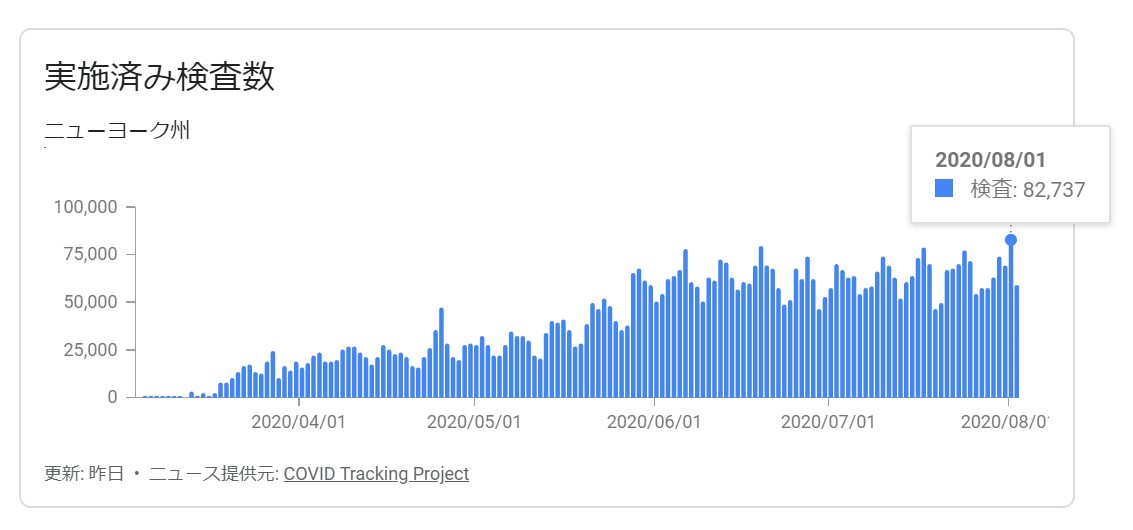
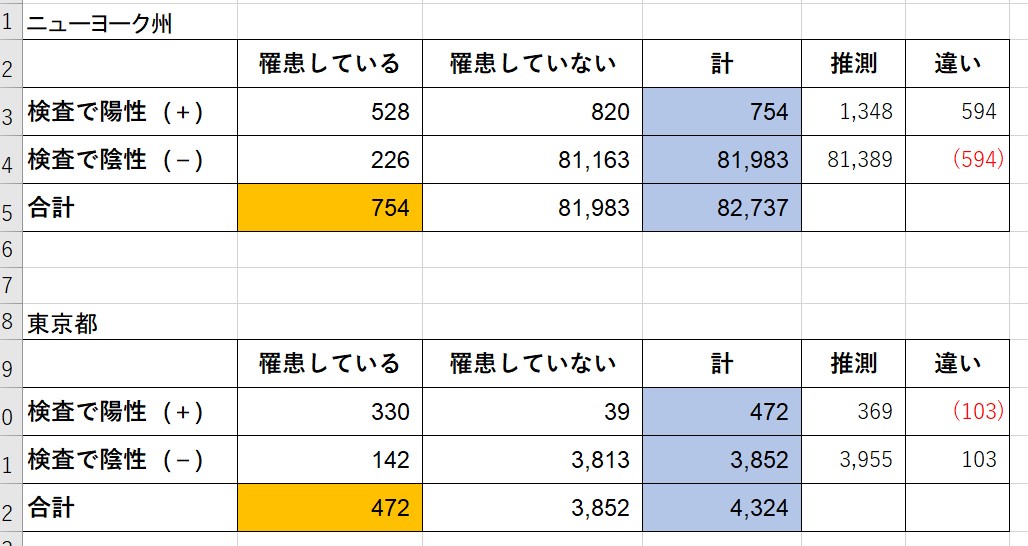
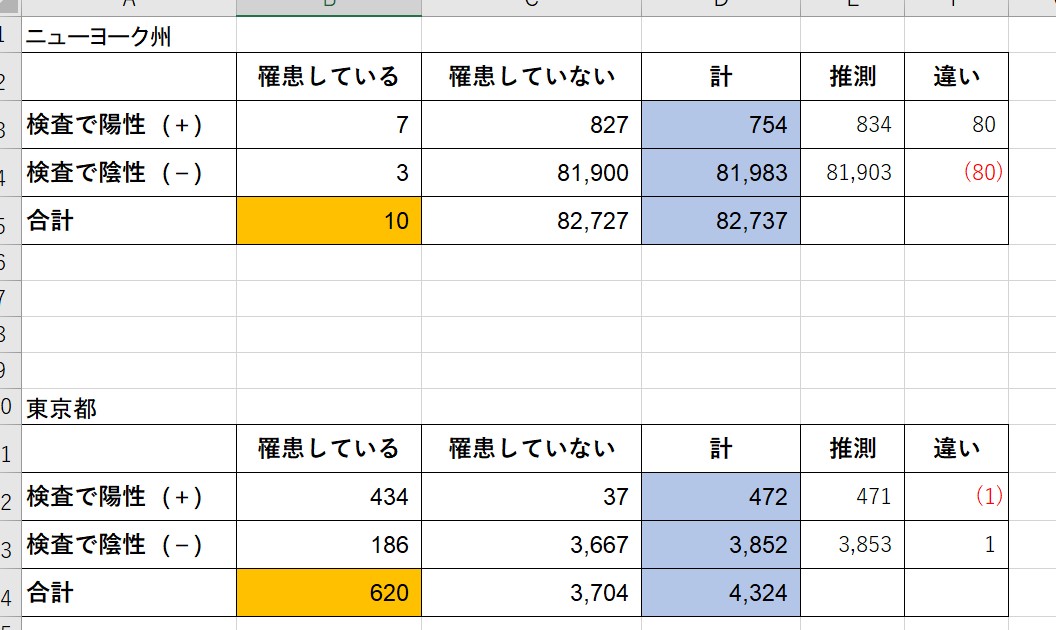
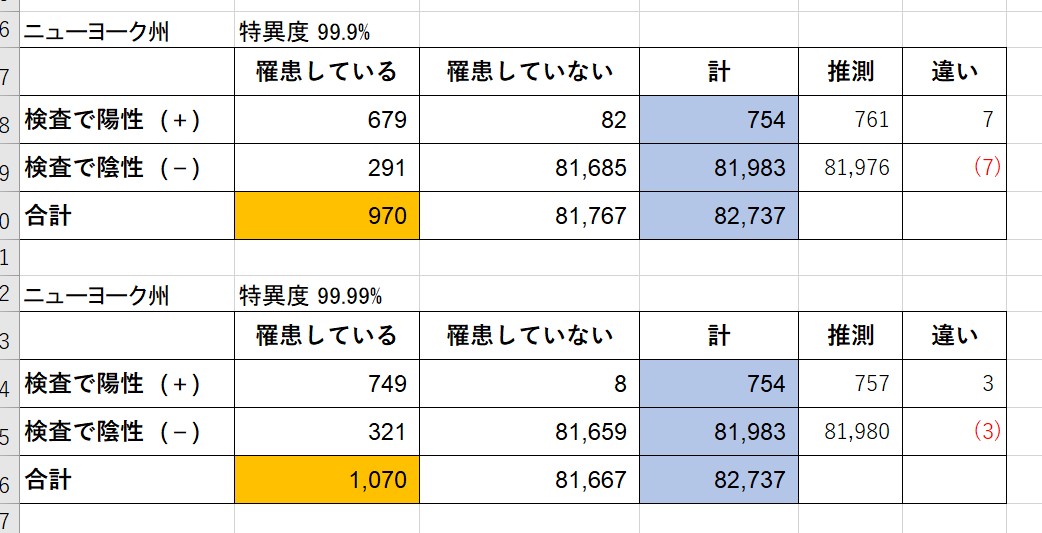
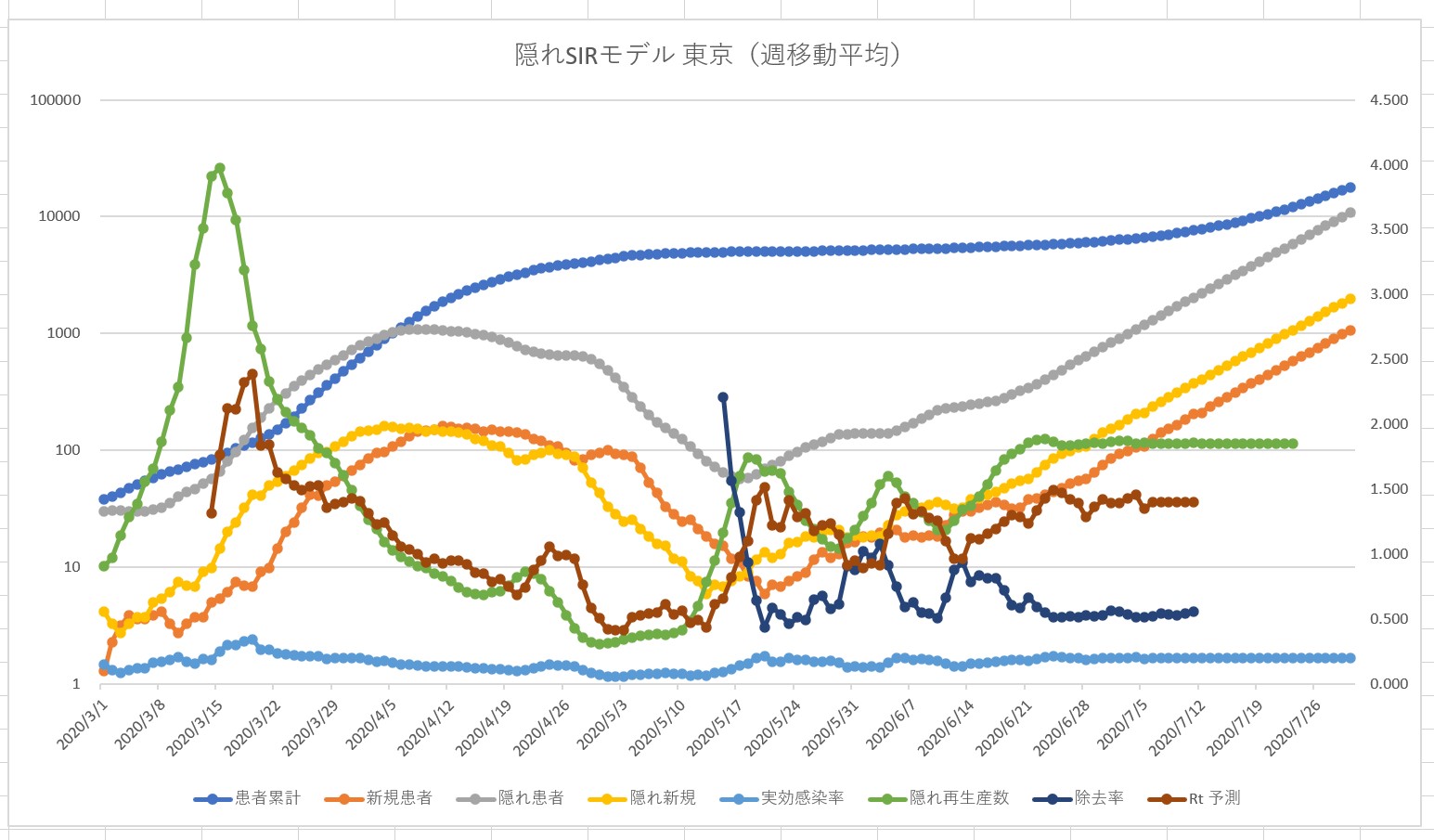
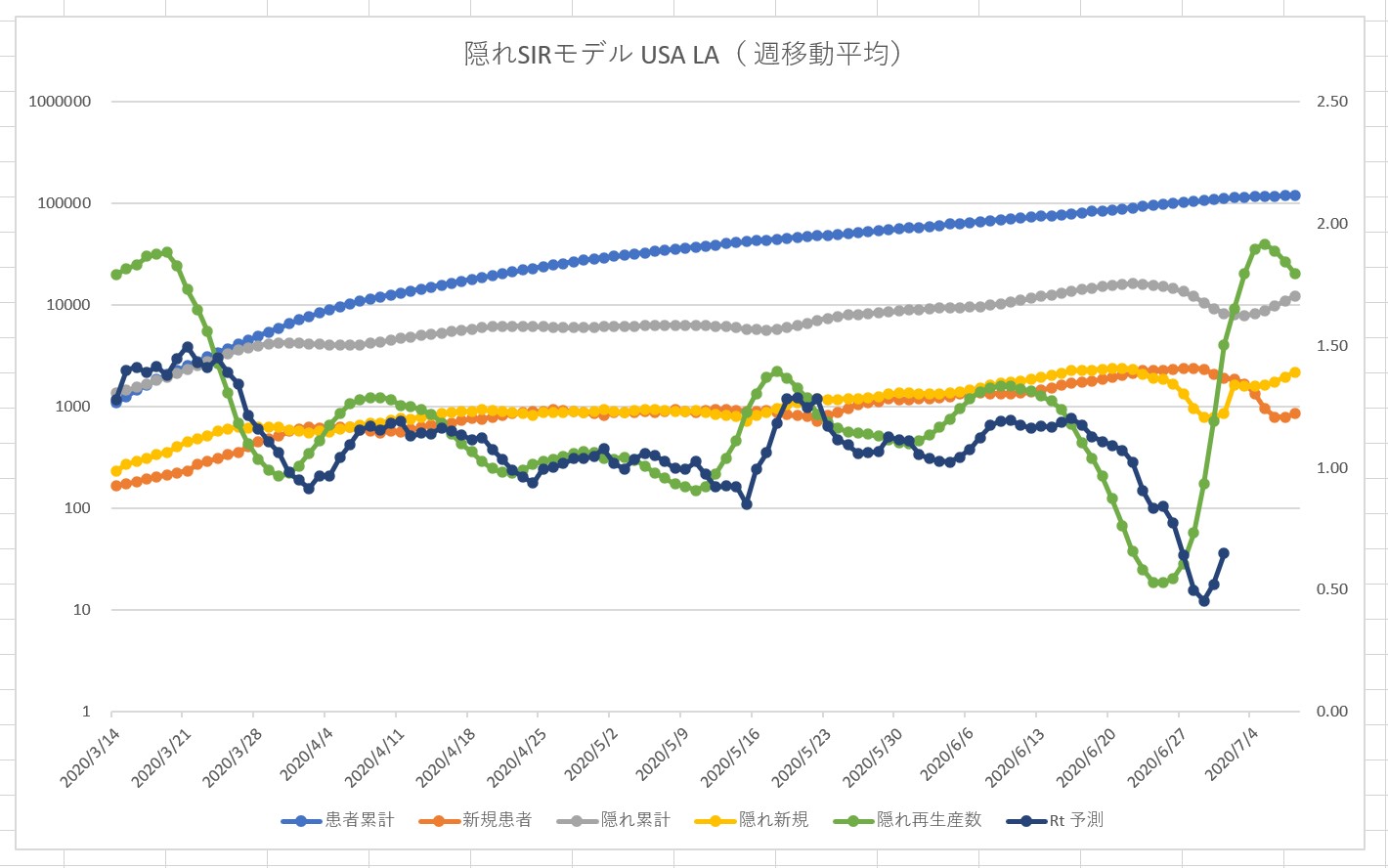
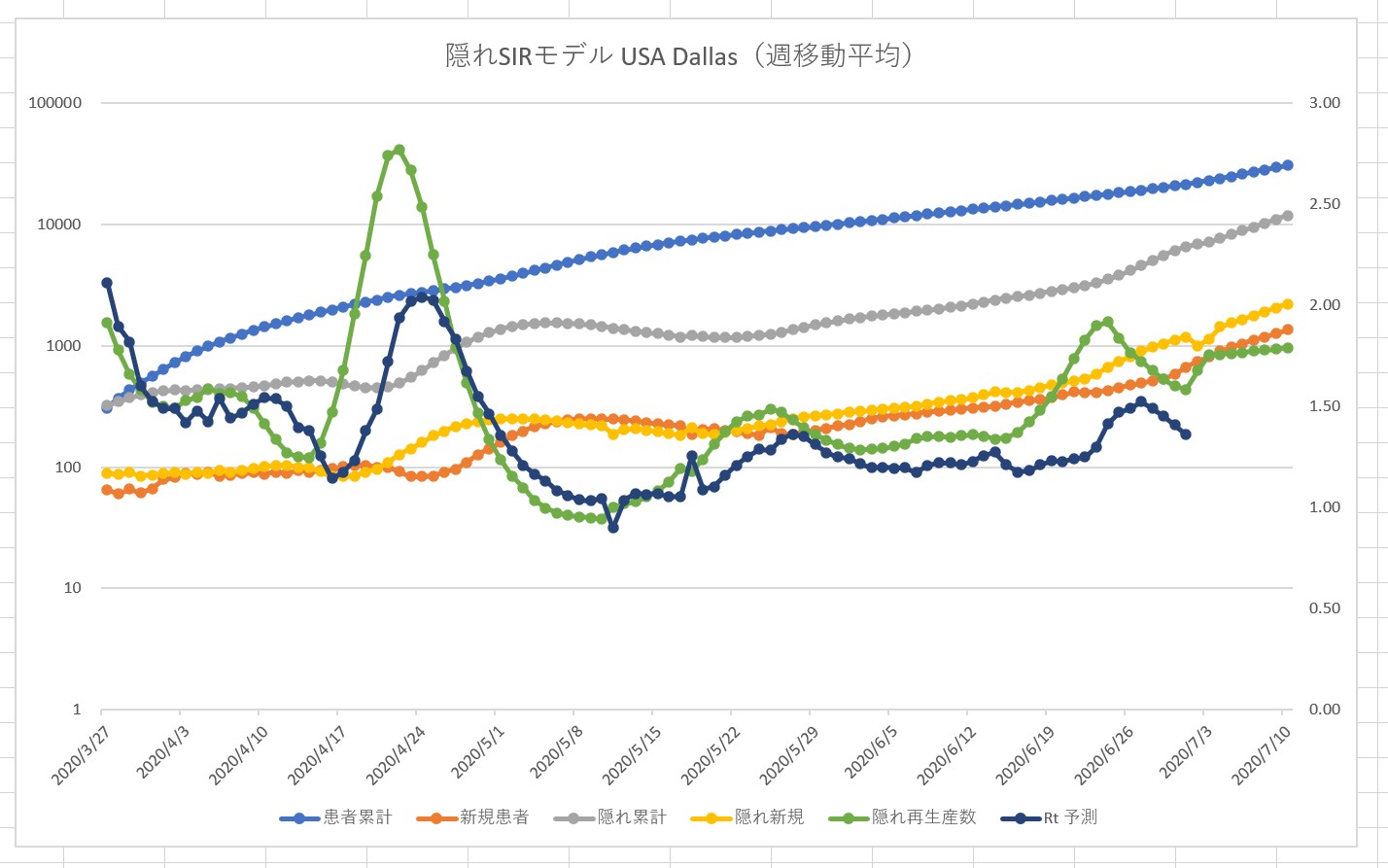
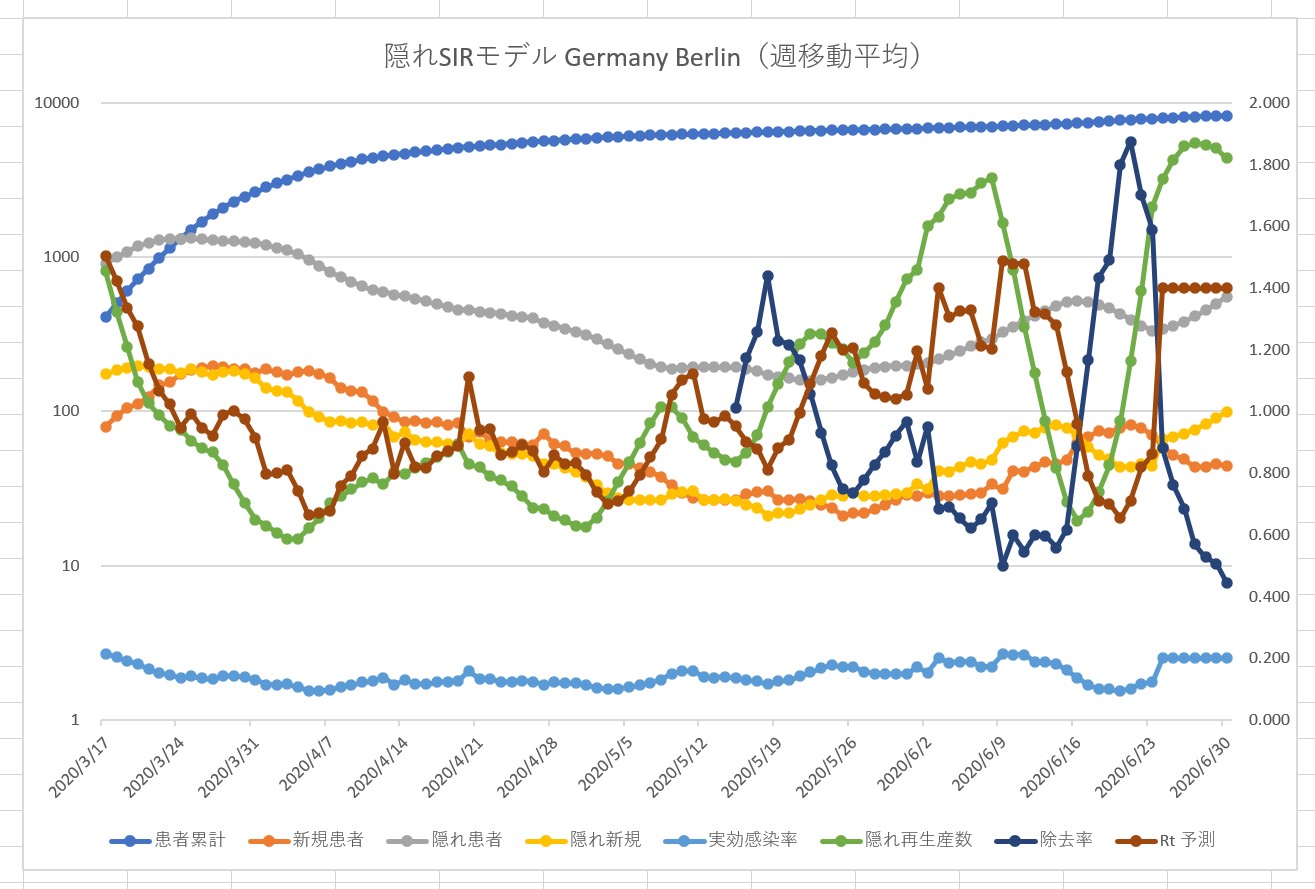
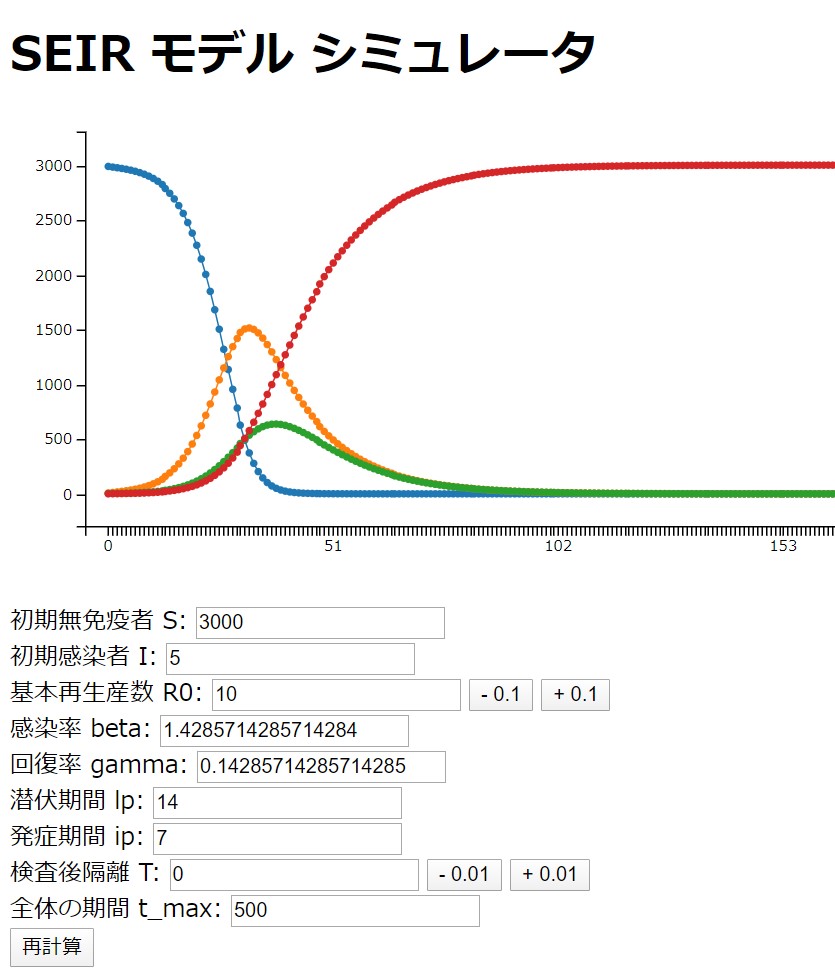
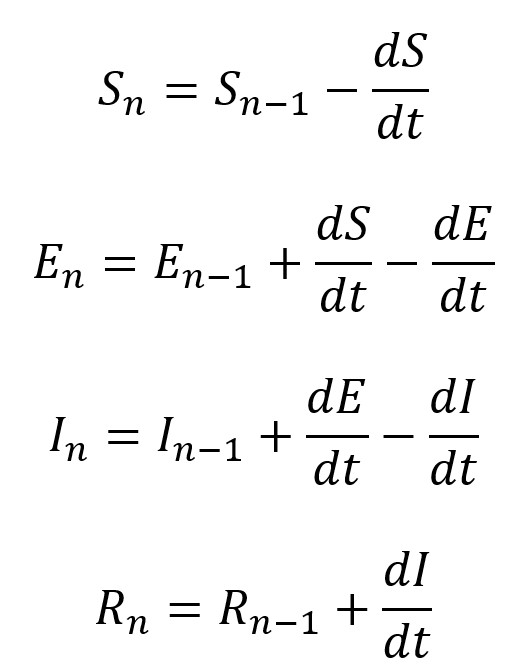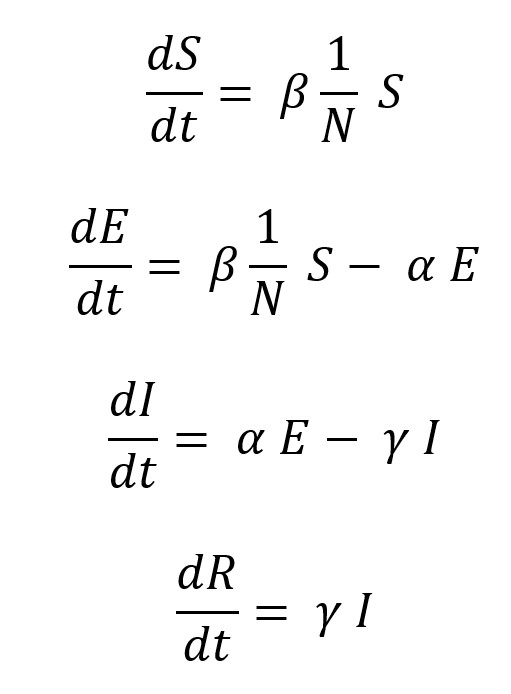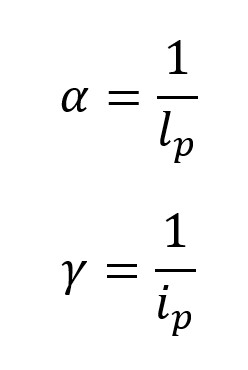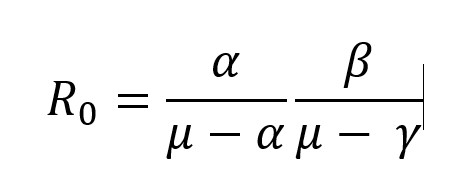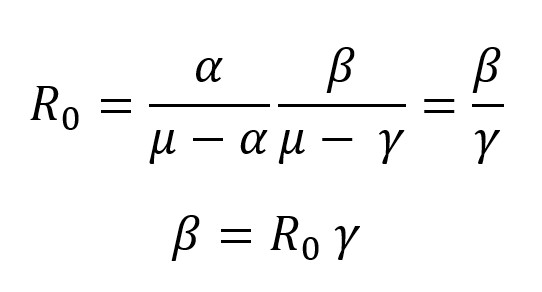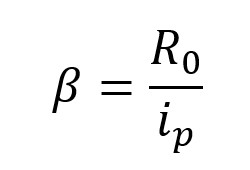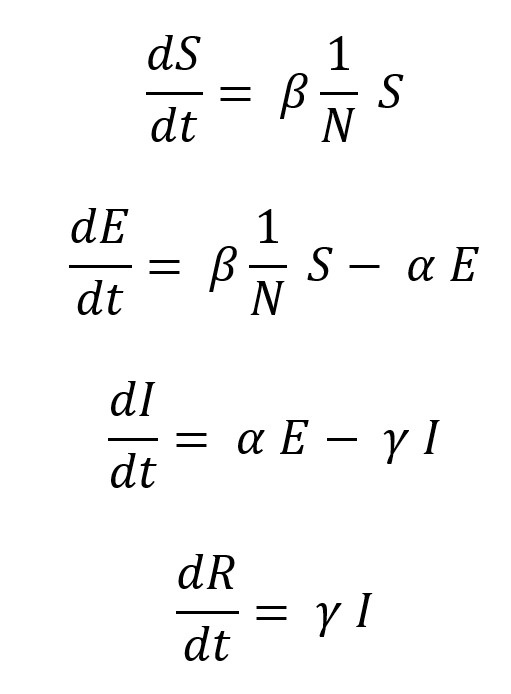Vue.js に慣れるため、という名目で Covid 19 の観測サイトを作成してみます。
実のところ、Covid 19 の観測サイトは既にたくさんあります。
ただ、データ集計をして表示するだけならば色々あるのですが、
- 観測データを動的に比較する
- 観測データを使って、何かシミュレーションする
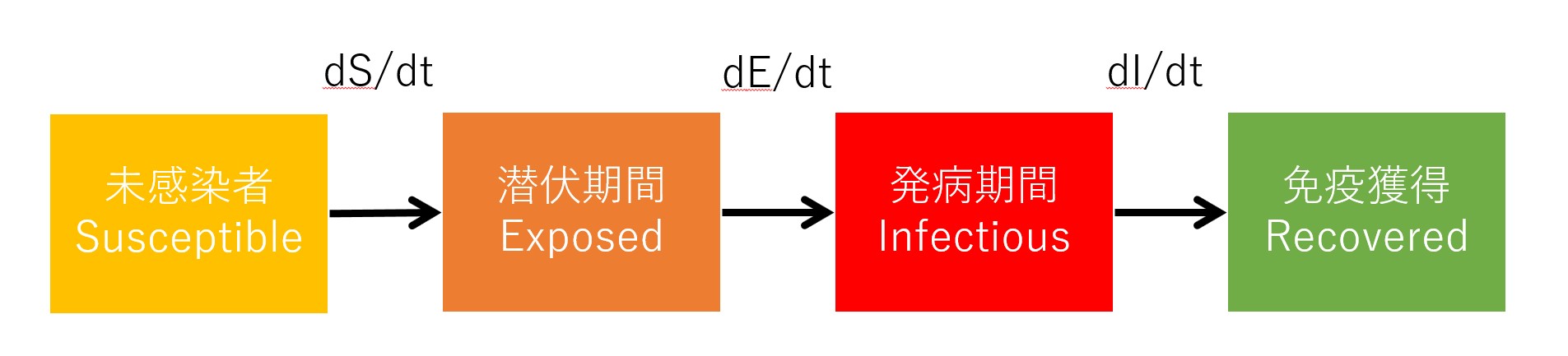
ことができません。以前 プログラマにもわかる SEIR モデルシミュレーション – Qiita ということで、SEIR モデルで Excel を使って予測値を出していたのですが、これは毎日手作業でやっていました。データ整形がちょっと面倒だったのと、予測 Rt 値を恣意的に(数日の平均など)を使っていくつかシミュレーションしていたのです。
で、先日 NHK サイトで二次利用可能なオープンデータとして使えることが分かったので、これを使って自動化してみます。
CSV 形式を加工する
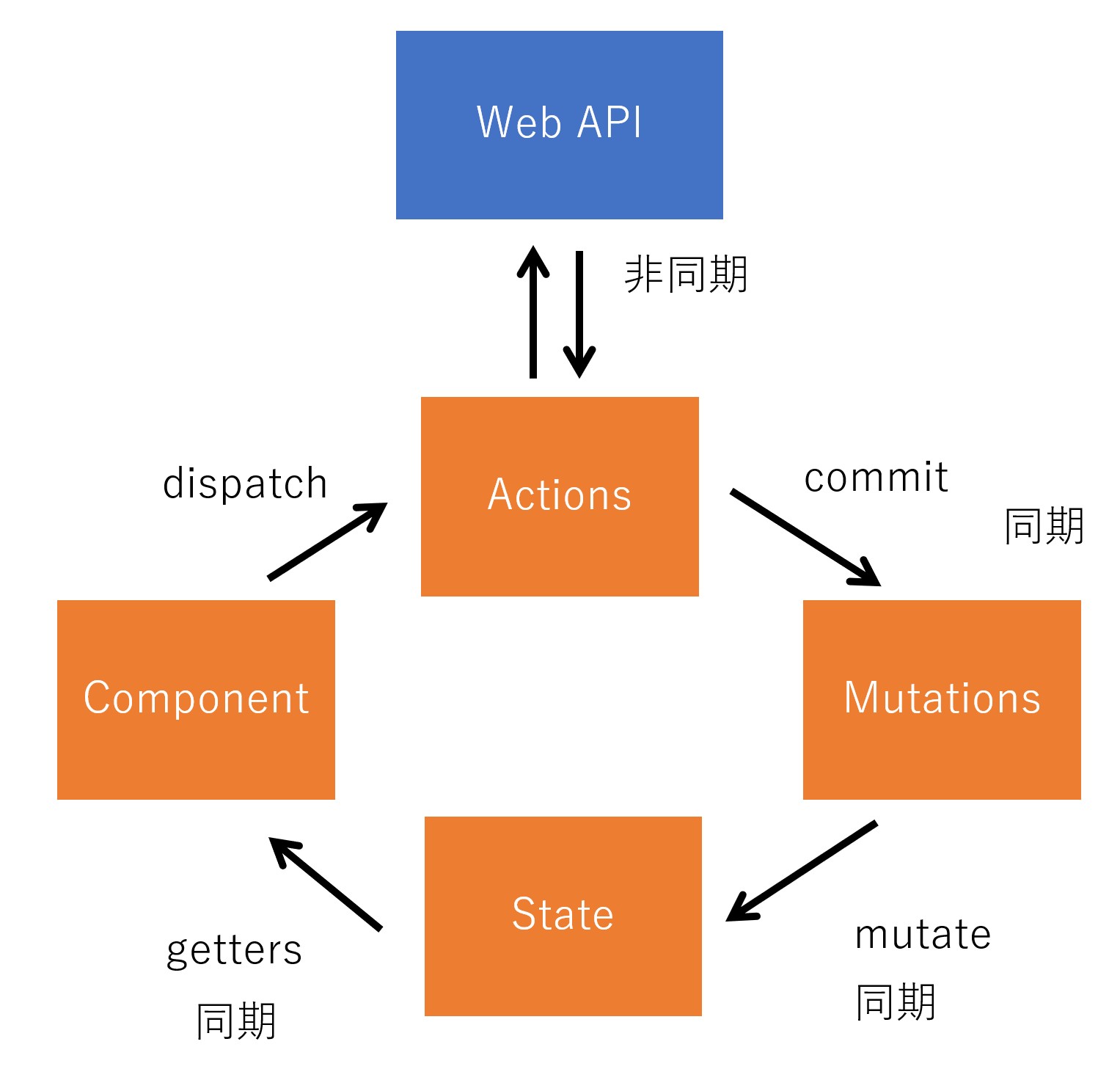
