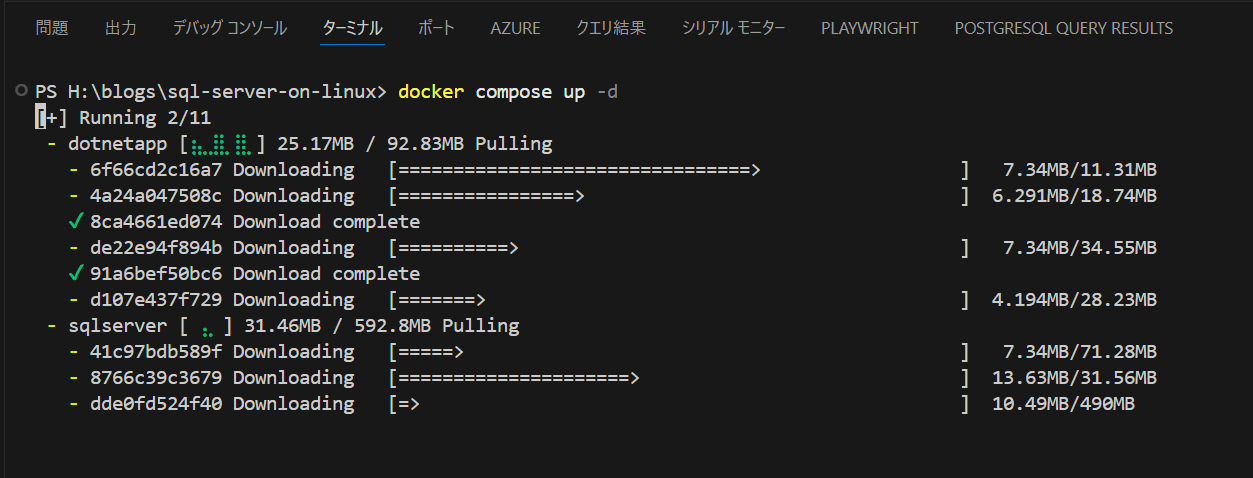
定期的に OneDrive dis が発生する X 界隈ではありますが、まあ、確かに「OneDrive の同期」については最初は切っておく、ってのがベターです。というのも Dropbox のようにバックアップ環境としてファイルを置いておく感覚で OneDrive にファイルを置くと痛い目にあいます。
Dropbox ではファイルのバックアップなのでクラウド環境にファイルを退避すれば、ローカル PC にあるファイルを消しても構いません。ファイルはクラウド上に残ります。これは感覚的にあっています。倉庫に物を置くようなイメージですからね。
しかし、OneDrive の場合は同じことをやるとクラウド上のファイルも消えてしまいます。一般的なバックアップシステムのような振りをしていますが、実は「複数の PC で同期」するのが主目的なので、削除した場合はバックアップ…じゃなくてクラウド上のファイルも消えてしまいます。さらに言えば、同じアカウントで入っている別の PC からも消え去ってしまいます。これは一大事。ってのが、何度も繰り返される OneDrive dis の本質でしょう。
OneDrive はクラウドのバックアップじゃなくて、同期システムなんだ、と何度言っても無理なので、ここは潔く「OneDriveを使用しない」あるいは「部分的にしか使用しない」に留めておきます。ちなみに、私は「部分的にしか使用しない」ことにしています。
