Excel VBA で jQuery のようにアクセスできるライブラリを作れるか? | Moonmile Solutions Blog
http://www.moonmile.net/blog/archives/3217
なところの続き。と言うか、あのときは Excel VBA 内に閉じてないと使いづらいのでは?と思っていたのですが、Excel VBA から COM ライブラリを呼び出す、という方法でもいいことに気づきました。そこで、C# の相互運用(COMアクセス)を利用して、Excel を jQuery 風に使うライブラリ作成の続きおば。
■用法
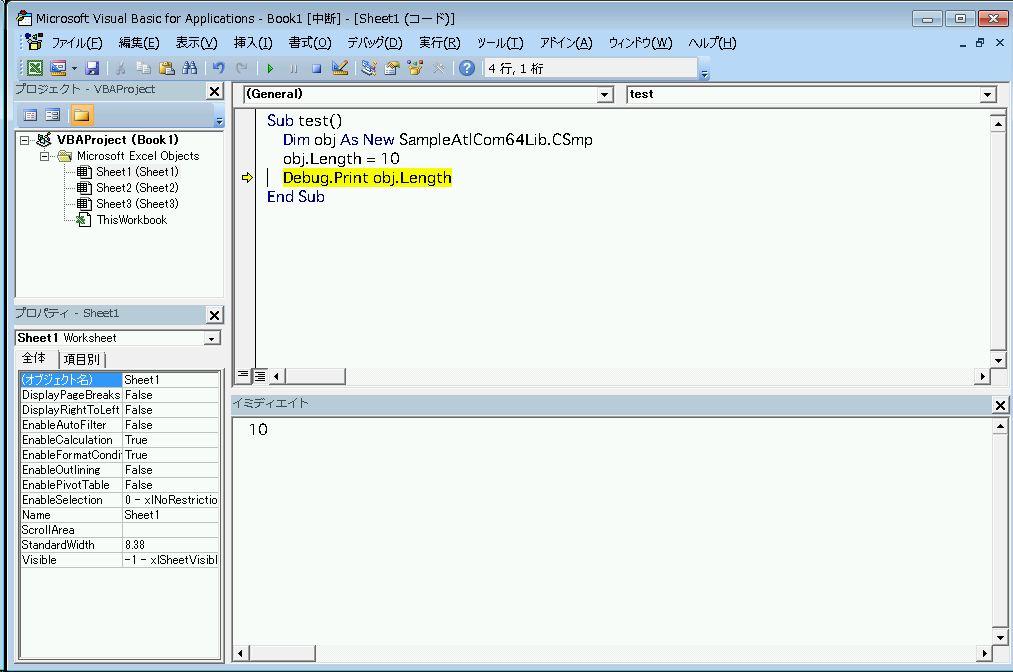
こんなコードを書いて実行をすると、
Sub test()
' 初期化
Dim obj As New ExQuery.Query
obj.SetApplication Excel.Application
obj.Cell("A1").Text = "最初"
obj.Cell("A2:B10").Text = "埋める"
' 背景色を赤に設定
obj.Cell("A2").CSS("background-color") = RGB(255, 0, 0)
' 文字色と背景色を変える
Dim v As Long
v = RGB(0, 0, 255)
With obj.Cell("A3")
'.CSS("color") = RGB(255, 255, 255)
.CSS("color") = "#FF00000"
.CSS("background-color") = RGB(0, 0, 255)
End With
End Sub
以下のように Excel のシートを操作できます。
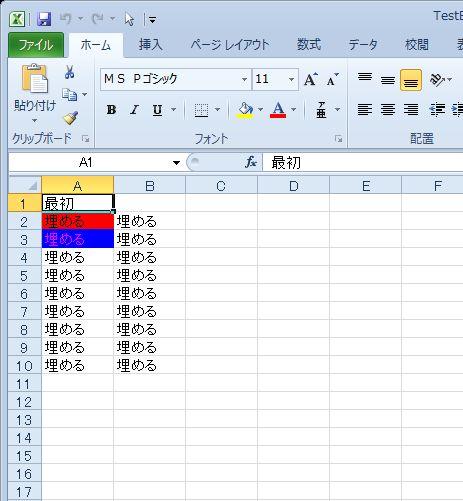
先行きは表を簡単に作るとか、検索を楽にするとかを実装したいですね。
■C#のソースコード
面倒なので全文を晒しておきます。プロジェクトを作る時に、
- Visual Studio 2010 は管理者モードで起動する
- Microsoft Excel を参照設定する。
- プロジェクトのプロパティで「COM 相互運用機能の登録」をチェックする
を忘れずに。管理者モードのほうは、COM をレジストリに登録するの必要です。
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using Excel = Microsoft.Office.Interop.Excel;
using System.Runtime.InteropServices;
namespace Moonmile.ExQuery
{
[ClassInterfaceAttribute(ClassInterfaceType.AutoDual)]
[ComVisible(true)]
public class Query
{
private Excel.Application _app;
private Excel.Workbook _book;
private Excel.Worksheet _sheet;
private Excel.Range _sel;
///
/// Initalize Excel.Application object
///
public Excel.Application Application
{
get { return _app; }
set
{
_app = value;
_book = _app.ActiveWorkbook;
_sheet = _app.ActiveSheet;
_sel = _app.Selection;
}
}
public void SetApplication(Excel.Application app)
{
this.Application = app;
}
public Excel.Workbook Book
{
get { return _book; }
set
{
_book = value;
_sheet = _app.ActiveSheet;
_sel = _app.Selection;
}
}
public Excel.Worksheet Sheet
{
get { return _sheet; }
set {
_sheet = value;