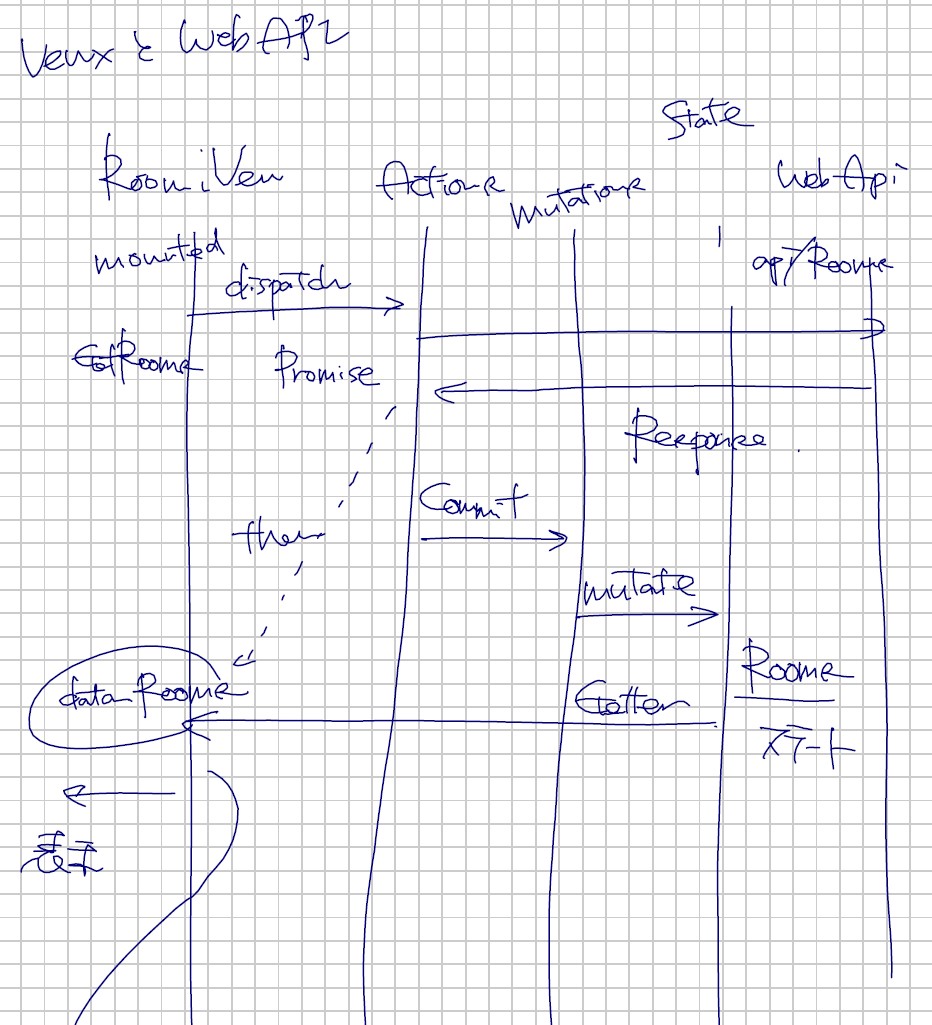
Vue.js(JavaScript) で NHK の CSV 形式のデータをパースしてもよいのですが、既に JSON 形式になっていたほうが楽なので、中間の Web API を作成します。
Azure Function のタイマートリガー
タイマートリガーで1時間単位でCSV形式のファイルをダウンロードします。
Covid 19 のデータは1日単位でしか更新されないので、もっとスパンが長くてもよいのですが、何時頃公開されるか判らないので1時間単位。
プログラムを最初に書いたときは、いちいちCSV形式のデータをダウンロードしていたのですが、結構遅いので、ダウンロードして JSON 形式にパースしたら BLOB に保存しています。
[FunctionName("NHKCovidTimer")]
public static async Task RunTimer([TimerTrigger("0 5 * * * *")] TimerInfo myTimer,
[Blob("covid/japan.json", FileAccess.Write)] Stream jsonfile,
ILogger log)
{
log.LogInformation("called NHKCovidTimer");
var url = "https://www3.nhk.or.jp/n-data/opendata/coronavirus/nhk_news_covid19_prefectures_daily_data.csv";
var cl = new HttpClient();
// 1行ずつ読み込み JSON 形式に変換
var res = await cl.GetAsync(url);
var data = new List<Covid>();
using (var st = new StreamReader(await res.Content.ReadAsStreamAsync()))
{
// タイトルは読み飛ばし
st.ReadLine();
while (true)
{
string line = st.ReadLine();
if (string.IsNullOrEmpty(line)) break;
var items = line.Split(",");
if (items.Length >= 7)
{
var it = new Covid()
{
Date = DateTime.Parse(items[0]),
