form action="/WpPost/edit" method="post" >
{{ csrf_field() }}
<input type="hidden" name="ID" value="{{ $item->ID }}" />
<table>
<tr>
<td>post_title</td>
<td><input type="text" name="post_title" value="{{ $item->post_title }}" /></td>
</tr>
<tr>
<td>post_content</td>
<td><input type="text" name="post_content" value="{{ $item->post_content }}" /></td>
</tr>
</table>
<input type="submit" />
</form>
<script>
function check(){ return window.confirm('削除してよろしいですか?'); }
</script>
<form action="/WpPost/delete" method="post" onSubmit="return check()" >
{{ csrf_field() }}
<input type="hidden" name="ID" value="{{ $item->ID }}" />
<input type="submit" value="削除" />
</form>
@endsection
ルート情報を追加
/routes/web.php に追加する
- destroy は、show の前に入れる
- destroy に、id が含められないので、form から取得する
Route::post('WpPost/delete', 'WpPostController@destroy');
Route::get('WpPost/{id}', 'WpPostController@show');
ブラウザで表示する.
http://localhost:8000/WpPost/edit/10
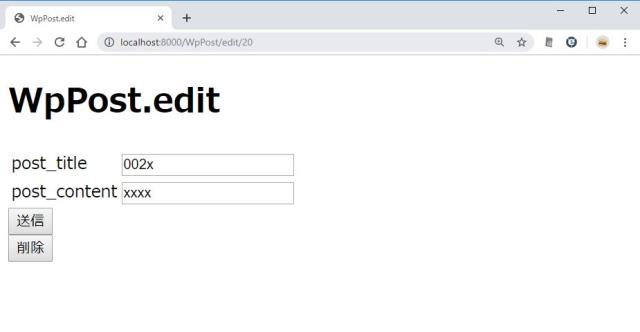
「削除」ボタンを押したときに問い合わせのダイアログが出る。