_sel = _app.Selection;
}
}
public Excel.Range Selection
{
get { return _sel; }
set { _sel = value; }
}
///
/// default constructor
///
public Query() { }
public ExRange Cell( object row1, object col1 = null, object row2 = null, object col2 = null )
{
if (row1 == null)
return new ExRange();
var s = row1 as string;
if (s != null)
return Cell(row1.ToString());
if (row2 == null)
return Cell(int.Parse(row1.ToString()), int.Parse(col1.ToString()));
return Cell(
int.Parse(row1.ToString()), int.Parse(col1.ToString()),
int.Parse(row2.ToString()), int.Parse(col2.ToString()));
}
///
/// pattern:
/// Cell("A1")
/// Cell("A1:B10")
/// Cell("#id")
///
///
///
protected ExRange Cell(string s)
{
Excel.Range rg;
if (s.StartsWith("#"))
rg = _sheet.get_Range(s.Substring(1));
else if (s.StartsWith("."))
rg = _sheet.get_Range(s.Substring(1));
else
rg = _sheet.get_Range(s);
return new ExRange(rg);
}
///
/// pattern:
/// Cell(1,2)
///
///
///
///
protected ExRange Cell(int row, int col)
{
if (_sheet == null)
return new ExRange();
var rg = _sheet.Cells[row, col];
return new ExRange(rg);
}
///
/// pattern:
/// Cell(1,2,3,4)
///
///
///
///
///
///
protected ExRange Cell(int row1, int col1, int row2, int col2)
{
if (_sheet == null)
return new ExRange();
var rg = _sheet.Range[
_sheet.Cells[row1, col1], _sheet.Cells[row2, col2]];
return new ExRange(rg);
}
}
[ClassInterfaceAttribute(ClassInterfaceType.AutoDual)]
[ComVisible(true)]
public class ExRange
{
private Excel.Range _range ;
private CSS _css;
protected internal ExRange() { }
public ExRange(Excel.Range rg)
{
_range = rg;
_css = new CSS(_range);
}
public string Text
{
get { return _range.Value; }
set { _range.Value = value; }
}
public CSS css
{
get { return _css; }
}
}
[ClassInterfaceAttribute(ClassInterfaceType.AutoDual)]
[ComVisible(true)]
public class CSS
{
private Excel.Range _range;
protected internal CSS() { }
