今更ながら、Visual Studio 2010 の Test Framework を試してみました(NUnit は既に試しているのですが)。
- テストプロジェクトを自動で生成してくれる。
- テストメソッドのひな型を自動で作ってくれる。
というのが売りらしいのですが、メソッドのひな型のほうは慣れると普通に作れます…というか、最初のひとつが面倒なだけで、あとはコピー&ペーストでいけます。
実行したいメソッドのところで、右クリックして「テストの実行」を選択すると
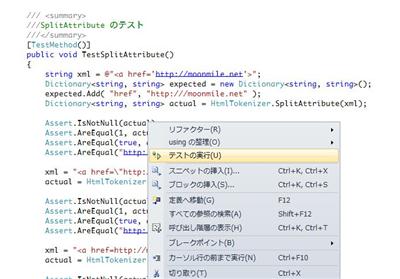
指定したメソッドが実行できます。
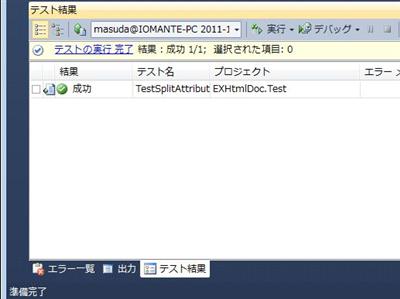
テスト結果は、Visual Studio 上で確認できます。
右上にある「デバッグ」で実行させるとブレークポイントで止めることができるし、結構便利です。
NUnit を使う場合は、デバッグするときの「外部プログラムの開始」を設定するとできるので、同じことができるのですが指定したメソッドだけを動かすというのがなかなか難しいので(GUI 上で選択しないといけないし)。
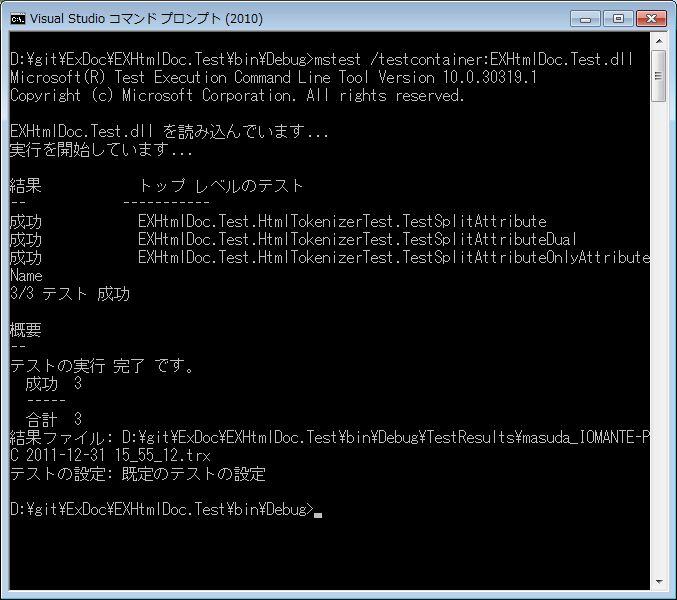
ちなみにコマンドラインで動かす場合には、MSTest.exe を使います。
mstest /testcontainer:EXHtmlDoc.Test.dll
で、NUnit でも MSTest でも、この手の自動単体テストツールを使うといいのは、比較的ごちゃごちゃしたコードでも、そこそこ動くようなものが短時間で作れるということです。
次のような、ごちゃっとしたコードが、
class HtmlTokenizer
{
public static Dictionary<string, string> SplitAttribute(string xml)
{
var WHITESPACE = new char[]{ ' ', '\n' };
var WHITESPACE_END = new char[] { ' ', '\n', '>' };
var WHITESPACE_END_EQUAL = new char[] { ' ', '\n', '>','=' };
Dictionary<string, string> attrs = new Dictionary<string, string>();
if (xml.Length == 0) return attrs;
if (xml[0] != '<') return attrs;
xml = xml.Substring(1);
int pos = xml.IndexOfAny(WHITESPACE_END);
if (pos == -1) return attrs;
xml = xml.TrimStart(WHITESPACE);
string tagname = "";
pos = xml.IndexOfAny(WHITESPACE_END);
if (pos == -1) return attrs;
tagname = xml.Substring(0, pos );
xml = xml.Substring(pos + 1);
while (xml.Length > 0)
{
string attrname = "";
string attrvalue = "";
xml = xml.TrimStart(WHITESPACE);
if (xml.Length == 0) break;
if (xml[0] == '>') break;
pos = xml.IndexOfAny(WHITESPACE_END_EQUAL);
if (pos == -1) break;
if ( xml[pos] != '=' )
{
// 属性名のみ
pos = xml.IndexOfAny(WHITESPACE_END);
if (pos == -1) break;
attrname = xml.Substring(0, pos);
}
else
{
attrname = xml.Substring(0, pos).TrimStart(WHITESPACE);
xml = xml.Substring(pos + 1).TrimStart(WHITESPACE);
if (xml.Length == 0) break;
if (xml[0] == '\'')
{
pos = xml.IndexOf('\'', 1);
if (pos == -1) break;
attrvalue = xml.Substring(1, pos - 1);
xml.Substring(pos + 1);
}
else if (xml[0] == '"')
{
pos = xml.IndexOf('\"', 1);
if (pos == -1) break;
attrvalue = xml.Substring(1, pos - 1);
xml.Substring(pos + 1);
}
else
{
pos = xml.IndexOfAny(WHITESPACE_END);
if (pos == -1) break;
attrvalue = xml.Substring(0, pos);
xml.Substring(pos);
}
}
if (attrname != "")
{
attrs.Add(attrname, attrvalue);
}
xml = xml.Substring(pos + 1);
}
return attrs;
}
}
次のようなテストコードを記述することで、1時間弱で作れます。
/// <summary>
///SplitAttribute のテスト
///</summary>
[TestMethod()]
public void TestSplitAttribute()
{
string xml = @"<a href='http://moonmile.net'>";
Dictionary<string, string> expected = new Dictionary<string, string>();
expected.Add( "href", "http:///moonmile.net" );
Dictionary<string, string> actual = HtmlTokenizer.SplitAttribute(xml);
Assert.IsNotNull(actual);
Assert.AreEqual(1, actual.Count);
Assert.AreEqual(true, actual.ContainsKey("href"));