OneDrive を使わないようにする。
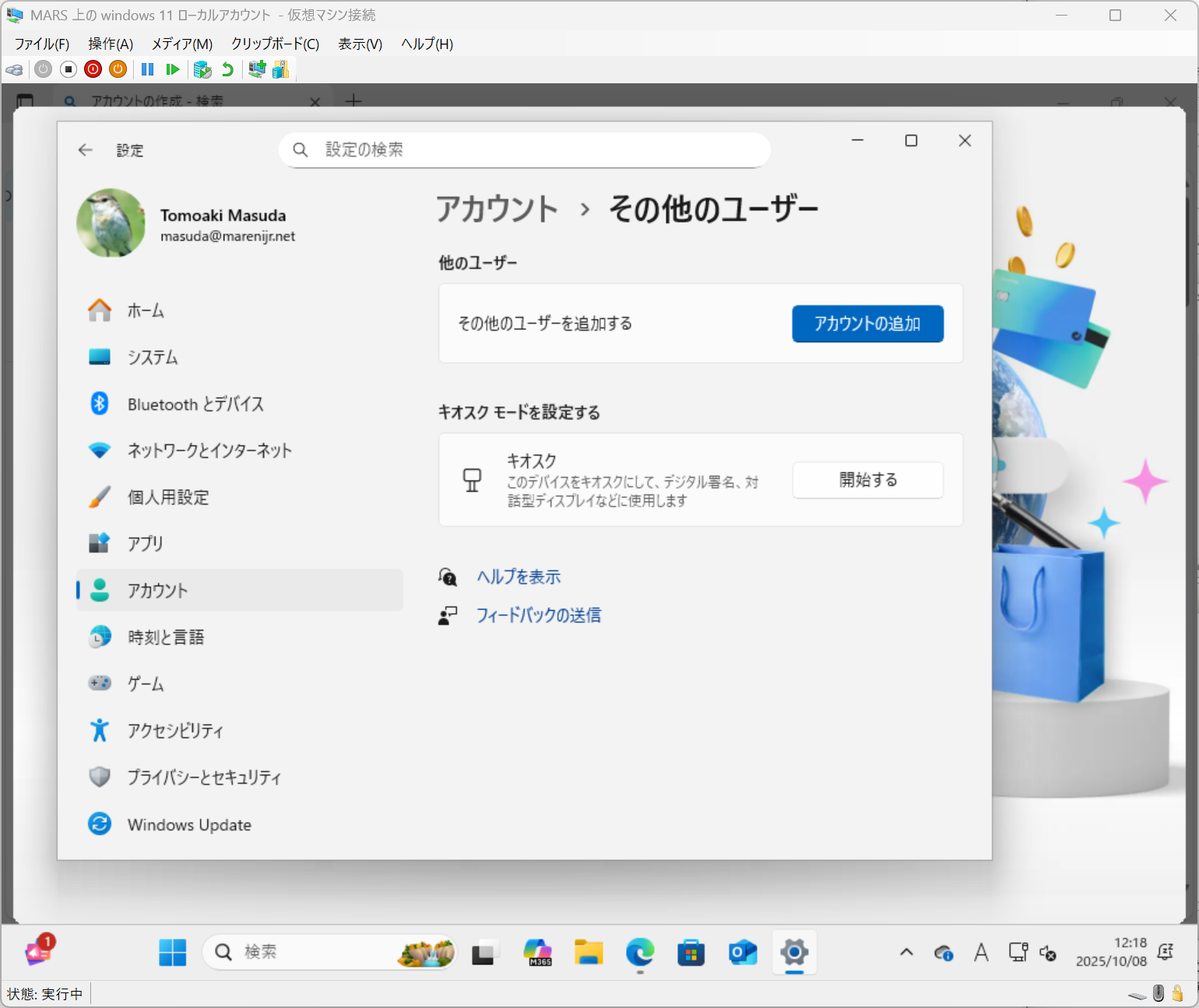
いったん、OneDrive を使わずに同期をしないようにしてしまいます。おそらく Windows 11 をいれるときに Microsoft アカウントを入れるのが通常なので、ほぼ無条件で OneDrive でリンクされてしまいます。PC が 1台だったらいいのですが、複数台(ノート PC と在宅 PC とか)を使う場合には、いったん OneDrive を1台だけに絞って、他の PC では使わないようにしたほうが間違いが少ないです。
Windows 11 のタスクバーから、クラウドアイコンを右クリック
歯車の設定アイコンをクリック
メニューから「設定」を選択
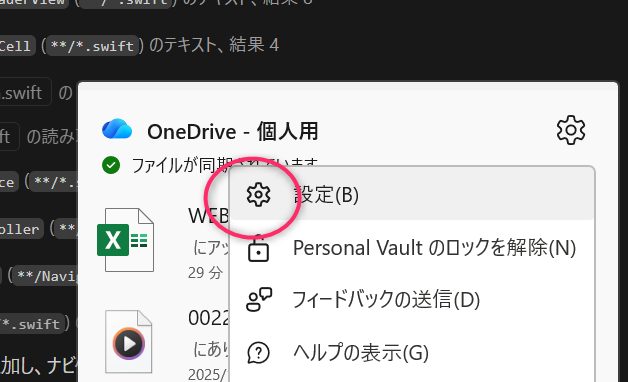
OneDrive 設定から「アカウント」を選択して、「この PC からリンクを削除する」を選びます。
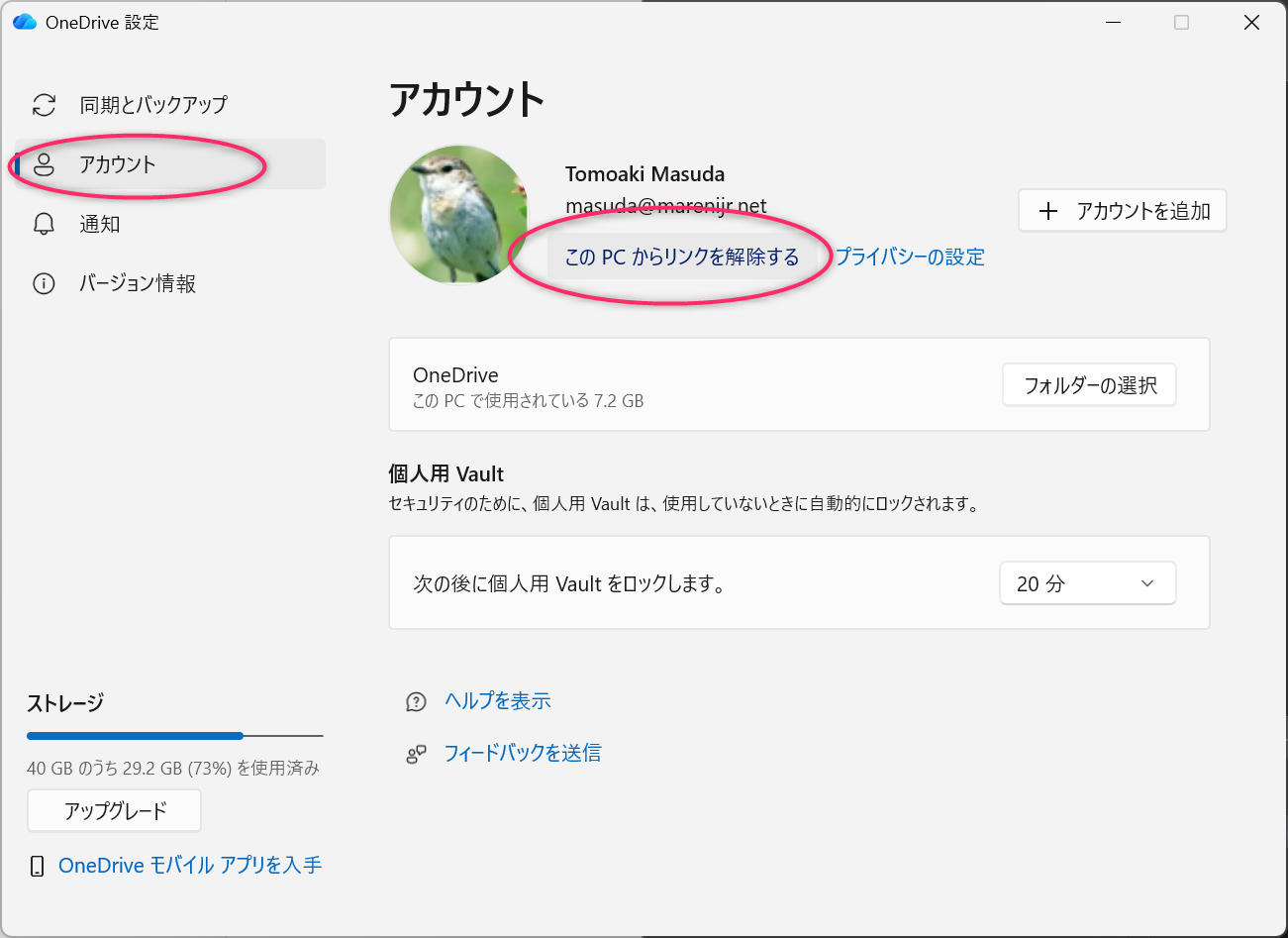
たとえば、持ち運びをするノート PC とか、一時的に Windows アカウントが必要だったときの業務 PC では「この PC からリンクを削除する」を選択して外しておきます。
ちなみに、バックアップのつもりで OneDrive を使う場合には、