LocationId = int.Parse(items[1]),
Location = items[2],
Cases = int.Parse(items[3]),
CasesTotal = int.Parse(items[3]),
Deaths = int.Parse(items[3]),
DeathsTotal = int.Parse(items[3]),
};
data.Add(it);
}
}
// ソートしておく
data = data.OrderBy(t => t.LocationId).ThenBy(t => t.Date).ToList();
// 週平均を計算
calcCasesAve(data);
// 週単位Rt値を計算
calcCasesRt(data);
// 週単位Rt平均値を計算
calcCasesRtAve(data);
}
var json = JsonConvert.SerializeObject(new { result = data });
var writer = new StreamWriter(jsonfile);
writer.Write(json);
writer.Close();
// return new OkObjectResult("save json " + DateTime.Now.ToString());
}
CSV 形式をパースするだけでなく、あらかじめ
- 週平均
- 週単位のRt値
- 週単位のRt平均値
などを計算しておきます。
保存する JSON の形式は Covid クラスに定義しています。大文字をわざわざ小文字に変えているのは、Vue.js の読み取りに合わせたためです。
public class Covid
{
[JsonProperty("date")]
public DateTime Date { get; set; }
[JsonProperty("locationId")]
public int LocationId { get; set; }
[JsonProperty("location")]
public string Location { get; set; }
[JsonProperty("cases")]
public int Cases { get; set; }
[JsonProperty("casesTotal")]
public int CasesTotal { get; set; }
[JsonProperty("deaths")]
public int Deaths { get; set; }