Assert.AreEqual("http://moonmile.net", actual["href"]);
xml = "<a href=\"http://moonmile.net\">";
actual = HtmlTokenizer.SplitAttribute(xml);
Assert.IsNotNull(actual);
Assert.AreEqual(1, actual.Count);
Assert.AreEqual(true, actual.ContainsKey("href"));
Assert.AreEqual("http://moonmile.net", actual["href"]);
xml = "<a href=http://moonmile.net>";
actual = HtmlTokenizer.SplitAttribute(xml);
Assert.IsNotNull(actual);
Assert.AreEqual(1, actual.Count);
Assert.AreEqual(true, actual.ContainsKey("href"));
Assert.AreEqual("http://moonmile.net", actual["href"]);
}
/// <summary>
///SplitAttributeのテスト
/// 属性が複数ある場合
///</summary>
[TestMethod()]
public void TestSplitAttributeDual()
{
string xml = @"<a href='http://moonmile.net' title='moonmile solutions' >";
Dictionary<string, string> expected = new Dictionary<string, string>();
expected.Add("href", "http:///moonmile.net");
expected.Add("title", "moonmile solutions");
Dictionary<string, string> actual = HtmlTokenizer.SplitAttribute(xml);
Assert.IsNotNull(actual);
Assert.AreEqual(2, actual.Count);
Assert.AreEqual(true, actual.ContainsKey("href"));
Assert.AreEqual("http://moonmile.net", actual["href"]);
Assert.AreEqual(true, actual.ContainsKey("title"));
Assert.AreEqual("moonmile solutions", actual["title"]);
}
/// <summary>
///SplitAttributeのテスト
/// 属性名のみの場合
///</summary>
[TestMethod()]
public void TestSplitAttributeOnlyAttributeName()
{
string xml = @"<a mark href='http://moonmile.net'>";
Dictionary<string, string> expected = new Dictionary<string, string>();
expected.Add("mark", "");
expected.Add("href", "http:///moonmile.net");
Dictionary<string, string> actual = HtmlTokenizer.SplitAttribute(xml);
Assert.IsNotNull(actual);
Assert.AreEqual(2, actual.Count);
Assert.AreEqual(true, actual.ContainsKey("href"));
Assert.AreEqual("http://moonmile.net", actual["href"]);
Assert.AreEqual(true, actual.ContainsKey("mark"));
Assert.AreEqual("", actual["mark"]);
xml = @"<a href='http://moonmile.net' mark >";
actual = HtmlTokenizer.SplitAttribute(xml);
Assert.IsNotNull(actual);
Assert.AreEqual(2, actual.Count);
Assert.AreEqual(true, actual.ContainsKey("href"));
Assert.AreEqual("http://moonmile.net", actual["href"]);
Assert.AreEqual(true, actual.ContainsKey("mark"));
Assert.AreEqual("", actual["mark"]);
}
}
まあ、あまりにもごちゃごちゃし過ぎているので、後でテストコードで確認しながらリファクタリングをしますが。
このあたりの書き方は、
- オブジェクトクラスで設計する。
- メソッドの役割を決める。
- メソッドのフローチャートを書く。
- テストコードを書く。
- テストコードが動作するように、メソッドの実装を書く。
というコーディングの仕方では、絶対できません…と言いますか、少し入り組んでしまったコードの場合、設計から始めると大抵の場合破綻します。
なので、
- 単純に動くテストコードを2,3件作る。
- テストコードから、どのようにメソッドを呼び出すかを決める。
- テストコードがコンパイルできるように、メソッドを記述する。
- テストが通るようにメソッドを記述する。
- 大まかなところをメソッドで記述する。
- 記述した実装が通るか、テストで確認する。
- 5と6 を繰り返す。たまに逆もやってみる。
- コードがごちゃごちゃし始めたら、テストコードを元にリファクタリングする。
という書き方になります。
実は 2 のところが重要で、テストからうまく実装クラスを呼び出せない場合は、先行き、複雑化しすぎてバグを含み始めるという(経験上の)現象があります。あるいは、複雑すぎて使えないクラスが大量にできることになります。
なので、利用可能な範囲で、メソッドを「直感的に」使えるようにしておくのが基本です。

まあ、そういう訳で後で SplitAttribute を書き直しますか。