- デスクトップ PC では、上記のように PC からリンクの解除をしておく。
- ブラウザで onedrive.com を使う
としておくのが安全です。ちょっと面倒ですが、Word/Excel ファイルを操作するときはブラウザ上で、画像ファイルなどはいちいちアップロード/ダウンロードとしておきます。こうすると、PC とクラウド上がうまく分離されるので、Dropbox と同じ形で使えます。
部分的に OneDrive で同期させる
たまに OneDrive の同期が失敗するのが難点ではありますが、部分的に同期させるのがお勧めです(これは、Documents 配下を同期させても失敗は良く起こるので、部分同期でもドキュメントフォルダ同期でも変わりません)。
さきほどの OneDrive の設定から「フォルダーの選択」ボタンをクリックします。
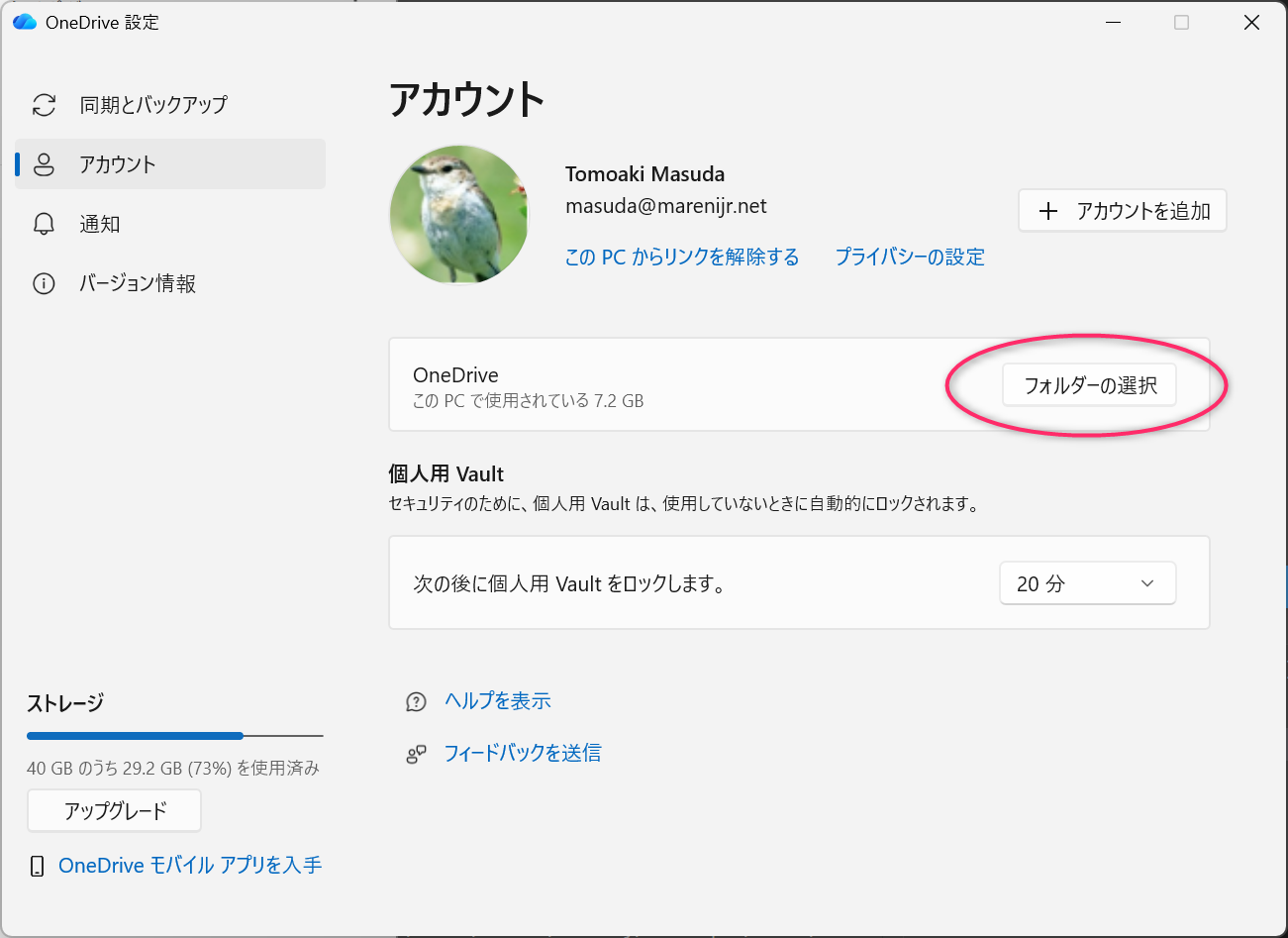
初期設定は忘れてしまったのですが、おそらくこんな感じで「Desktop」「Pictures」「ドキュメント」にチェックが入っているはずです。
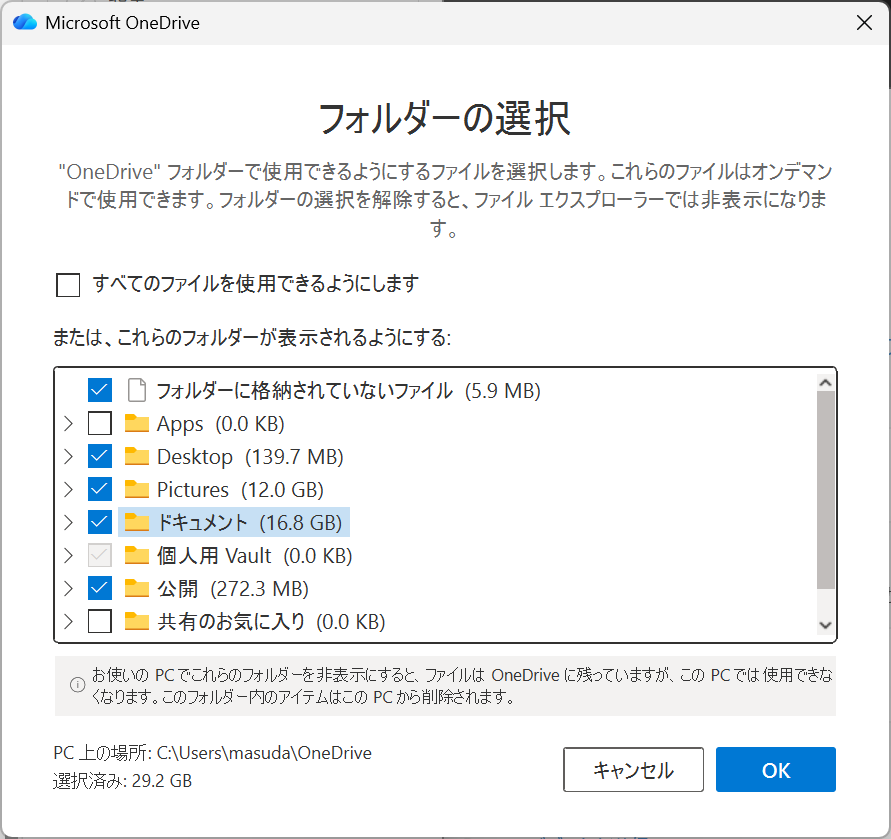
よく、OneDrive に騙されるのは、デスクトップを同期に含んだ状態であって、ノート PC のデスクトップからファイルを削除したら、業務 PC のほうからも削除されてしまった。という例です。