[JsonProperty("deathsTotal")]
public int DeathsTotal { get; set; }
[JsonProperty("casesAverage")]
public float CasesAverage { get; set; } // 週移動平均
[JsonProperty("casesRt")]
public float CasesRt { get; set; } // 週単位Rt値 = 続く1週間の感染者数平均 / 当日感染者数
[JsonProperty("casesRtAverage")]
public float CasesRtAverage { get; set; } // Rt値の週移動平均
}
HTTP トリガーを定義する
Web API は非常に簡単で、HttpTrigger で JSON ファイルの中味を返すだけです。データ量が 3M 程度になって大き目になってしまったので、後で期間や都道府県で絞れるように修正します。
[FunctionName("NHKCovid")]
public static async Task<IActionResult> RunRead(
[HttpTrigger(AuthorizationLevel.Anonymous, "get", "post", Route = null)] HttpRequest req,
[Blob("covid/japan.json", FileAccess.Read)] Stream jsonfile,
ILogger log)
{
log.LogInformation("called NHKCovid");
var sr = new StreamReader(jsonfile);
var json = await sr.ReadToEndAsync();
return new OkObjectResult(json);
}
Vue.js + Chart.js 側のコード
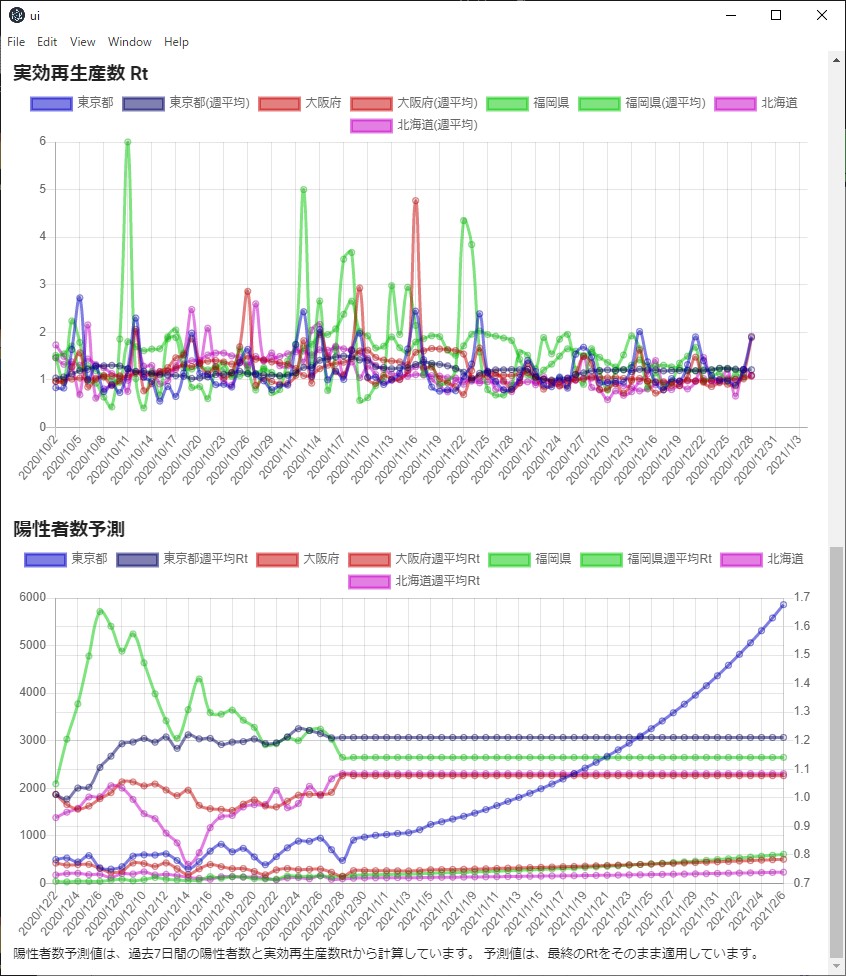
例えば、陽性者数のグラフは、Web APIの中から cases の値を羅列するだけの簡単なものです。
都道府県を複数選択できる(this.valueにある)ので、これの分だけ datasets を作ります。Chart.js は datasets の中に線グラフの色などが入っているので、その部分は二重に定義することになります。ここでは、最低限の定義しかしていません。
Chart.js は vue-chartjs を使っています。
/**
* 感染者数のグラフを作成