protected internal CSS(Excel.Range rg)
{
_range = rg;
}
public string this[string key]
{
get
{
switch (key.ToLower())
{
case "color":
return _range.Font.Color;
case "background-color":
return _range.Interior.Color;
}
return "0";
}
set
{
if (value.StartsWith("#"))
{
int r = Convert.ToInt32(value.Substring(1, 2), 16);
int g = Convert.ToInt32(value.Substring(1, 4), 16);
int b = Convert.ToInt32(value.Substring(1, 6), 16);
value = (r + g * 0x100 + b * 0x10000).ToString();
}
switch (key.ToLower())
{
case "color":
_range.Font.Color = value;
break;
case "background-color":
_range.Interior.Color = value;
break;
}
}
}
}
}
■Excel VBA から使う COM 作成のコツ
いくつか引っ掛かるところを書き下しておきます。
Excel VBA の「integer」は、C# の Int64/short Int16/short にあたります。16ビットの数値なんですね。なので、COM のメソッドの引数は、short にしておく必要があります。そうしないと、Excel VBA から COM に値を引き渡すときにエラーになります。
Cell メソッドの引数で object を使っていますが、VBA の Variant は、object でしか取れないようです。
最初は、Cell メソッドを多重定義して公開していたのですが、VBA 側で、Cell/Cell_2/Cell_3 と名前を変えられてしまうので、デフォルト値を付けて同じ名前で実行できるように変えました。
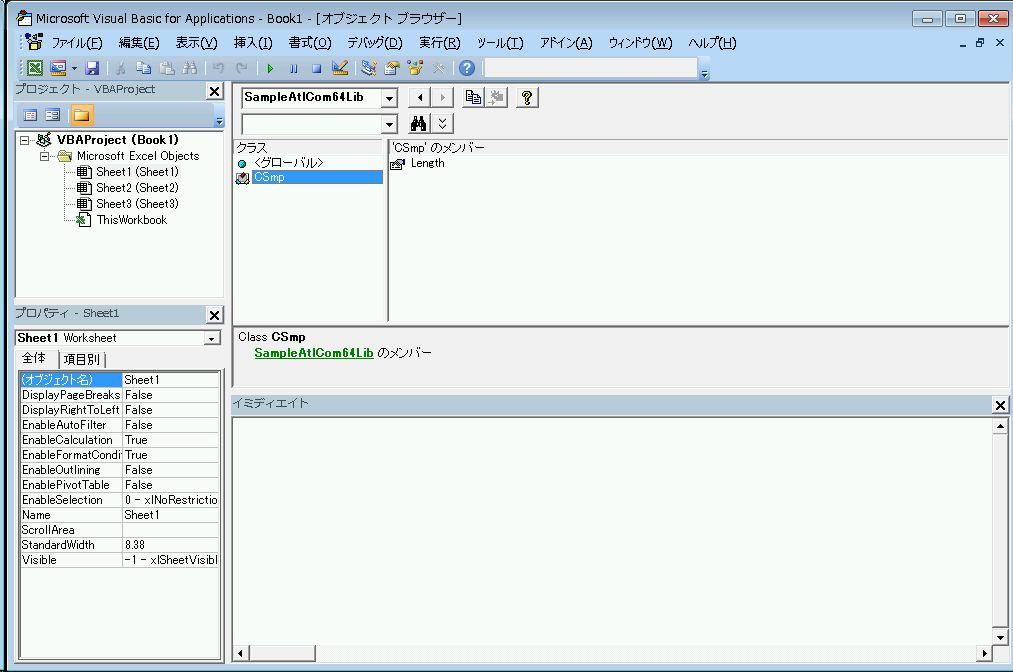
Excel VBA のインテリセンスを利用するために [ClassInterfaceAttribute(ClassInterfaceType.AutoDual)] という属性をつけます。実は AutoDual を使うと、COM 側のインターフェースが変わる(メソッドの順番が変わるなど)たびに、VB 側のビルドが必要になるのですが、今回は Excel VBA を対象にするのでこのまま使っています。Excel VBA の場合はインタープリタ的に COM を読み込むので、タイプライブラリを起動時に読み込んでくれるためです。このあたりは、以下のサイトを参考にしてください。
.NETコンポーネントをVB6から使用するための方法
http://www.sev.or.jp/ijupiter/world/dc_interrop/dotnet_com_interrop.html
Visual Basic 6.0 から Visual Basic .NET または Visual Basic 2005 アセンブリを呼び出す方法
http://support.microsoft.com/default.aspx?scid=kb;ja;817248
ClassInterfaceType 列挙体 (System.Runtime.InteropServices)
http://msdn.microsoft.com/ja-jp/library/system.runtime.interopservices.classinterfacetype(v=vs.110).aspx
■今後の予定?
css メソッドをちまちまと実装して、Excel VBA の複雑な UI を楽にアクセスできるようになると良いかも。
あと、C# で書いたので内部的に LINQ が使えますよね。Where/Select メソッド等を適当に公開してやれば、Excel VBA で LINQ を使っている感じに、なるかもしれない。とかとか。