他にも、ノート PC とデスクトップ PC の両方で別々で作業していたとか、片方でファイルを別のフォルダーに移動したとか、そのようなところで衝突(コンフリクト)が起こって、OneDrive の同期ができなくなってしまいます。最近は、OneDrive が勝手にファイル名を別のものにする機能が加わったので、だいぶんマシにはなったのですが、それでもファイル名がよくわからなくなってどちらが最新なのか混乱してしまいます。
まあ、同時にファイルを弄るのが不味いといえば不味いのですが、ブラウザ上で編集しようとすると、編集できてしまうのが問題ではありますね。
私の場合では、
- Desktop は同期させないので、チェックを外す
- Picture を同期させないので、チェックを外す
- ドキュメントを同期させないように、いったんチェックを外す
すべてのチェックを外したうえで、同期させておきたいフォルダー(下記では、「仕事」と「Blog」)にチェックを入れます。
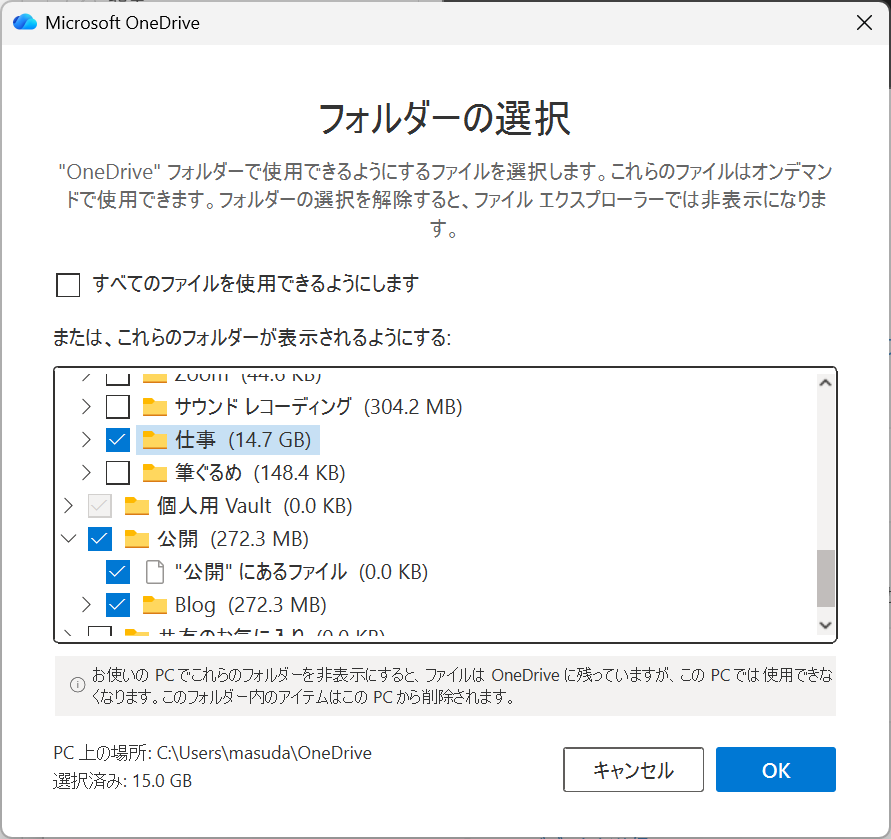
仕事フォルダは “c:\Users\masuda\OneDrive\ドキュメント\仕事 にフォルダーを作っています。個人用のドキュメントフォルダーとは異なる位置にあります。他にも OneDrive\ドキュメント配下に「公開」フォルダーを作って、その中に Blog を作って、これを同期する形にします。
これによって同期されるフォルダーが「仕事」と「Blog」のみに限られます。