*/
makeCases(res,start_date,end_date,locations) {
var sdate = Date.parse(start_date)
var edate = Date.parse(end_date)
var datasets = []
var labels = []
var i = 0;
locations.forEach(location => {
var data = [];
var data2 = [];
labels = [];
res.data.result.forEach(el => {
if ( el.location == location ) {
var dt = Date.parse( el.date )
if ( sdate <= dt && dt <= edate ) {
dt = new Date(dt)
dt = dt.getFullYear() + "/" + (dt.getMonth()+1) + "/" + dt.getDate()
labels.push( dt )
data.push( el.cases )
data2.push( el.casesAverage )
}
}
});
var dataset =
{
label: location,
fill: false,
borderColor: i >= this.colors.length? "rgba(200,200,200,0.5)": this.colors[i].n,
data: data
}
var dataset2 =
{
label: location + "(週平均)",
fill: false,
borderColor: i >= this.colors.length? "rgba(100,100,100,0.5)": this.colors[i].ave,
data: data2
}
datasets.push( dataset )
datasets.push( dataset2 )
i++;
})
return { labels, datasets };
},
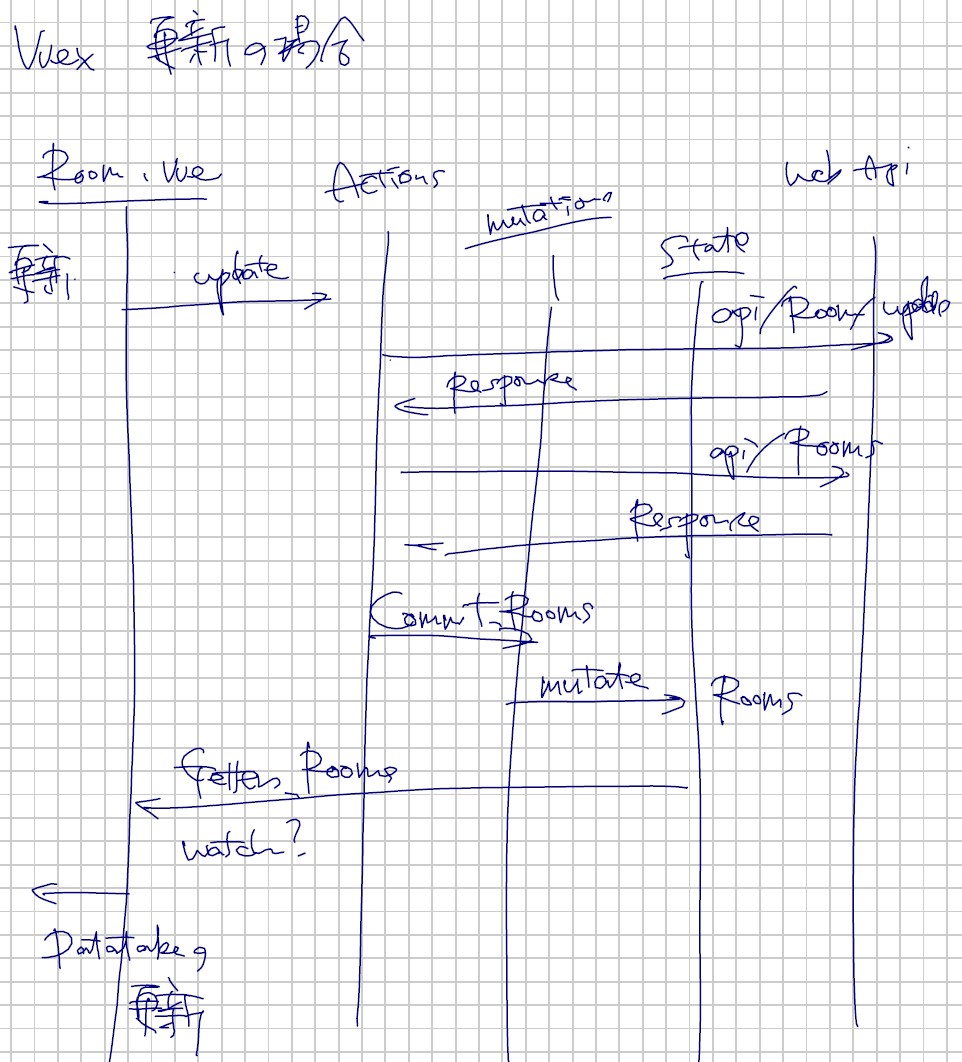
都道府県を再選択したときにグラフを再描画させます。しかし、Chart.js がデータの更新による再表示に対応していないので、ごっそりデータの中味を書き替えて更新を通知するという方式をとっています。クローンは JSON.parse(JSON.stringify(…)) で作ると安全にできます。
async getData() {
var url = process.env.VUE_APP_NHK_COVID_API_URL
console.log( url )
var res = await axios.get(url);
var { labels, datasets } = this.makeCases( res, "2020-10-01", "2021-12-31", this.value )
var { labels2, datasets2 } = this.makeCasesRt( res, "2020-10-01", "2021-12-31", this.value )
this.datax.labels = labels ;
this.datax.datasets = datasets ;
this.datart.labels = labels2 ;
this.datart.datasets = datasets2 ;
var { labels3, datasets3 } = this.makeCasesFuture( res, "2020-12-01", "2021-12-31", this.value )
this.datafu.labels = labels3 ;
this.datafu.datasets = datasets3 ;
var data = this.makeCases2( res, "2020-10-01", "2021-12-31", this.value )
this.datax2.labels = data.labels ;
this.datax2.datasets = data.datasets ;
// 再描画の代わり
this.datax = JSON.parse(JSON.stringify(this.datax));
this.datax2 = JSON.parse(JSON.stringify(this.datax2));
this.datart = JSON.parse(JSON.stringify(this.datart));
this.datafu = JSON.parse(JSON.stringify(this.datafu));
},
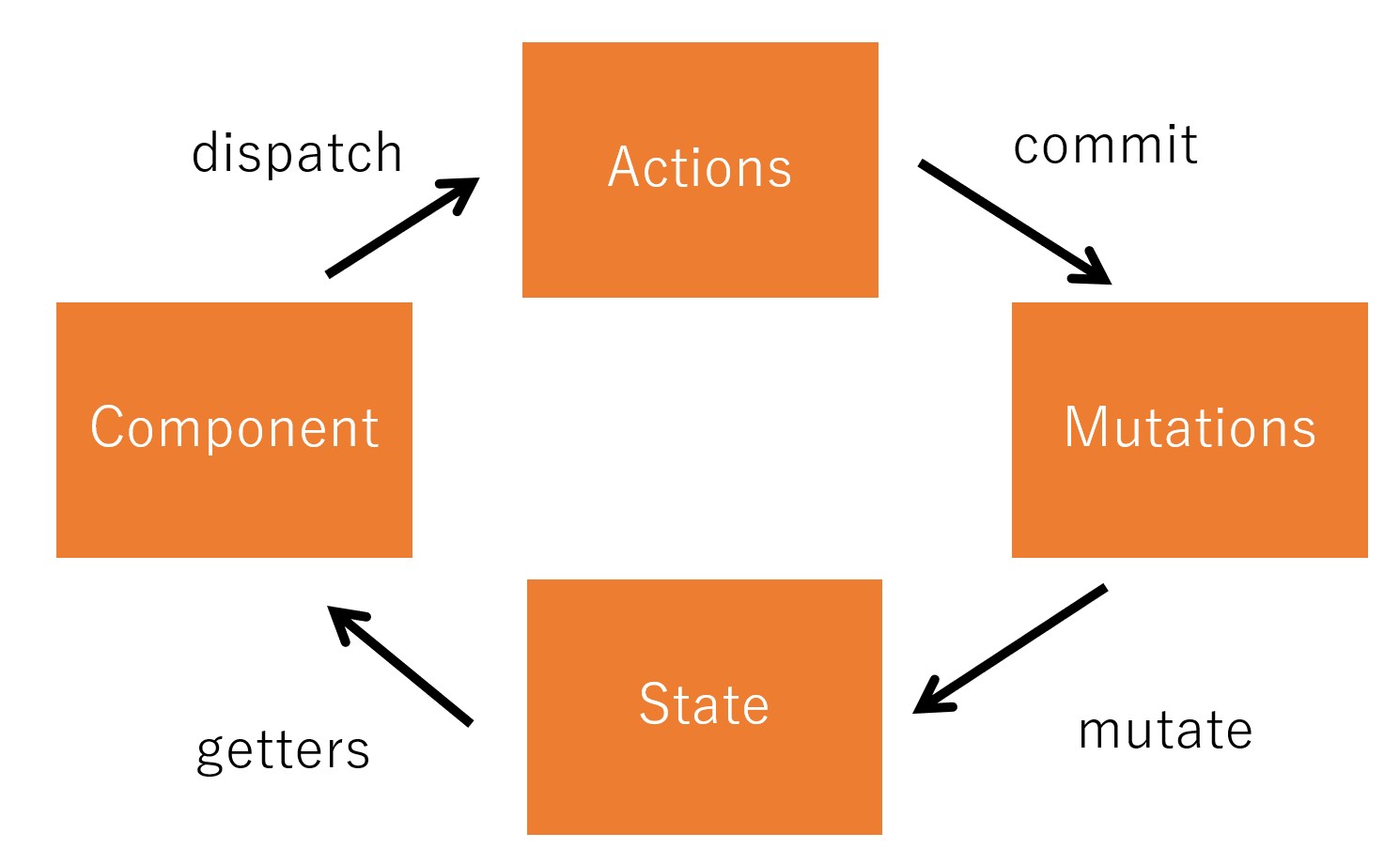
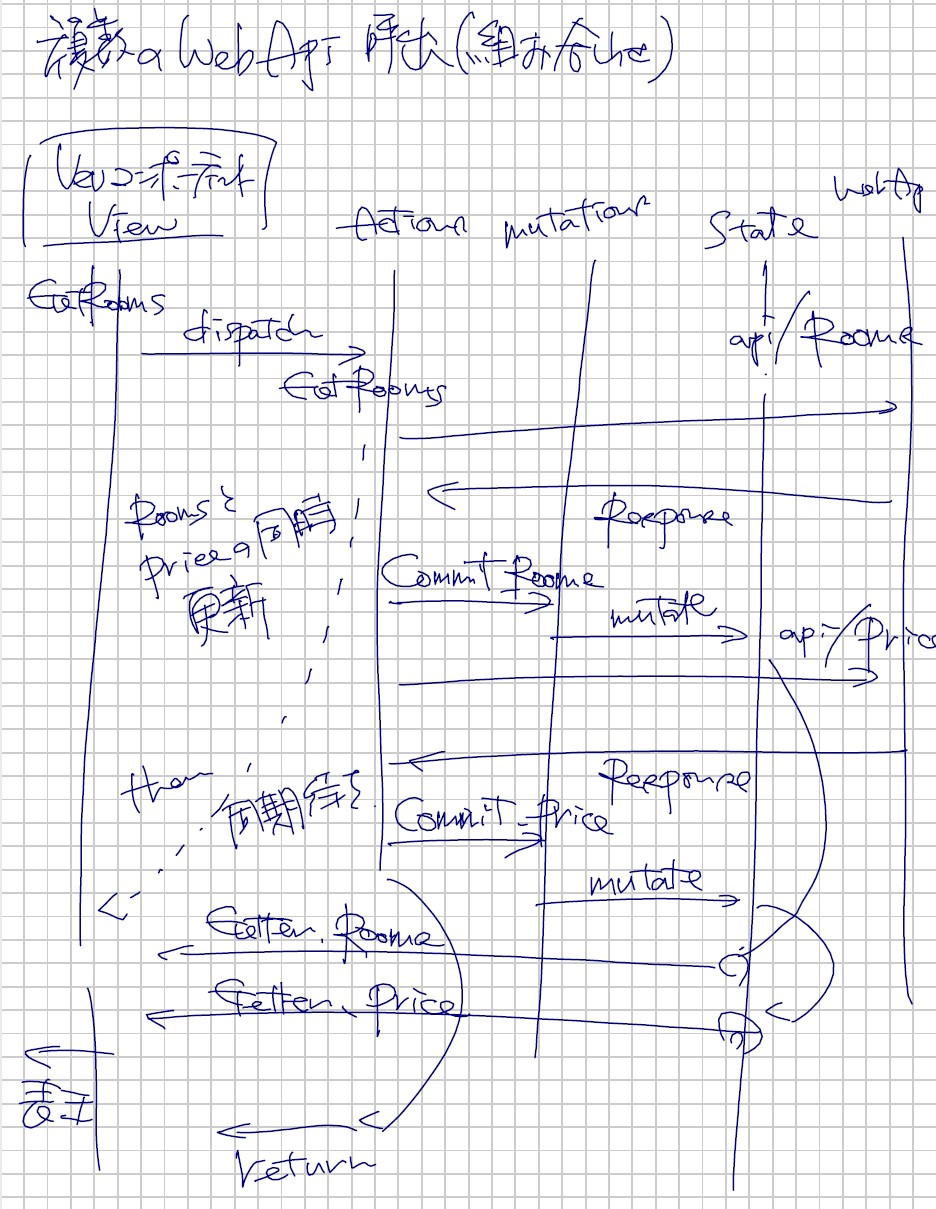
本来ならば、この this.datax まわりを Vuex の Store に詰め込めばいいのですが、これも後で変えましょう。4つのグラフが並んでいると、さすがに面倒臭いので。