これは新しい PC に Windows 11 をインストールするたびに、やらないといけないのが面倒ではあるのですが、このように同期するフォルダーを設定してしまうほうが制御が楽です。
当然、このフォルダーはバックアップとしてではなく、同期としてつかうので複数台の PC から同期されること(削除や移動など)を意識してつかいます。バックアップとして使いたい場合はあらためて「OneDrive/ドキュメント/バックアップ」のようなフォルダーを作っておけばよいです。
特に、初期値では OneDrive の容量が 5 GB しかないので、ドキュメント全体を同期させてしまうとパンクしてしまいがちです。そのために OneDrive の増設を考えさせられることになるので、ちょっとこれは無駄でしょう。私の場合、以前 40 GB までの無料アップグレードキャンペーンがあったので、最大容量が 40GB になっているので大丈夫なんですが。Microsoft 365 Personal とかを契約したときには、1 TB になるので、契約している場合はいいのですが、素の Windows 11 の場合は OneDrive は使わない方針にして、ブラウザ経由のみで使うのがお勧めです。
OneDrive のその他の使い方
私の場合、OneDrive の仕事フォルダーは各プロジェクト(執筆など)の作業場所にしてあって、出版社との原稿のやり取りや、お客さんとの課題管理表のやりとりに使っています。ぷプロジェクト用のフォルダー移行を相手と共有するようにしてあるので、ファイルをメール等に添付する必要がありません。
会社の場合 OneDrive にセキュリティリスクの高いファイル(設計書、契約書など)を置くのはどうかと思うのですが、さすがに契約書まわりは置かないけれど設計書まわりは置いてあります。こうするとお客とのやり取りが手早いのです。これは Google Claude でもできるので、それでもいいのですが、私の場合は OneDrive で。
補足
Documents フォルダーを同期したままにしておくと、ファイルの紛失もそうなのですが、Visual Studio などで作成した中間ファイルなどが置きっぱなしになっていて、それを同期させて OneDrive の同期が死ぬことになります。ちらほらと Adoble のテンポラリファイルが溢れている例もあるので注意が必要です。
これ、素の Windows 11 の時は容量が 5 GB 程度なので、中間ファイル(Node.js や Python のライブラリも含む)が多くなると溢れてきて気付くのですが、Microsoft 365 を契約していて 1TB に拡張されていると気づくのが遅くなります。ノート PC で同期が走っていてどうもおかしいな?と思ったら OneDrive のでかい同期か Windows Update がバックグラウンドで走っていることが多いです。