予測値を計算する
予測の計算が試行錯誤がやりやすいように、JavaScript 側で計算しています。
- 感染期間を7日間として Rt を計算する
- Rt 値から週平均 Rt 値を計算する
- 週平均 Rt 値から、未来の日の陽性者数を計算する
確定した週平均 Rt 値(精度上、1週間前の値が確定値になる)を使って、前進的に予測します。
/**
* 最新の実効再生産数から今後1か月の感染者数を予測
*/
makeCasesFuture(res,start_date,end_date,locations) {
var sdate = Date.parse(start_date)
var edate = Date.parse(end_date)
var datasets = []
var labels = []
var i = 0;
console.log( edate )
locations.forEach(location => {
// 最終日を取得
var lastdate = null
var last = null
res.data.result.forEach(el => {
if ( el.location == location ) {
var dt = Date.parse( el.date )
if ( el.casesRt > 0.0 ) {
if ( lastdate < dt ) {
lastdate = dt
last = el
}
if ( sdate <= dt ) {
dt = new Date(dt)
dt = dt.getFullYear() + "/" + (dt.getMonth()+1) + "/" + dt.getDate()
if ( i == 0 ) labels.push( dt )
}
}
}
})
console.log( last );
var data = [];
var data2 = [];
// 実測値を集計
res.data.result.forEach(el => {
if ( el.location == location ) {
var dt = Date.parse( el.date )
if ( el.casesRt > 0.0 ) {
if ( sdate <= dt ) {
data.push( el.cases )
data2.push( el.casesRtAverage )
}
}
}
})
// 予測値を計算
var rt = last.casesRtAverage ;
for ( var j=1; j<=40; j++ ) {
// 過去7日間の cases と Rt から予測 cases を計算する
var len = data.length ;
var cases = (
data[ len-7 ] * data2[ len-7 ] +
data[ len-6 ] * data2[ len-6 ] +
data[ len-5 ] * data2[ len-5 ] +
data[ len-4 ] * data2[ len-4 ] +
data[ len-3 ] * data2[ len-3 ] +
data[ len-2 ] * data2[ len-2 ] +
data[ len-1 ] * data2[ len-1 ] ) / 7.0 ;
data.push( Math.floor(cases))
data2.push( rt );
var dt = new Date(Date.parse( last.date ))
dt.setDate(dt.getDate() + j);
dt = dt.getFullYear() + "/" + (dt.getMonth()+1) + "/" + dt.getDate()
if ( i == 0 ) labels.push( dt )
}
var dataset =
{
label: location,
fill: false,
borderColor: i >= this.colors.length? "rgba(200,200,200,0.5)": this.colors[i].n,
data: data,
yAxisID: "y-axis-1",
}
var dataset2 =
{
label: location + "週平均Rt",
fill: false,
borderColor: i >= this.colors.length? "rgba(100,100,100,0.5)": this.colors[i].ave,
data: data2,
yAxisID: "y-axis-2",
}
datasets.push( dataset )
datasets.push( dataset2 )
i++;
})
return { labels3: labels, datasets3: datasets };
},
実行
https://moonmile.net/nhkcovid/
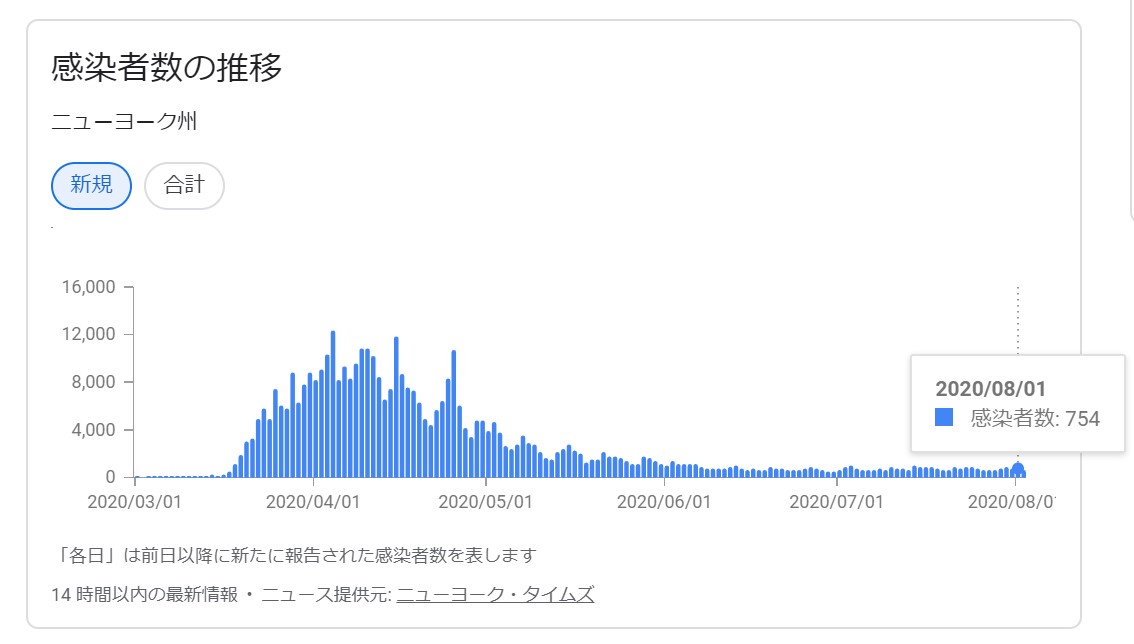
陽性者数
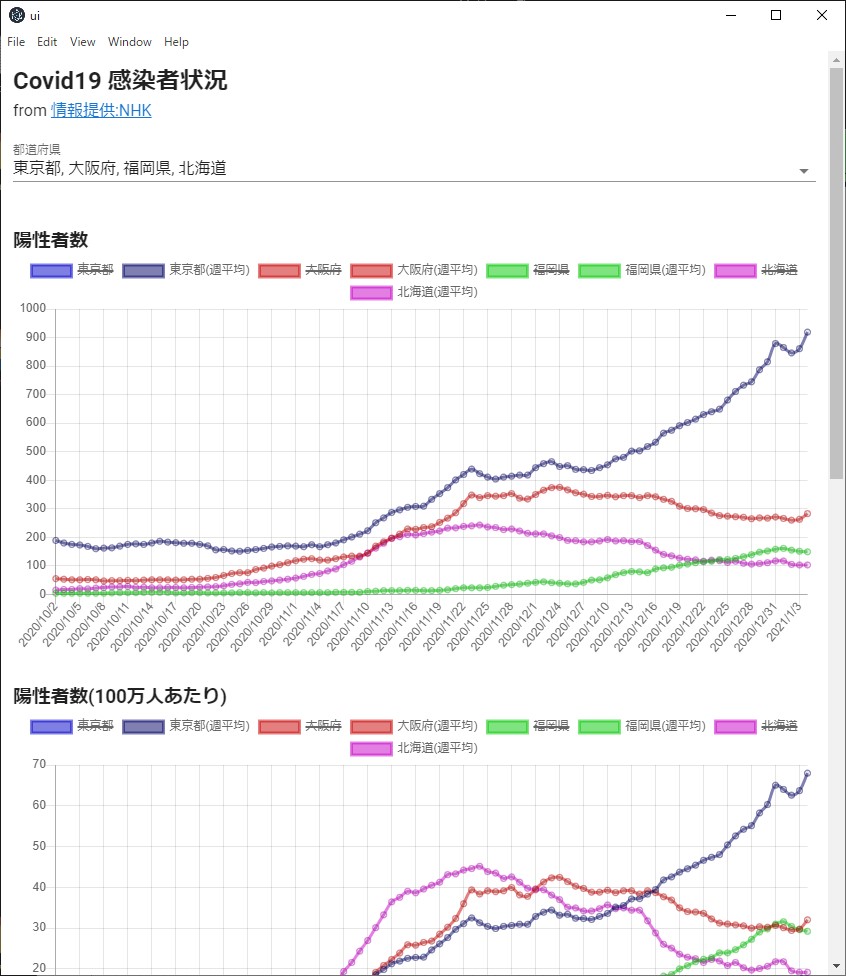
陽性者数予測